Oracle数据库:索引与表分区详解
需积分: 12 138 浏览量
更新于2024-07-28
收藏 1.45MB PPT 举报
"Oracle数据库中的索引和表分区技术是提高数据访问效率的重要手段。索引可以加速数据查找,尤其在大型表中,而表分区则能够优化数据管理和查询性能。"
在Oracle数据库中,索引是一种特殊的数据库对象,用于加速对表中数据的查找。普通表的数据通常是按照堆组织的,如果没有索引,查找特定记录就需要进行全表扫描,这在数据量庞大的时候非常低效。索引的存在使得Oracle能够快速定位到所需数据,但同时也会在插入、删除和更新操作时增加开销,因为索引也需要同步维护。
Oracle提供了多种类型的索引,包括B树索引、B树聚集索引、Hash聚集索引、反向键值索引、位图索引以及位图联结索引。其中,B树索引是最常见的一种,适用于大多数情况,它保证了数据查找的平均时间性能。B树索引分为惟一索引和非惟一索引,前者确保索引列的唯一性,后者则允许重复值。此外,还可以创建多列复合索引,即在多个列上建立索引,以满足更复杂的查询需求。
创建索引的基本语法如下:
```sql
CREATE INDEX index_name ON table_name(column_name);
```
如果需要创建唯一索引,可以使用`UNIQUE`关键字:
```sql
CREATE UNIQUE INDEX index_name ON table_name(column_name);
```
对于组合索引,可以在多个列上创建:
```sql
CREATE INDEX index_name ON table_name(column_name1, column_name2);
```
索引的维护包括重建和删除。重建索引可以优化索引结构,而删除索引则需要注意可能对查询性能的影响。
表分区是另一种提升性能的技术,尤其是对大型表来说。通过将大表分割成逻辑上相关的小块(分区),可以实现更高效的查询和管理。例如,可以根据日期、地区或其他业务相关的字段进行分区。分区可以显著减少需要扫描的数据量,从而加速查询。
创建分区的基本语法如下:
```sql
CREATE TABLE table_name
(PARTITION BY RANGE (column_name)
(PARTITION partition_name VALUES LESS THAN (value))
...
);
```
