Apache Spark与Delta Lake数据工程师实战指南
需积分: 9 163 浏览量
更新于2024-07-15
收藏 6.24MB PDF 举报
"Apache Spark Delta Lake Data Engineer Guide"
在当今数据密集型的世界中,Apache Spark 和 Delta Lake 已成为构建高效、可靠的数据湖解决方案的关键工具。Apache Spark 是一个流行的开源大数据处理框架,它提供了高性能的分布式计算能力。而 Delta Lake 是建立在存储层之上的开放源代码项目,它为现有的数据湖存储(如 AWS S3、Azure Data Lake Storage 或 HDFS)增加了可信赖性、性能和生命周期管理。
本指南主要分为以下几个章节:
1. **Apache Spark 的温和介绍**:
在这一章中,作者将带领读者了解 Apache Spark 的基础知识。Apache Spark 以其快速的内存计算和对多种数据处理任务的支持而闻名,包括批处理、流处理和机器学习。它通过 Spark Core 提供基础架构,Spark SQL 支持结构化查询,Spark Streaming 处理实时数据流,MLlib 用于机器学习,以及 GraphX 处理图数据。此外,Spark 应用程序通常通过 Spark Application 模型运行,该模型由一个驱动程序和多个工作节点组成。
2. **Spark 工具集漫游**:
这一章将深入探讨 Spark 的各种组件和工具,包括 Spark Shell 用于交互式数据分析,Spark Submit 用于部署应用程序,以及 Spark UI 和 History Server 用于监控和调试作业。同时,还会讨论如何配置和优化 Spark 集群以提高性能。
3. **处理不同类型的数据显示**:
本章将详细讲解如何使用 Spark 处理不同类型的数据,包括结构化、半结构化和非结构化数据。Spark DataFrame 和 Dataset API 提供了一种统一的方式来操作这些数据,同时支持 SQL 查询,使得数据工程师可以更轻松地进行数据转换和分析。
4. **Delta Lake 快速入门**:
这一部分专门介绍 Delta Lake,它是构建高可用、事务安全的数据湖的关键。Delta Lake 提供了 ACID 事务、版本控制、元数据管理和自动垃圾回收等特性,确保数据的一致性和完整性。通过 Delta Lake,可以在大数据场景下实现类似数据库的可靠性和性能,同时利用现有云存储的低成本。
Apache Spark 与 Delta Lake 的结合,使得数据工程师能够处理大规模数据并确保数据的准确性和一致性。这种组合特别适合实时分析、ETL(提取、转换、加载)流程和数据仓库应用。随着 Spark 兼容 Delta Lake,数据工程师现在可以在一个统一的平台上进行数据处理和存储,简化了数据湖的管理和开发流程。通过深入学习本指南,数据工程师可以充分利用这两个工具的优势,构建出强大的数据处理和分析系统。
DATA ENGINEERS GUIDE TO
APACHE SPARK AND DELTA LAKE
16
Now, just like we did before, we can specify an action in order to kick off this plan.
However before doing that, we’re going to set a configuration. By default, when we
perform a shue Spark will output two hundred shue partitions. We will set this
value to five in order to reduce the number of the output partitions from the shue
from two hundred to five.
