Zynq FPGA上实现VGG16:硬件优化与实验报告
需积分: 0 122 浏览量
更新于2024-06-30
收藏 472KB PDF 举报
"这篇实验报告描述了作者张安澜在ZynqFPGA上实现VGG16神经网络前向传播的过程,旨在设计专用硬件进行图像识别。实验中使用了Xilinx的工具套件,包括Vivado HLx和Vivado SDK,以及AX7020开发板和SD卡读卡器。报告详细阐述了实验目的、要求、环境以及设计方案,特别是如何利用DMA和SD卡读写进行数据交互。"
在这个实验中,张安澜着重实现了VGG16网络的前向传播功能,这是一个深度学习领域常用的卷积神经网络模型,尤其在图像分类任务中表现优秀。VGG16由多个卷积层和池化层组成,其前向传播过程涉及大量的图像特征提取和计算,这在FPGA上实现需要高效的数据处理能力。
实验目的不仅限于硬件实现,还包括对VGG16网络的理解和模型训练。首先,需要使用如Caffe、TensorFlow或PyTorch等深度学习框架训练和测试模型,理解VGG16的网络结构和前向传播计算流程。接着,将训练好的模型数据整理成适合硬件实现的格式,存入SD卡。
实验要求强调了团队合作和具体实现步骤,包括模型和数据的读取、PL端的计算、PS-PL之间的数据交互以及最终的硬件验证。其中,xilffs库用于SD卡读写,DMA则用于高效地在PS(处理系统)和PL(可编程逻辑)之间传输数据,这在FPGA设计中是关键的性能优化手段。
实验环境包括TensorFlow作为算法开发框架,以及Vivado工具用于设计、仿真、综合和验证硬件逻辑,AX7020开发板提供了硬件平台,MiniSD卡和USB转接线用于存储和传输模型数据。
设计方案中,模型参数和测试数据被量化为定点数并以二进制补码形式存储,便于硬件处理。通过Xilffs读取SD卡数据,然后利用DMA进行PS-PL的数据交换。在设计时,考虑了如何有效地分层进行前向传播计算,以及如何优化数据交互和计算效率。
实验报告最后要求包含项目架构设计、实验步骤、关键代码、结果分析和优化策略,确保全面记录整个实施过程。通过这种方式,学生可以深入理解硬件加速在深度学习中的应用,以及如何在实际项目中实现和优化这样的系统。
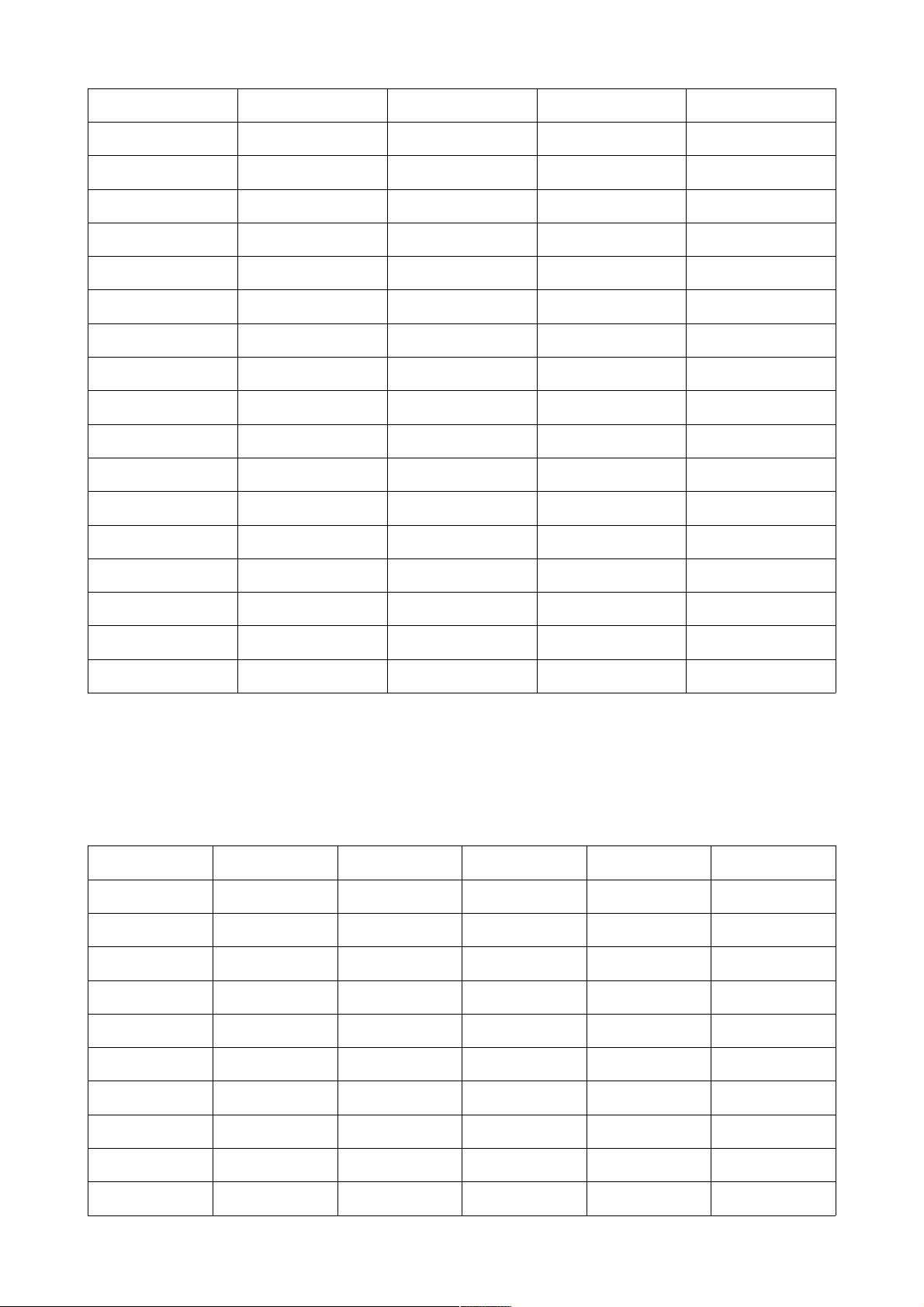
conv2_1 112*112*64 3*3*64*128 128 112*112*128
conv2_2 112*112*128 3*3*128*128 128 112*112*128
pool2 112*112*128 0 0 56*56*128
conv3_1 56*56*128 3*3*128*256 256 56*56*256
conv3_2 56*56*256 3*3*256*256 256 56*56*256
