Intel Spark SQL的自适应执行引擎优化
"Spark Adaptive Execution 是Intel Spark团队推出的一种针对Spark SQL的优化执行引擎,旨在自动获取最佳执行计划,以提升Spark SQL的性能。"
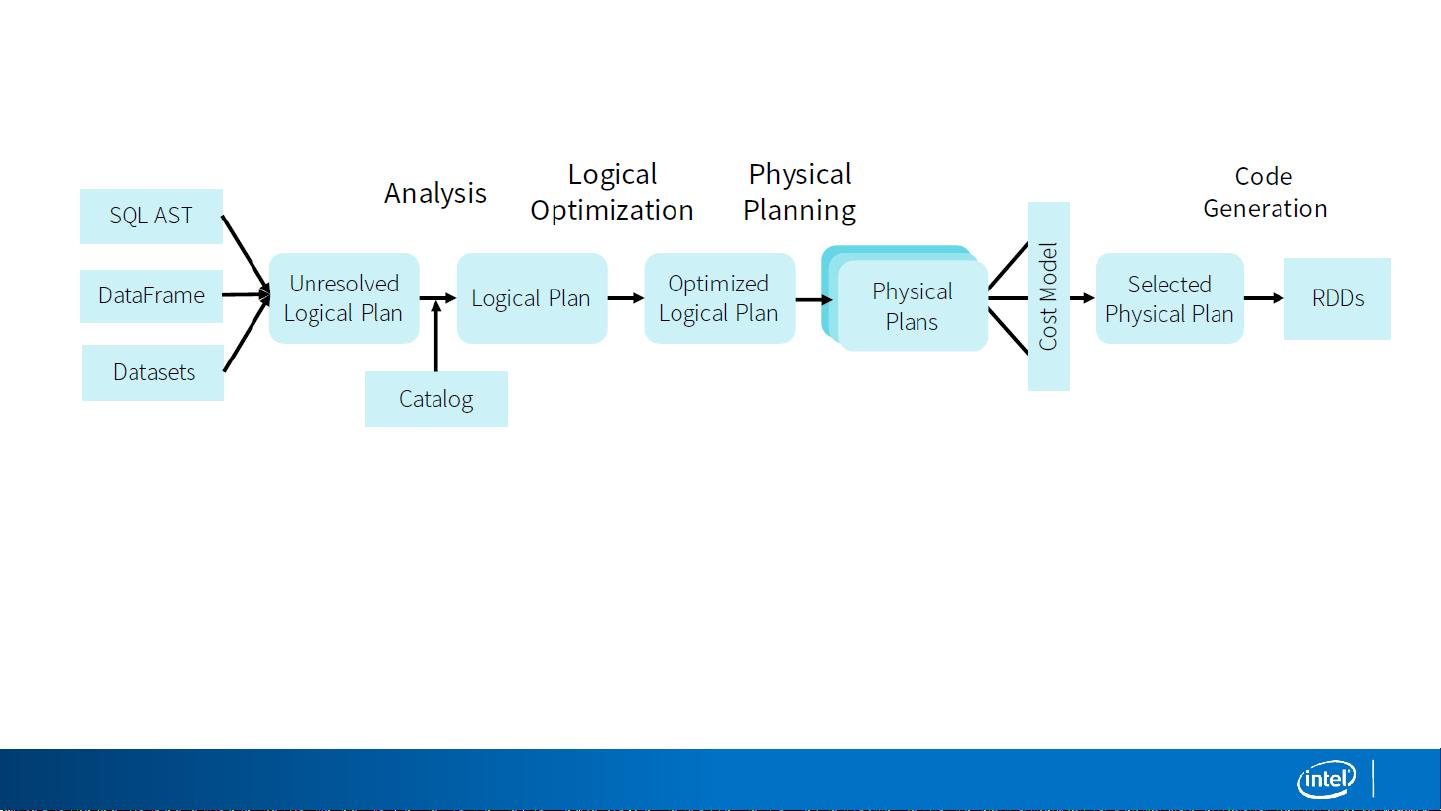
在Spark SQL中,自适应执行引擎(Adaptive Execution, AE)是一项重要的优化技术,它解决了传统Spark SQL执行计划固定不变的问题。传统的Spark SQL在规划阶段确定了执行计划后,这个计划在整个执行过程中保持不变,而自适应执行则允许在运行时根据实际情况调整执行策略,以应对不同的工作负载和环境变化。
挑战在于如何实现Spark SQL的高性能。一个关键的优化点是Shuffle Partition的数量。`spark.sql.shuffle.partition`参数默认设置为200,这表示每个shuffle操作将数据分成200个分区。集群的核数(Cluster Core Num C)由executor数量乘以每个executor的核数决定。在理想情况下,每个reduce任务需要运行`(P/C)`轮来处理所有数据,其中P是分区数。然而,这个分区数并不总是最优的。
问题一:当分区数太小时,可能会导致内存溢出(Spill)和Out-of-Memory(OOM)错误,因为数据可能超过单个分区的处理能力。另一方面,如果分区数过多,会增加调度开销,并可能导致大量小文件的生成,这在HDFS等分布式文件系统中是低效的。实践中,通常需要通过实验从C、2C...开始逐渐增加分区大小,直到性能开始下降,但这对生产环境中的每个查询来说是不切实际的。
问题二:同一Shuffle Partition数并不适用于所有Stage。随着SQL查询的执行,被shuffle的数据量通常会减少,这意味着固定的分区数可能在后续Stage中变得不适当。
为了解决这些问题,Spark引入了自适应执行架构,它可以自动为每个Stage设置合适的Shuffle Partition数量。这样,系统可以根据实际的输入数据大小和资源情况动态调整,以避免不必要的性能瓶颈和资源浪费。
执行计划是Spark SQL操作的核心,通常在规划阶段确定后不再改变。但在自适应执行模式下,Spark SQL的执行计划会在运行时进行优化。例如,它可能会根据数据倾斜动态调整分区,或者在发现某些Join操作可以优化时重新安排任务。这种灵活性使得Spark SQL能够更好地适应复杂的工作负载,提高整体的计算效率和资源利用率。
Spark Adaptive Execution是Spark SQL性能优化的重要组成部分,它通过动态调整执行计划中的关键参数,如Shuffle Partition数量,以适应不断变化的计算环境,从而提高查询性能并减少资源消耗。这对于大规模数据处理和实时分析的场景尤其关键,因为它允许Spark SQL在不影响正确性的情况下自动调整,以达到最佳的执行效率。

6
Solution:
Auto Set the Shuffle Partition Number for Each Stage
剩余31页未读,继续阅读
2019-08-29 上传
2020-12-30 上传
2024-07-18 上传
2023-04-06 上传
2023-04-10 上传
2023-05-25 上传
2023-05-12 上传
2023-03-16 上传
2023-09-14 上传

Erjin_Ren
- 粉丝: 13
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- iBATIS-SqlMaps-2_cn.pdf
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- IShort.pdf
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- 五子棋 课程设计 c语言
- unix基础教程(很好,很基础)
