
AUTOMATIC IMAGE DATASET CONSTRUCTION WITH MULTIPLE TEXTUAL
METADATA
Yazhou Yao
1,2
, Jian Zhang
1
, Fumin Shen
3
, Xiansheng Hua
4
, Jingsong Xu
1
, Zhenmin Tang
2
1
University of Technology Sydney, Australia,
2
Nanjing University of Science and Technology, China
3
University of Electronic Science and Technology of China,
4
Alibaba Group, Hangzhou, China
{yaoyazhou, fumin.shen, huaxiansheng}@gmail.com, tzm.cs@njust.edu.cn
{jian.zhang, jingsong.xu}@uts.edu.au
ABSTRACT
The goal of this work is to automatically collect a large num-
ber of highly relevant images from the Internet for given
queries. A novel image dataset construction framework is
proposed by employing multiple textual metadata. In spe-
cific, the given queries are first expanded by searching in the
Google Books Ngrams Corpora to obtain a richer semantic
description, from which the visually non-salient and less rel-
evant expansions are then filtered. After retrieving images
from the Internet with filtered expansions, we further filter
noisy images by clustering and progressively Convolutional
Neural Networks (CNN). To verify the effectiveness of our
proposed method, we construct a dataset with 10 categories,
which is not only much larger than but also have compara-
ble cross-dataset generalization ability with manually labeled
dataset STL-10 and CIFAR-10.
Index Terms— Automatic Image Dataset Construction,
Multiple textual metadata, Clustering, Progressively CNN
1. INTRODUCTION
Labelled image datasets have played a critical role in high-
level image understanding and drive the progress of feature
designing. For example, ImageNet has acted as one of the
most important factors in the recent advance of developing
and deploying visual representation learning models (e.g.,
deep CNN). However, the process of constructing ImageNet
is both time consuming and labor intensive. It is consequently
a natural idea to leverage image search engine (e.g., Google
Image) or social network (e.g., Flickr) to construct the desired
image dataset. Generally, Google Image search engine has
a relatively higher accuracy than social network like Flickr.
However, directly constructing image dataset with retrieved
images from Google is not practical. It is mainly due to the
download restrictions for each query and the unsatisfactory
accuracy of ranking relatively rearward images. In order to
tackle this problem, we propose a novel image dataset con-
structing framework, through which a large of highly relevant
images are automatically extracted from the Internet.
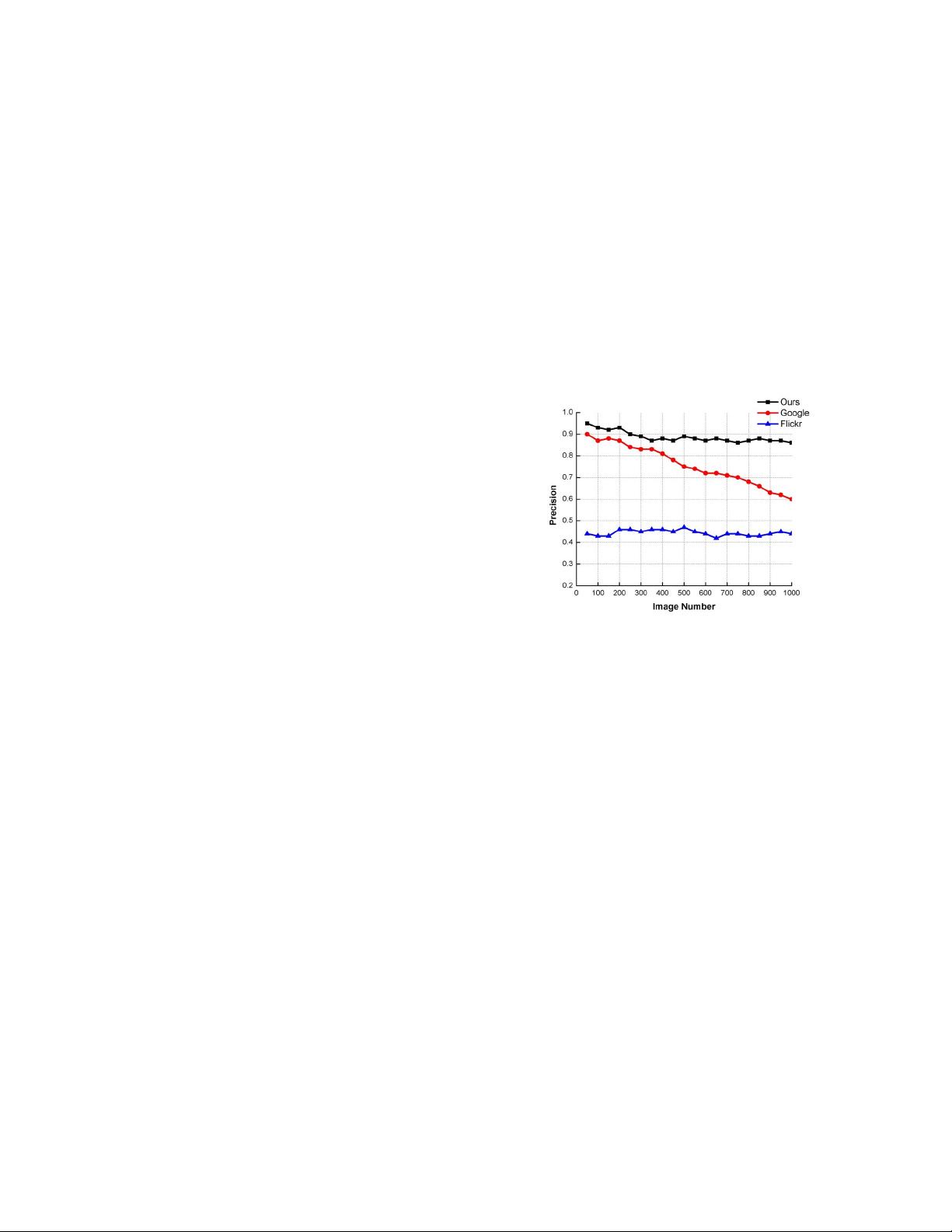
Fig. 1: The average precision of top 1000 images in Google
image, Flickr and our dataset for 10 queries.
In order to build a high-quality image dataset from Inter-
net, we propose to construct the collection for each query by
three major steps: query expanding, noisy expansions filter-
ing and noisy images filtering. Specifically, by searching in
the Google Books Ngrams Corpora (GBNC), we firstly ex-
pand the given query to a set of semantically rich expansions,
from which the noisy query expansions are then removed by
exploiting both word-word and visual-visual similarity. After
we obtain the candidate images by retrieving these filtered ex-
pansions with search engine, as an important step, clustering
and progressively CNN based methods are applied to further
remove these noisy images. To verify effectiveness of the
proposed automatic image dataset construction method, we
build a image dataset with 10 categories named AutoImgSet-
10. We evaluate its precision by comparing with methods
[1, 2, 3]. In addition, we also evaluate the cross-dataset gen-
eralization ability by comparing with two manually labeled
image datasets STL-10 and CIFAR-10. Fig.1 demonstrates
the improvement achieved by our method over the initially
downloaded images from Google and Flickr.
2. RELATED WORK
To our knowledge, there are three principal methods of con-
structing image dataset: manual annotation, semi-automatic
method and automatic method. Manual annotation has a high
下载后可阅读完整内容,剩余5页未读,立即下载

weixin_38746926
- 粉丝: 12
- 资源: 994
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