conv3_3 56*56*256 3*3*256*256 256 56*56*256
pool3 56*56*256 0 0 28*28*256
conv4_1 28*28*256 3*3*256*512 512 28*28*512
conv4_2 28*28*512 3*3*512*512 512 28*28*512
conv4_3 28*28*512 3*3*512*512 512 28*28*512
pool4 28*28*512 0 0 14*14*512
conv5_1 14*14*512 3*3*512*512 512 14*14*512
conv5_2 14*14*512 3*3*512*512 512 14*14*512
conv5_3 14*14*512 3*3*512*512 512 14*14*512
pool5 14*14*512 0 0 7*7*512
fc1 7*7*512 4096*7*7*512 4096 4096
fc2 4096 4096*4096 4096 4096
fc3 4096 1000*4096 1000 1000
b、每层网络的拆分
拆分的原则:在 Block RAM 资源充足的情况下最大化 Block RAM 的使用,且保证
每一层网络拆分后的小网络的结构相同,拆分后得到的每一层拆分的小网络的参数和数
据,以及需要计算的次数如下:
Layer name data weight bias result count
conv1_1 224*224*3 3*3*3*4 4 224*224*4 1*16
conv1_2 224*224*4 3*3*4*4 4 224*224*4 16*16
pool1 224*224*4 0 0 112*112*4 16
conv2_1 112*112*16 3*3*16*16 16 112*112*16 4*8
conv2_2 112*112*16 3*3*16*16 16 112*112*16 8*8
pool2 112*112*16 0 0 56*56*16 8
conv3_1 56*56*64 3*3*64*64 64 56*56*64 2*4
conv3_2 56*56*64 3*3*64*64 64 56*56*64 4*4
conv3_3 56*56*64 3*3*64*64 64 56*56*64 4*4
pool3 56*56*64 0 0 28*28*64 4
剩余26页未读,继续阅读
2022-08-04 上传
2024-10-13 上传
2024-10-13 上传
2024-10-13 上传
2024-10-13 上传
2024-10-13 上传

五月Eliy
- 粉丝: 37
- 资源: 304
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
