Python爬虫利器:Requests库详解与实战
下载需积分: 0 | DOCX格式 | 299KB |
更新于2024-08-04
| 4 浏览量 | 举报
"这篇资源主要介绍了Python爬虫领域的一个重要工具——Requests库,以及它的创建者Kenneth Reitz。Requests库被赞誉为‘HTTP for Humans’,因为它的使用简便,对比其他HTTP库更加人性化。文章强调了Requests在提高开发效率方面的优势,并指出它拥有官方中文文档,便于学习和使用。此外,还提供了简单的安装和使用示例。"
在Python爬虫领域,Requests是一个不可或缺的工具,由知名Python开发者Kenneth Reitz创建。作为Heroku的前Python架构师,Reitz以其在GitHub上的活跃度和贡献闻名,他的项目Requests也因此受到了广泛的关注和使用。Requests库的核心理念是简化HTTP请求操作,使得开发者能够更专注于编写爬虫逻辑,而不是处理底层的网络通信细节。
Requests库的特性包括:
1. **易用性**:与传统的urllib相比,Requests提供了更为直观和简洁的API,使得发送HTTP请求变得极其简单。
2. **内置HTTP支持**:它支持GET、POST、PUT、DELETE等多种HTTP方法,同时还包含了文件上传、自动处理重定向、自动处理cookies等功能。
3. **响应对象**:Requests返回的响应对象提供了丰富的属性和方法,如`status_code`用于获取HTTP状态码,`encoding`用于识别响应的字符编码,`text`用于获取响应的文本内容,`json()`用于解析JSON格式的数据。
4. **强大的错误处理**:Requests库内置了异常处理机制,当请求失败时会抛出相应的异常,方便开发者进行错误排查。
5. **多语言文档**:包括官方中文文档,这极大地降低了学习和使用门槛,使得开发者可以快速上手。
安装Requests库非常方便,只需要在命令行中输入`pip install requests`即可。以下是一个简单的示例,展示了如何使用Requests发送GET请求并获取响应:
```python
import requests
# 发送GET请求
response = requests.get('http://httpbin.org/get')