或者使用其他类型的分区策略,如列表分区、哈希分区等。
Oracle索引和表分区是数据库性能优化的关键技术。正确地创建和使用索引以及设计合理的分区策略,能够显著提高数据访问速度,降低系统资源消耗,提升整体的数据库性能。在实际应用中,需要根据业务需求和数据特性来选择合适的索引类型和分区策略。
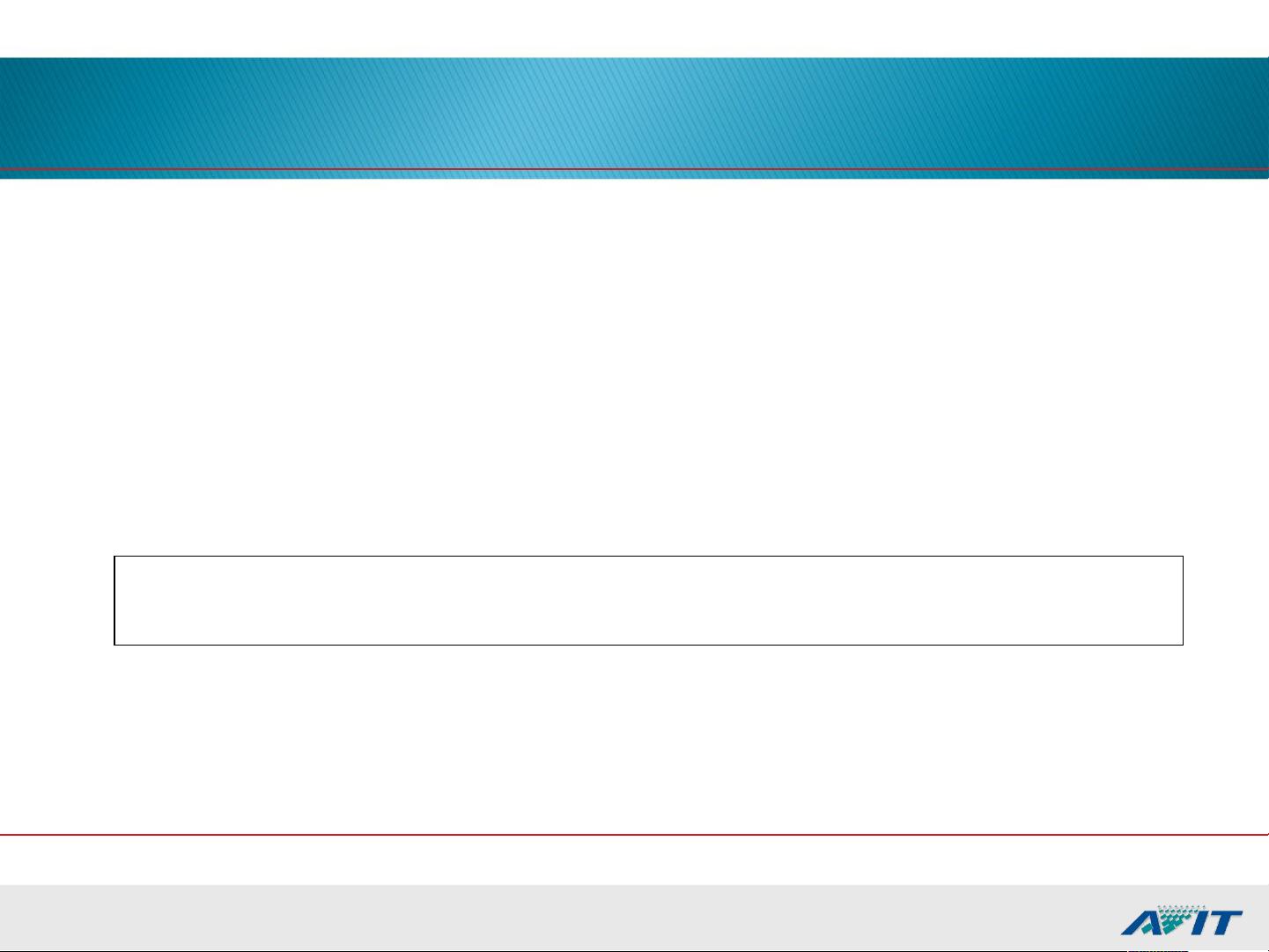
B 树索引 - 唯一索引
SQL> CREATE UNIQUE INDEX dept_index
ON dept (dname);
唯一索引确保在定义索引的列中没有重复值
Oracle 自动在表的主键列上创建唯一索引
使用 CREATE UNIQUE INDEX 语句创建唯一索引
剩余40页未读,继续阅读
540 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
1398 浏览量
1204 浏览量
975 浏览量

无忌123
- 粉丝: 0
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- C.-elegans-Benzimidazole-Resistance-Manuscript:此回购包含与此手稿相关的所有数据,脚本和输出(图和表)
- -研究-Mmobile-ReactNative-
- Frontend-mentor---TestimonialgridsChallenge.io
- AVG_Remover_en.exe
- Python和Pandas对事件数据的处理:以电动汽车充电数据为例
- 酒店综合办管理实务
- matlab开发-mthorderPiechesSplineInterpolation
- 计价器(完整-霍尔.zip
- DesignPatterns:Java设计模式
- Authorization:基于Microsoft Identity和JWT的授权项目解决方案,使用NuGet软件包和npm软件包进行连接
- Voodoo-Mock:用于C ++的模拟对象自动代码生成器(与python等效)
- study-go-train-camp:golang训练营学习
- 风险投资如何评价创业型公司
- MyBrowser-含有收藏夹.rar
- 基于Python的GUI库Tkinter实现的随机点名工具/抽奖工具可执行文件.exe
- 状态标签-显示进度
