
Hadoop分布式文件系统:架构和设计要点分布式文件系统:架构和设计要点
一、前提和设计目标一、前提和设计目标
1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检
测和快速、自动的恢复是HDFS的核心架构目标。
2、跑在HDFS上的应用与一般的应用不同,它们主要是以流式读为主,做批量处理;比之关注数据访问的低延迟问题,更关
键的在于数据访问的高吞吐量。
3、HDFS以支持大数据集合为目标,一个存储在上面的典型文件大小一般都在千兆至T字节,一个单一HDFS实例应该能支撑
数以千万计的文件。
4、 HDFS应用对文件要求的是write-one-read-many访问模型。一个文件经过创建、写,关闭之后就不需要改变。这一假设简
化了数据一致性问题,使高吞吐量的数据访问成为可能。典型的如MapReduce框架,或者一个web crawler应用都很适合这个
模型。
5、移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效,这在数据达到海量级别的
时候更是如此。将计算移动到数据附近,比之将数据移动到应用所在显然更好,HDFS提供给应用这样的接口。
6、在异构的软硬件平台间的可移植性。
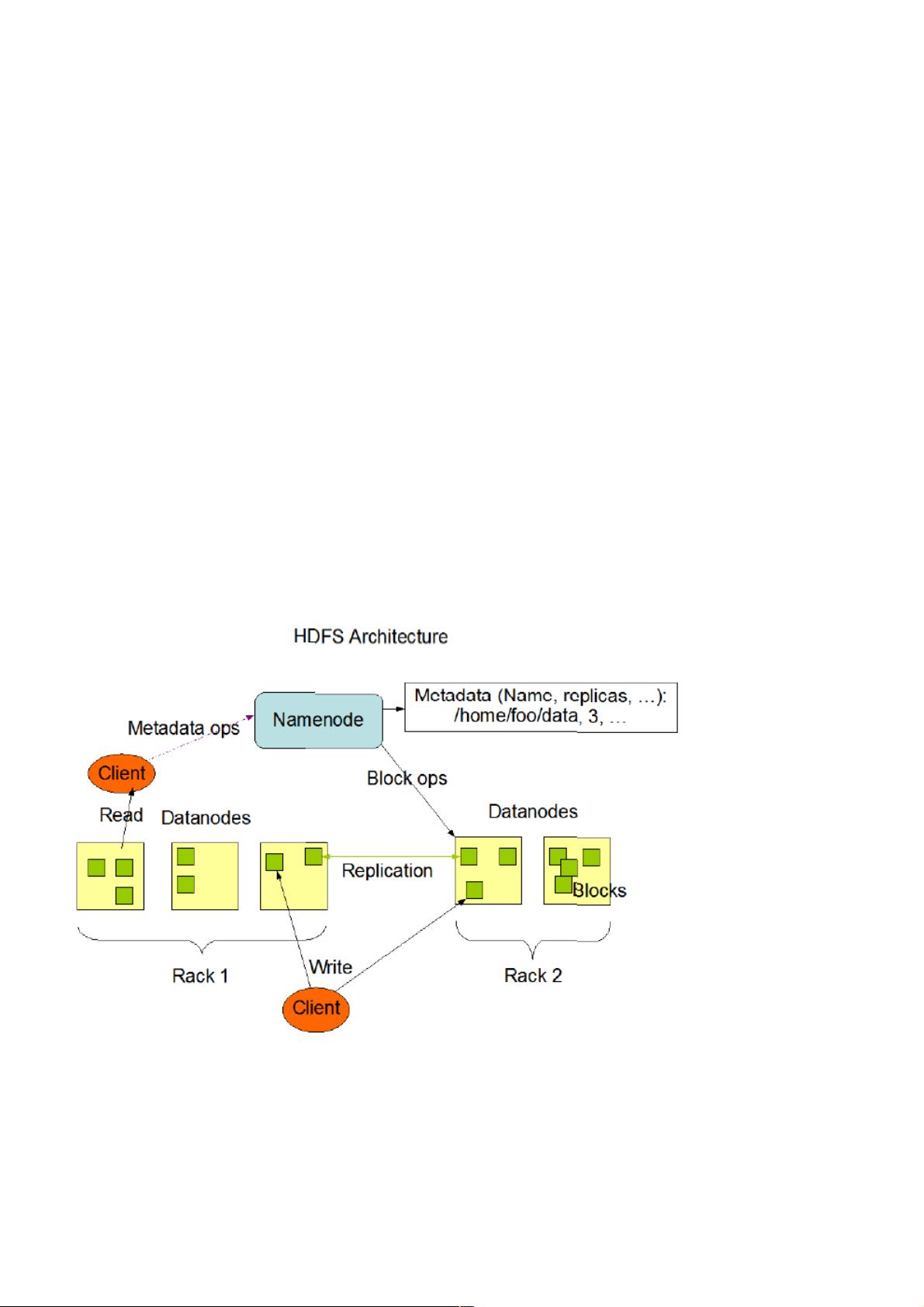
二、二、Namenode和和Datanode
HDFS采用master/slave架构。一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务
器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点一个,负责管理节点上它们
附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的
namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode
的指挥下进行block的创建、删除和复制。Namenode和Datanode都是设计成可以跑在普通的廉价的运行linux的机器上。
HDFS采用java语言开发,因此可以部署在很大范围的机器上。一个典型的部署场景是一台机器跑一个单独的Namenode节
点,集群中的其他机器各跑一个Datanode实例。这个架构并不排除一台机器上跑多个Datanode,不过这比较少见。
单一节点的Namenode大大简化了系统的架构。Namenode负责保管和管理所有的HDFS元数据,因而用户数据就不需要通过
Namenode(也就是说文件数据的读写是直接在Datanode上)。
三、文件系统的三、文件系统的namespace
HDFS支持传统的层次型文件组织,与大多数其他文件系统类似,用户可以创建目录,并在其间创建、删除、移动和重命名文
件。HDFS不支持user quotas和访问权限,也不支持链接(link),不过当前的架构并不排除实现这些特性。Namenode维护文
件系统的namespace,任何对文件系统namespace和文件属性的修改都将被Namenode记录下来。应用可以设置HDFS保存的
文件的副本数目,文件副本的数目称为文件的 replication因子,这个信息也是由Namenode保存。
四、数据复制四、数据复制
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38582793
- 粉丝: 6
- 资源: 888
 我的内容管理
展开
我的内容管理
展开







最新资源
- 达梦数据库DM8手册大全:安装、管理与优化指南
- Python Matplotlib库文件发布:适用于macOS的最新版本
- QPixmap小demo教程:图片处理功能实现
- YOLOv8与深度学习在玉米叶病识别中的应用笔记
- 扫码购物商城小程序源码设计与应用
- 划词小窗搜索插件:个性化搜索引擎与快速启动
- C#语言结合OpenVINO实现YOLO模型部署及同步推理
- AutoTorch最新包文件下载指南
- 小程序源码‘有调’功能实现与设计课程作品解析
- Redis 7.2.3离线安装包快速指南
- AutoTorch-0.0.2b版本安装教程与文件概述
- 蚁群算法在MATLAB上的实现与应用
- Quicker Connector: 浏览器自动化插件升级指南
- 京东白条小程序源码解析与实践
- JAVA公交搜索系统:前端到后端的完整解决方案
- C语言实现50行代码爱心电子相册教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


