Lex/Flex词法分析工具详解及使用指南
需积分: 0 171 浏览量
更新于2024-08-05
收藏 398KB PPT 举报
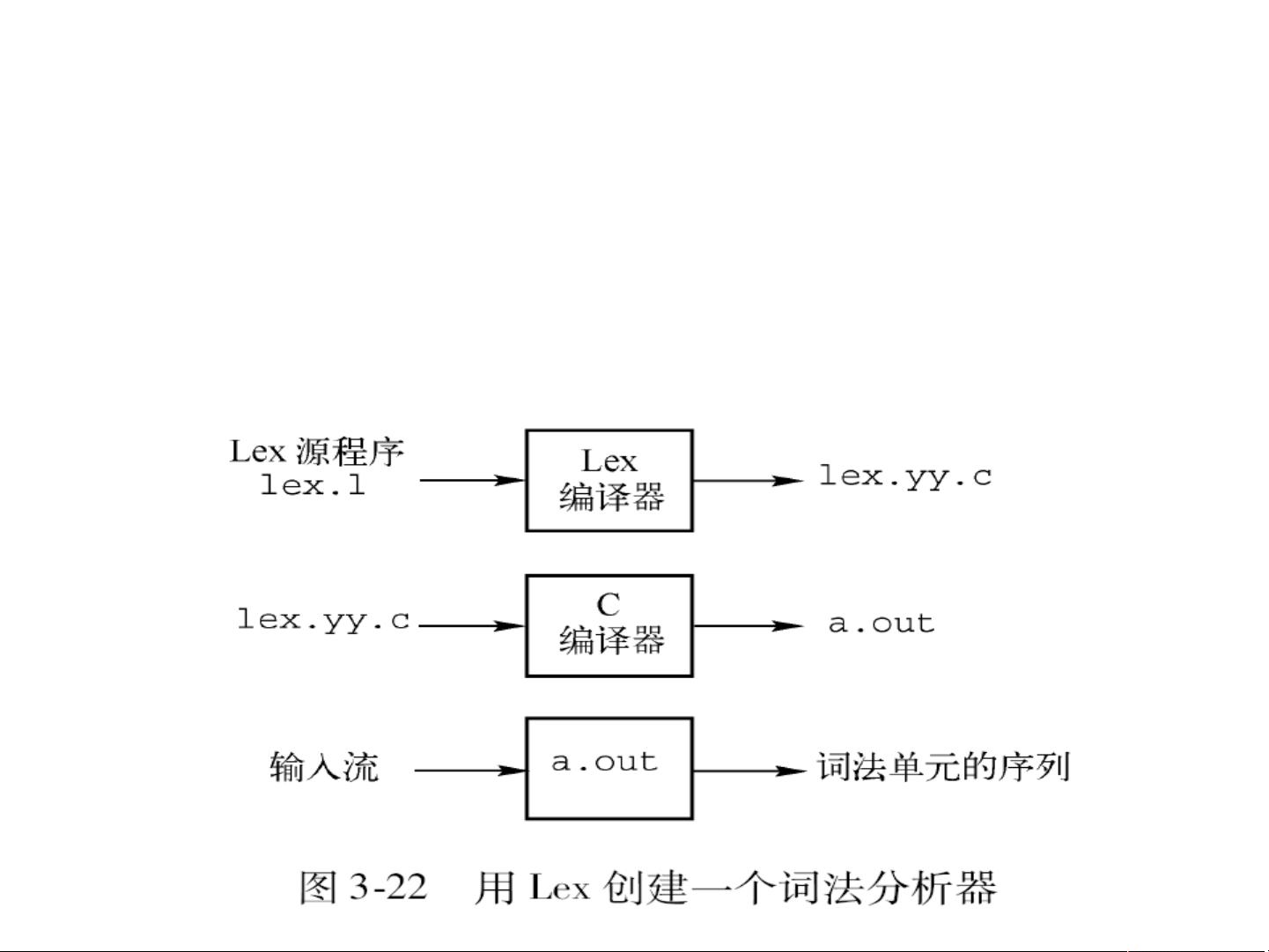
"该资源是关于词法分析工具Lex/Flex的介绍,主要适用于学习编译原理或构建解析器的人员。文件包含了Lex工具的基本概念、工作方式、源程序结构、例子以及在Ubuntu环境下如何使用Flex。此外,还提到了Lex程序中的冲突解决方法和正规式语法。\n\n词法分析工具Lex/Flex是一个广泛用于生成词法分析器的工具,它常常与Yacc配合使用,构建编译器的前端部分。词法分析器的主要任务是从源代码中识别出一个个有意义的词素,为语法分析提供基础。\n\nLex源程序由三个部分组成:声明部分、转换规则和辅助函数。声明部分包含明示常量和正则定义,转换规则由模式和对应的动作组成,模式是正则表达式,匹配到相应模式时会执行相应的动作。辅助函数则是在这些动作中使用的自定义函数。\n\n词法分析器的工作流程是逐个读取输入符号,尝试匹配最长的、与某个模式相符的输入前缀,并执行相应动作。如果动作没有返回,词法分析器将继续寻找下一个词素。\n\n以一个简单的Lex程序为例,%{和}%之间的内容会被直接复制到生成的C代码中,如注释、全局变量定义等。正则定义部分用以分隔声明和转换规则。在转换规则中,未指定返回的动作意味着继续识别后续词法单元。例如,识别到标识符和数字常量时,可能会将它们添加到标识符表和常量表中。\n\n在处理冲突时,Lex遵循最长匹配原则,即多个前缀匹配时选择最长的,同时在模式冲突时优先处理出现在前面的模式,这对于避免保留字和标识符的混淆至关重要。\n\n在Ubuntu环境下,可以使用Flex来生成词法分析器。首先,使用vi编辑器创建并编辑Lex源文件,然后运行flex命令生成C代码,接着通过cc编译生成可执行文件,最后使用这个可执行文件对输入文件进行词法分析。\n\n在正规式表达式中,不同的符号有不同的含义:A-Z, 0-9, a-z代表字母和数字;.