NVIDIA CUDA编程深度解析:GPU计算新架构与API指南
需积分: 13 70 浏览量
更新于2024-07-24
收藏 6.36MB PDF 举报
NVIDIA CUDA编程指南是一份详细的文档,针对NVIDIA图形处理器单元(GPU)作为并行数据计算设备的新架构CUDA进行深入介绍。该指南主要分为四个章节:
1. **介绍CUDA**:这一章阐述了GPU如何从传统的图形处理转变为一个多线程并行计算平台。1.1节解释了GPU作为并行计算设备的角色,强调了它在处理大量并行任务的优势。1.2节则详细介绍了CUDA架构,其目的是让开发者能够在GPU上高效地编写并行代码。
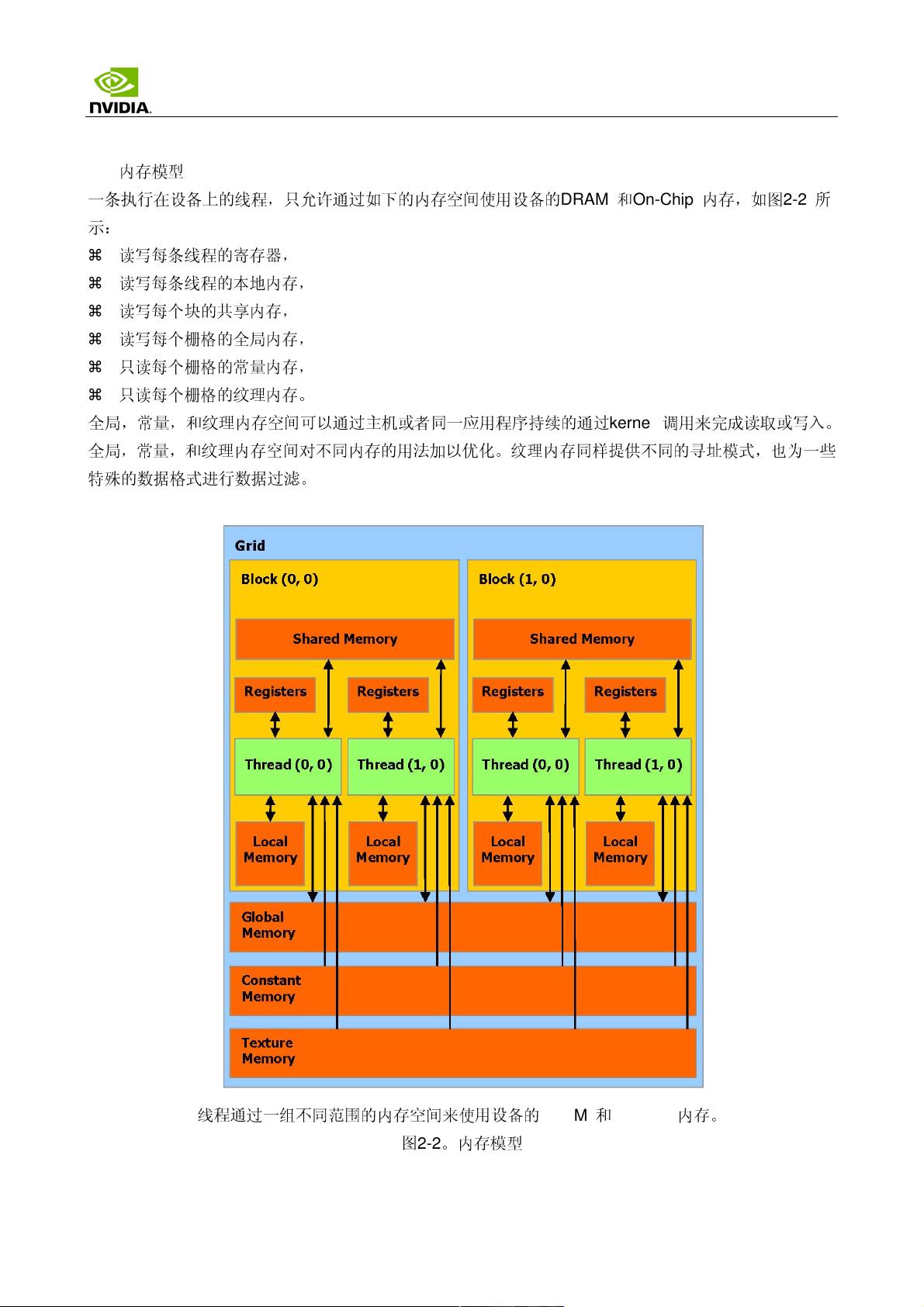
2. **编程模型**:这一部分深入探讨了CUDA的编程模型。2.1介绍了CUDA的超多线程协处理器,它支持大规模并行计算。2.2线程批处理涉及到线程块的概念,包括线程块的定义(16x16的基本单位)和线程块栅格化,用于组织和调度计算任务。内存模型则是编程的关键,确保数据在GPU内存之间的正确访问和同步。
3. **硬件实现**:这部分涵盖了CUDA硬件的具体细节,如SIMD多处理器、执行模式、计算兼容性和多设备支持。此外,还有对模式切换和内部硬件组件的介绍,如共享内存、执行配置选项以及CUDA编译器的特性,如`__noinline__`和`#pragma unroll`等。
4. **应用程序编程接口(API)**:这是核心部分,介绍了CUDA编程的关键元素。4.1介绍了CUDA的C语言扩展,允许开发者利用GPU资源。4.2详细解释了各种函数和变量类型的限定词,如`__device__`、`__global__`等,它们决定了代码的运行位置。此外,还讨论了gridDim、blockIdx、blockDim等内置变量,用于指定程序在GPU上的执行配置。NVCC编译器的其他选项也在此部分提及,如优化指令序列和内联函数。
NVIDIA CUDA编程指南提供了全面的指导,旨在帮助开发者理解CUDA架构,掌握如何设计、编写和优化GPU加速的并行计算程序,充分利用NVIDIA GPU的性能优势。通过深入理解这些概念和技术,开发者可以创建出高效的高性能计算应用。