spark.conf.set(“spark.sql.shule.partitions”, “5”)
ightData2015.sort(“count”).take(2)
... Array([United States,Singapore,1], [Moldova,United States,1])
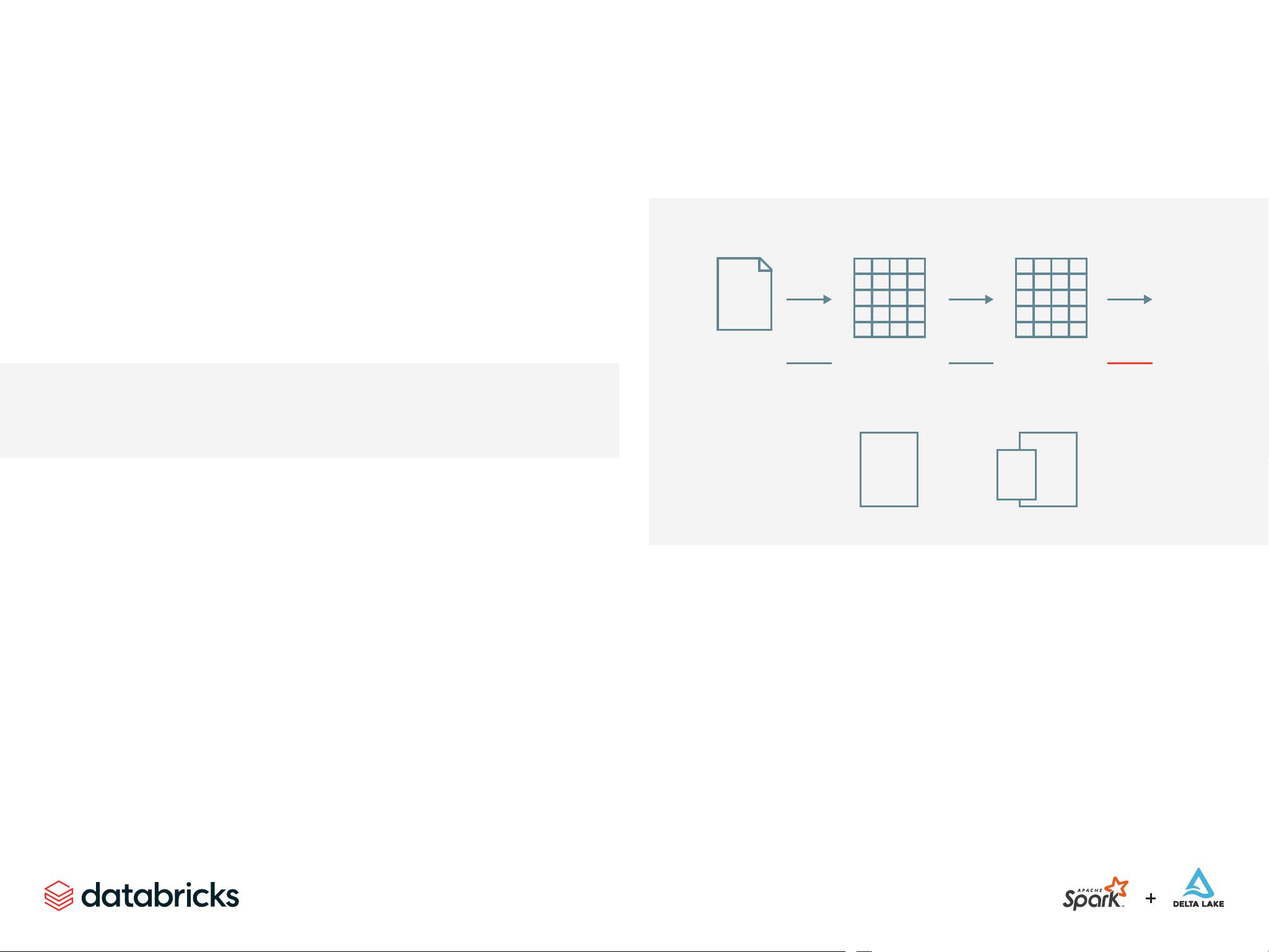
This operation is illustrated in the following image. You’ll notice that in addition to the
logical transformations, we include the physical partition count as well.
CSV FILE
Read
(Narrow) (Wide)
DATAFRAME DATAFRAME
Sort
(Wide)
take(3)
Array(...)
1 PARTITION 5 PARTITIONS
The logical plan of transformations that we build up defines a lineage for the DataFrame so that at any given point in time Spark knows how to recompute any partition by per-
forming all of the operations it had before on the same input data. This sits at the heart of Spark’s programming model, functional programming where the same inputs always
result in the same outputs when the transformations on that data stay constant.
We do not manipulate the physical data, but rather configure physical execution characteristics through things like the shue partitions parameter we set above. We got five
output partitions because that’s what we changed the shue partition value to. You can change this to help control the physical execution characteristics of your Spark jobs.
Go ahead and experiment with different values and see the number of partitions yourself. In experimenting with different values, you should see drastically different run times.
Remeber that you can monitor the job progress by navigating to the Spark UI on port 4040 to see the physical and logical execution characteristics of our jobs.

剩余93页未读,继续阅读
2019-10-28 上传
2019-10-28 上传
2021-01-09 上传
点击了解资源详情
2021-01-20 上传
2019-10-28 上传
点击了解资源详情
2019-08-08 上传
2021-05-12 上传

weixin_44363219
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