匹配任何非换行符的字符;-用于表示范围,如A-Z代表大写字母;[]表示字符集,如[abC]匹配a、b或C;*表示匹配0个或多个前面的模式;+表示匹配1个或多个前面的模式。这些正规式符号是编写Lex源文件的基础,用于定义词法规则。\n\n掌握Lex/Flex工具对于理解编译器的构造和词法分析过程至关重要,也是软件开发中的一个重要技能。通过学习和实践,可以更好地理解和创建自己的解析工具,提升编程语言处理能力。"
词法分析工具 Lex/Flex
•
Lex/Flex 是一个有用的词法分析器生成工具
•
通常和 Yacc 一起使用,生成编译器的前端
下载后可阅读完整内容,剩余9页未读,立即下载
2015-01-22 上传
2021-10-11 上传
2009-06-05 上传
2008-11-23 上传
2009-06-23 上传
2014-06-28 上传
2013-09-29 上传

我来自1997
- 粉丝: 13
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ex_Ui登陆界面-易语言
- 行业分类-设备装置-同步提取大豆油脂和浓缩蛋白的方法.zip
- Bibtool-开源
- alware:二进制行为检查器-syscall,net-traffic等
- CrownMonolithic:使用python后端重构初始的泥潭浏览器游戏
- -PERSONS-PORTFOLIO:PERSONS PORTFOLIO
- BibSite-开源
- redux-cool:建立Redux逻辑,而不会感到紧张
- 股票查询-易语言
- .xKeep
- 行业分类-设备装置-可调式套筒和可调式棘轮套筒扳钳.zip
- emilmassey.github.io:我的个人网页
- discord-mass-ban:用户或漫游器令牌可以使用不和谐的批量禁止工具,以完全清除具有所需权限的服务器
- Dsc
- RK3566和RK3568硬件参考设计指导
- CDMLLoader:用于设计设备Mod应用程序的标记语言