- 16 -
2.2.1
线程块
一个线程块是一个线程的批处理,它通过一
些快速
的共享内存有
效
地
分
享数据并
且
在制定的内存
访问中
同
步它
们
的执行。更准确地说,它可以在
Kernel
中
指定同步点,一个块
里
的线程被
挂起直
到它
们
所有都到
达
同步点。
每
条
线程是由它的线程
ID
所确定,
ID
是在块
之
内的线程编号。
根
据线程的
ID
可以
帮助
进行
复杂寻址
,
一个应用程序可以指定一个块作为一个
二维
或
三维
数组的任
意大小
,并
且
通过一个
2 -
或
3-
组件
索引
代
替来
指定每
条
线程。对于一个
大小
为
(
D
x
,
D
y
)
二维
块,线程的
索引
是
(
x
,
y
)
,这个线程
ID
是
(
x
+
y D
x
)
。而对于
一个
三维
的
大小
为
(
D
x
,
D
y
,
D
z
)
的块,这个线程的
索引
是
(
x
,
y
,
z
)
, 线程的
ID
是
(
x
+
y D
x
+
z D
x
D
y
)
。
2.2.2
线程块栅格
一个块可以
包含
的线程
最大
数量是有限的。
然
而,执行同一个
kernel
的块可以
合
成一批线程块的栅格,因
此通过单一
kernel
发
送
的
请求
的线程总数可以是非常
巨大
的。线程协作的
减少会造
成性能的
损失
,因为
来
自
同一个栅格的不同线程块
中
的线程
彼
此
之
不间能通
讯
和同步。这个模式
允许
kernel
用不同的并行能
力
有
效
地运行在
各种
设备上而不用
再
编译:一个设备可以序列地运行栅格的所有块,如
果
它有非常
少
的并行
特
性,或
者
并行地运行,如
果
它有
很
多的并行的
特
性,或
者
通常是
二者
的组
合
。
ٛ
.
每个块是由它的块ID 确定的,块的ID 是在栅格之内的块编号。根据块ID 可以帮助进行
复杂寻址,一个应用程序可也以指定一个栅格作为任意大小的一个二维数组,并且通过一个
2-组件索引替换来制定每个块。对于一个大小为 (
D
x
,
D
y
)
二维
块,这个块的索引是(
x
,
y
),
块的
ID 是(
x
+
y D
x
)
。



剩余135页未读,继续阅读
2011-01-14 上传
2015-12-23 上传
2022-09-24 上传
2022-09-14 上传
2010-09-30 上传
2010-02-02 上传
2021-09-29 上传

注册成功啊
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