# 检查HTTP状态码
print(response.status_code)
# 获取响应的字符编码
print(response.encoding)
# 输出响应的文本内容
print(response.text)
# 如果服务器返回的是JSON格式,可以直接通过response.json()获取
print(response.json())
```
Requests库的这些特点使其成为了Python爬虫开发者的首选工具,无论你是初学者还是经验丰富的开发者,都可以通过Requests轻松地构建高效的爬虫程序。因此,对于想要深入Python爬虫领域的学习者来说,掌握Requests是至关重要的。
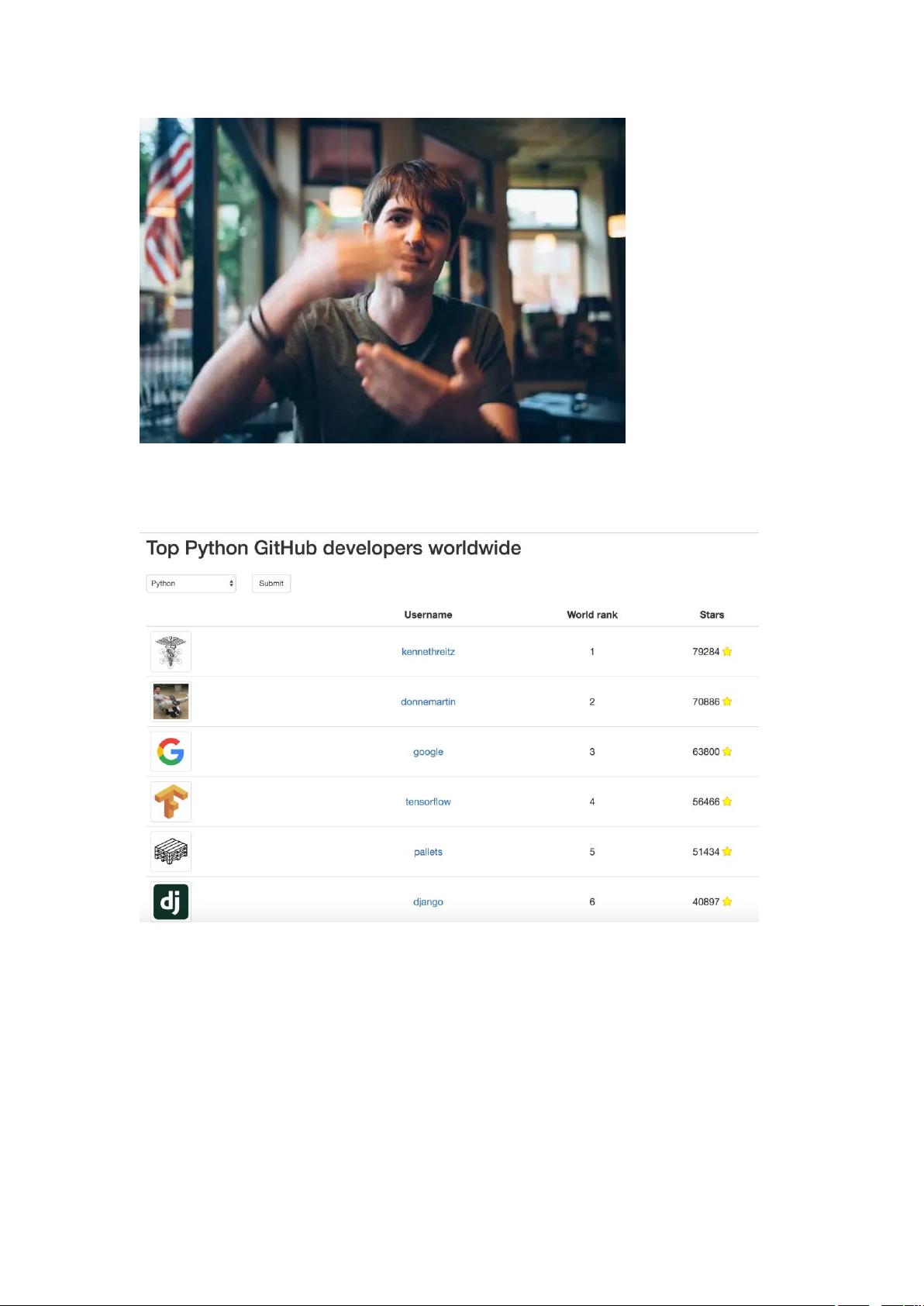
注意看,这个男人叫小帅,曾是云计算平台 Heroku 的 Python 架构师,一度是
Github 上 Python 排行榜第一的用户(stars 超过 google、tensorflow、django
等账号)。
他有一段从技术肥宅逆袭成为文艺高富帅的励志经历。
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐




龙华军
- 粉丝: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言实现LED灯控制的源码教程及使用说明
- zxingdemo实现高效条形码扫描技术解析
- Android项目实践:RecyclerView与Grid View的高效布局
- .NET分层架构的优势与实战应用
- Unity中实现百度人脸识别登录教程
- 解决ListView和ViewPager及TabHost的触摸冲突
- 轻松实现ASP购物车功能的源码及数据库下载
- 电脑刷新慢的快速解决方法
- Condor Framework: 构建高性能Node.js GRPC服务的Alpha框架
- 社交媒体图像中的抗议与暴力检测模型实现
- Android Support Library v4 安装与配置教程
- Android中文API合集——中文翻译组出品
- 暗组计算机远程管理软件V1.0 - 远程控制与管理工具
- NVIDIA GPU深度学习环境搭建全攻略
- 丰富的人物行走动画素材库
- 高效汉字拼音转换工具TinyPinYin_v2.0.3发布
