动手写网络爬虫:从URL到HTTP状态码解析
需积分: 11 190 浏览量
更新于2024-07-27
收藏 2.49MB PDF 举报
"自己动手写网络爬虫 - 全面剖析网络爬虫,了解网络爬虫基本操作,包括抓取网页和处理HTTP状态码,使用Java语言实现爬虫示例"
在计算机科学领域,网络爬虫是一种自动化程序,用于遍历互联网上的网页,收集所需信息。它们模仿人类用户的行为,抓取网页内容,为搜索引擎、数据分析或特定需求提供数据来源。在标题"自己动手写网络爬虫"中,我们将会学习如何构建自己的网络爬虫,以及如何处理抓取过程中遇到的问题。
描述中提到,爬虫的基础是抓取网页,这通常从理解URL(统一资源定位符)开始。URL是互联网上每个资源的唯一标识,它包含了访问资源的方式(如HTTP或HTTPS)、资源所在的服务器地址以及资源的具体路径。例如,`http://www.example.com/path/to/page`,其中`http`是协议,`www.example.com`是域名,`/path/to/page`是路径。
在学习网络爬虫的过程中,首先需要了解如何使用编程语言发送HTTP请求来获取网页内容。Java是一种常用的语言,可以使用HttpURLConnection或者第三方库如Apache HttpClient或OkHttp来实现这个功能。通过发送GET或POST请求,爬虫可以获取服务器返回的HTML内容。
一旦获取了网页内容,下一步通常是解析HTML以提取所需信息。这可能涉及DOM解析、正则表达式匹配或使用像Jsoup这样的库来解析和操作HTML文档。在实际应用中,抓取过程可能会遇到各种问题,例如服务器返回的HTTP状态码,这些状态码提供了关于请求结果的状态信息。常见的状态码如200表示成功,404表示未找到页面,500表示服务器错误。正确处理这些状态码是爬虫健壮性的重要组成部分。
网络爬虫需要遵循robots.txt文件的规则,这是网站所有者用来指示爬虫哪些页面可以抓取,哪些不能。此外,尊重网站的抓取频率限制和避免过于频繁的请求也是避免被封IP的重要策略。
在实际项目中,网络爬虫可能会涉及分布式系统、反反爬虫策略、数据存储和清洗等多个方面。例如,大型爬虫项目可能会使用Scrapy这样的框架来提高效率和管理复杂性。而数据抓取后,可能需要进行NLP(自然语言处理)或数据分析,以提取有价值的洞察。
网络爬虫是连接互联网信息与分析应用的关键技术。通过学习和实践,我们可以构建自己的爬虫系统,无论是为了搜索引擎优化、市场研究还是其他目的,都能有效地获取和利用网络上的数据。
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
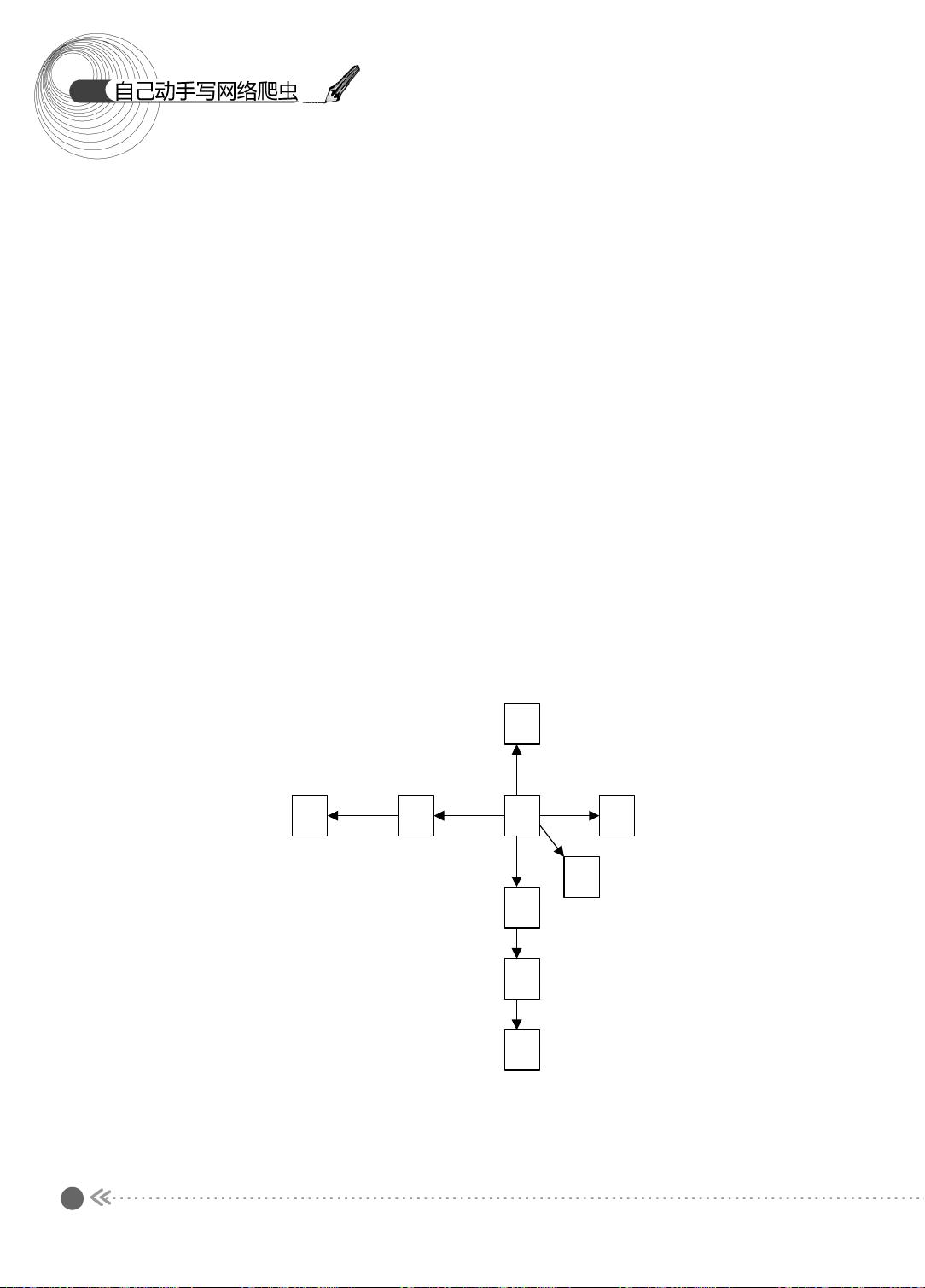
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
2015-11-05 上传
2016-12-13 上传
499 浏览量
2023-05-30 上传
2023-09-18 上传
2024-02-05 上传
2023-06-23 上传
2024-08-31 上传
2024-03-20 上传

xuelijack
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
