快速掌握ML神器:sklearn实战指南
PDF格式 | 431KB |
更新于2024-09-02
| 187 浏览量 | 举报
"这篇教程主要关注的是机器学习库scikit-learn(简称sklearn)的快速使用和入门,适合初学者进行学习和实践。文章通过详细的示例代码,讲解了从数据获取到模型构建和评估的整个流程。"
在机器学习领域,scikit-learn(sklearn)是一个强大的工具,它提供了丰富的算法和实用功能,便于进行数据预处理、模型选择、训练和评估。本教程将按照机器学习的一般流程,即获取数据、数据预处理、训练建模、模型评估和预测,来介绍sklearn的基本使用。
1. 获取数据
sklearn库内置了一些经典的数据集,如iris(鸢尾花)数据集,用于演示和学习。要使用这些数据集,首先要导入`datasets`模块:
```python
from sklearn import datasets
```
例如,加载鸢尾花数据集:
```python
iris = datasets.load_iris()
X = iris.data # 特征向量
y = iris.target # 样本标签
```
此外,如果你需要创建自己的数据集,sklearn提供了一些生成器,如`make_classification`,可用于生成分类问题的样本数据:
```python
from sklearn.datasets.samples_generator import make_classification
X, y = make_classification(n_samples=6, n_features=5, n_informative=2,
n_redundant=2, n_classes=2, n_clusters_per_class=2,
scale=1.0, random_state=20)
```
这里的参数如`n_samples`表示样本数量,`n_features`表示特征数量,`n_classes`表示类别数量,`random_state`则用于控制随机数生成的可重复性。
2. 数据预处理
数据预处理是机器学习中的关键步骤,包括数据清洗、标准化、归一化等。sklearn提供了多种预处理工具,如`StandardScaler`进行标准差标准化,`MinMaxScaler`进行区间缩放:
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
minmax_scaler = MinMaxScaler()
X_minmax = minmax_scaler.fit_transform(X)
```
3. 训练建模
sklearn包含各种监督学习算法,如线性回归、逻辑回归、SVM、决策树、随机森林等。以逻辑回归为例:
```python
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=0)
clf.fit(X_train, y_train) # 训练模型
```
4. 模型评估
模型训练后,我们需要评估其性能。sklearn提供了多种评估指标,如准确率、召回率、F1分数等。以准确率为例:
```python
from sklearn.metrics import accuracy_score
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
```
5. 预测
训练好的模型可用于新数据的预测:
```python
new_data = [[5.1, 3.5, 1.4, 0.2]] # 新样本
