Cassandra一致性详解:2019云栖大会实操与应用场景
需积分: 19 148 浏览量
更新于2024-07-15
收藏 1.22MB PDF 举报
在2019年的云栖大会上,Cassandra一致性详解深入探讨了这个分布式NoSQL数据库在处理高可用性和一致性之间的复杂平衡。首先,会议强调了CAP定理对Cassandra设计的影响,即Cassandra被定位为一个分布式系统,倾向于可用性(A)而非强一致性(C)。CAP理论指出,在分布式系统中,不能同时满足一致性、可用性和分区容错性,通常会在这三者之间做出折衷。
Cassandra作为AP系统的代表,其核心优势在于:
1. **持续在线**:无论何时,数据总是可以访问,保证了高可用性。
2. **易用性**:提供了简洁的类SQL语法,方便开发人员操作。
3. **多语言支持**:客户端兼容多种编程语言,便于跨平台应用。
4. **高性能**:采用垂直架构设计,性能表现出色。
5. **可扩展性**:设计灵活,能轻松地水平扩展应对大数据量。
6. **一致性控制**:允许用户调整读写一致性级别,满足不同场景需求。
7. **部署简便**:简化了部署流程。
8. **海量存储**:支持存储海量数据。
在一致性实现方面,Cassandra提供了一定程度的自定义选项。例如,用户可以通过设置replication_factor来指定数据复制的数量,常见的读写一致性级别包括:
- **ONE**:读写要求至少有一个副本成功响应。
- **TWO**:要求至少两个副本成功响应。
- **QUORUM**:读写需要超过半数副本成功响应,这是默认和最安全的选择。
- **SERIAL**:串行化写入,牺牲性能以确保强一致性。
值得注意的是,Cassandra在大多数情况下能够保证较强的一致性,但在极端情况下,为了确保服务的可用性,可能会牺牲部分一致性。这种设计策略使得Cassandra适合那些对数据最终一致性要求不高,但需要高度可扩展性和高可用性的场景。
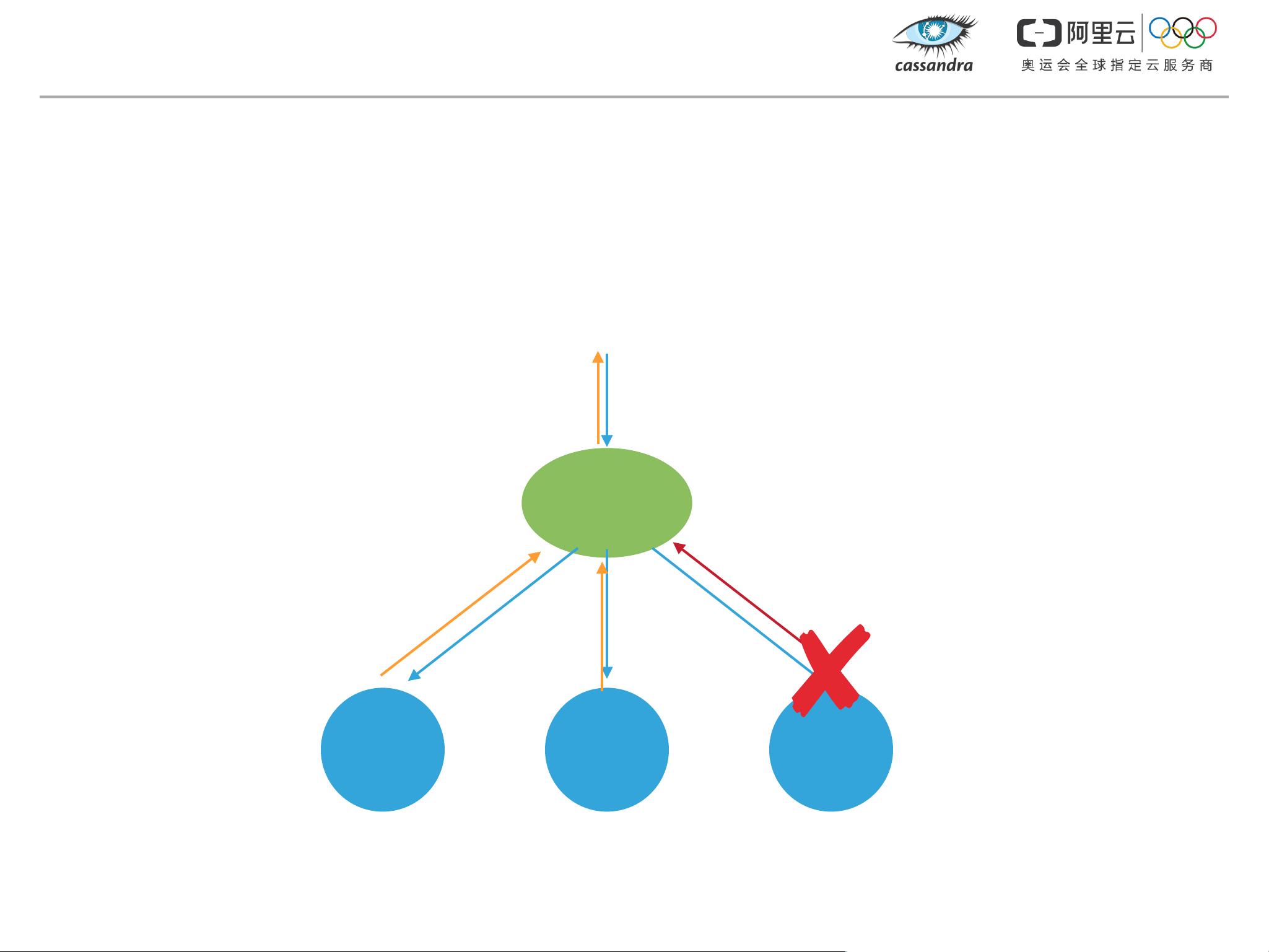
协调器(Coordinator)机制在Cassandra中扮演关键角色,它确保节点间的协作以及在节点故障时的恢复。即使在并发读写和节点故障的情况下,去中心化的架构也能保持服务的正常运行。
Cassandra通过灵活调整一致性模型和利用分布式特性,为用户提供了一种在大规模数据处理和高可用性之间取得平衡的解决方案,适用于大数据和互联网服务中的实时查询和分析场景。

1.1
CASSANDRA优势
总是保持在线
简洁上的类SQL语法
多语客户端持
垂直架构性能强劲
灵活的平扩展
可调节读写致性级别
部署常简单
数据存储
剩余25页未读,继续阅读
2019-10-13 上传
2019-09-13 上传
2020-08-05 上传
2019-10-05 上传
2020-08-05 上传
2020-05-26 上传
2020-05-26 上传

青山见我_
- 粉丝: 0
- 资源: 29
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