prediction = clf.predict(new_data)
print("Predicted class:", prediction[0])
```
sklearn以其简洁的API和丰富的功能,使得机器学习变得更为易用。通过这篇教程,你可以快速上手并开始实践机器学习项目。记住,理论知识与实践相结合,才能更好地掌握机器学习。祝你在学习之路上取得更大的进步!
ML神器:神器:sklearn的快速使用及入门的快速使用及入门
主要介绍了ML神器:sklearn的快速使用及入门,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起
学习学习吧
传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类。本文我们将依据传统机器学习的流程,看看在每一步流程中都有哪些常用的
函数以及它们的用法是怎么样的。希望你看完这篇文章可以最为快速的开始你的学习任务。
1. 获取数据获取数据
1.1 导入导入sklearn数据集数据集
sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论知识的
理解和把握。(这一步我也亟需加强,一起加油!^-^)
首先呢,要想使用sklearn中的数据集,必须导入datasets模块:
from sklearn import datasets
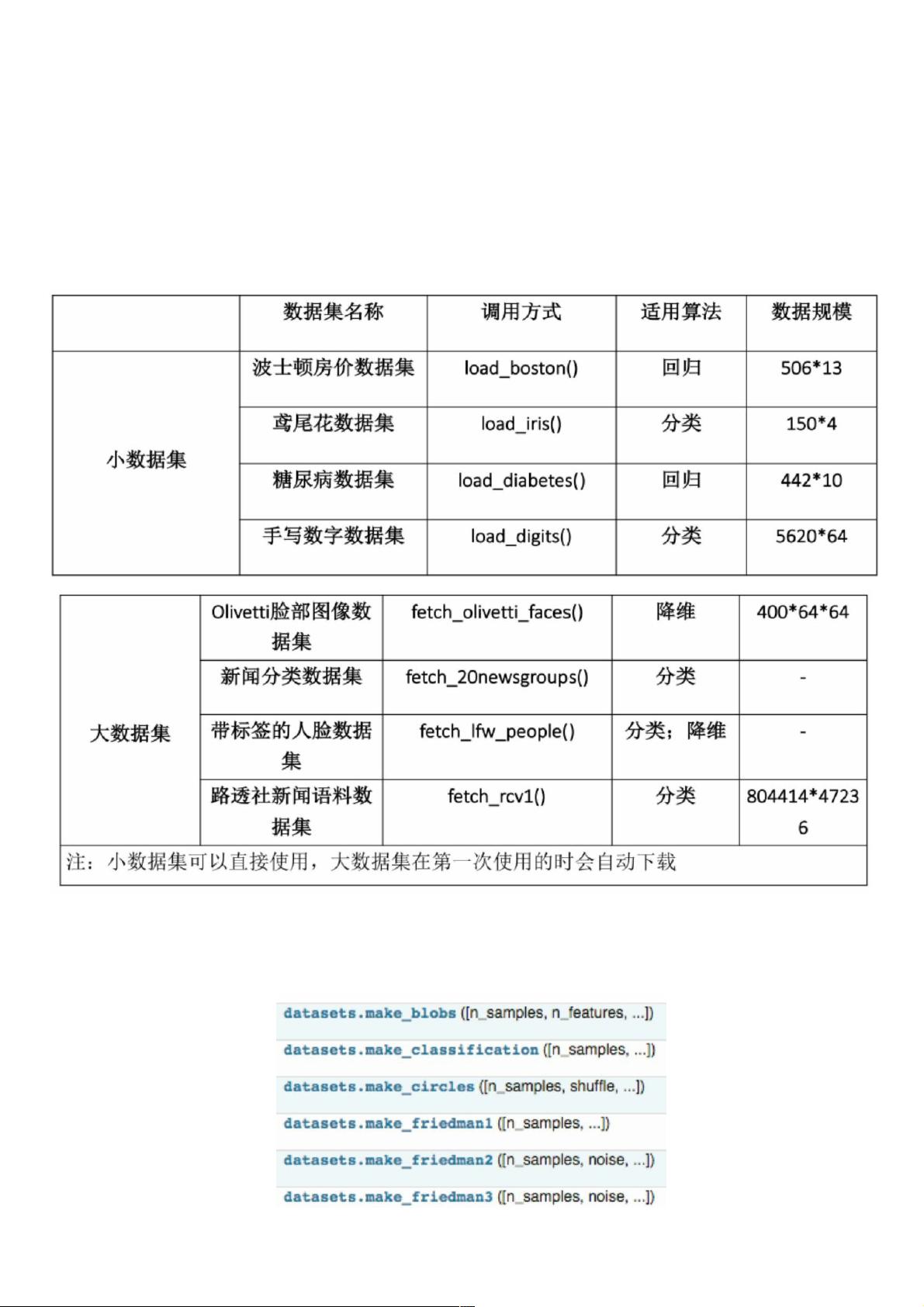
下图中包含了大部分sklearn中数据集,调用方式也在图中给出,这里我们拿iris的数据来举个例子:
iris = datasets.load_iris() # 导入数据集
X = iris.data # 获得其特征向量
y = iris.target # 获得样本label
1.2 创建数据集
你除了可以使用sklearn自带的数据集,还可以自己去创建训练样本,具体用法参见《Dataset loading utilities》,这里我们简单介绍一些,sklearn中的samples generator包含的大量创建样本数
据的方法:
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐





weixin_38688969
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Rusty-iconz: Rust编写的Xcode图标生成CLI
- flyspell-lazy:提升Emacs flyspell性能的新方法
- 网格布局实例讲解与应用分析
- 使用amcharts.js创建多图表统计Demo
- SublimeLinter-pep8插件解析:Python代码质量检查
- Aristotle: 构建个性化新闻采集系统的Python工具
- Inmanta参数配置模块(param)的介绍与应用
- 掌握Android SimpleAdapter在GridView和ListView中的应用
- 深入了解mysql innodb表空间分析工具py_innodb_page_info
- 自定义checkboxpreference样式教程
- 轻松获取宽带连接密码的小工具
- Wamp5 1.7.4:PHP、MySQL与Apache集成环境安装
- HyperVM虚拟化管理器功能与OpenVZ及Xen集成
- Android与Struts2结合实现图片文件上传教程
- Node.JS中的CrudStudents:CRUD操作实践指南
- HTML5与CSS3离线CHM文档资源包
