




ADAM:处理TB级基因组数据的高性能分布式工具
下载需积分: 50 | PDF格式 | 372KB |
更新于2024-06-20
| 190 浏览量 | 举报
藏经阁-Processing Terabyte Scale.pdf是一篇由Frank Austin Nothaft(来自加州大学伯克利分校)撰写的专业论文,重点关注在大数据时代处理基因组学数据的挑战与解决方案。文章的核心议题集中在如何有效处理和分析达到太字节(terabyte)级的海量基因组数据,特别是人类基因组测序产生的数据,这些数据通常包含数百吉字节的原始序列信息。
论文首先介绍了基因组测序的基本过程,当一个人的基因组被测序时,会产生大量的数据,这不仅包括个体间的差异,也带来了数据处理和解读的双重挑战。如何计算这些差异(如SNPs、Indels等)以及如何理解这些差异对于生物学研究至关重要。
ADAM(Advanced Genomics Data Analysis Methodology)是论文中提及的一个关键工具,它是一个开源的高性能分布式库,专为基因组数据分析设计。ADAM的核心在于其数据模型和存储布局,它定义了一种数据架构,使得基因组数据能够在分布式系统(如Spark+Scala)上进行高效的并行处理。这有助于实现批处理和探索性分析,支持各种类型基因组数据的分析,突破了传统单节点工具在扩展性和功能上的局限。
传统基因组数据格式,如手动编写的文本或二进制平铺文件(如SAM/BAM用于比对,VCF用于变异检测,BED/GTF用于特征注释),虽然便于使用,但它们在单一计算机存储和计算能力受限的情况下难以扩展。这些格式的问题主要表现在性能瓶颈、可优化操作的限制以及易出错的特性。例如,它们可能无法高效地执行针对全行数据的操作,也无法支持复杂的查询条件(predicates)。
因此,论文提出了使用ADAM来构建更健壮、可扩展的基因组学工具,旨在解决大数据时代面临的挑战,通过优化数据结构和编程接口,使得科学家能够更好地处理和利用这些海量的基因组数据,推动基因组学研究的进一步发展。藏经阁-Processing Terabyte Scale.pdf提供了关于如何在大数据环境下进行基因组学数据分析的关键技术和策略,这对于基因组学研究人员和相关领域专业人士来说具有很高的实用价值。
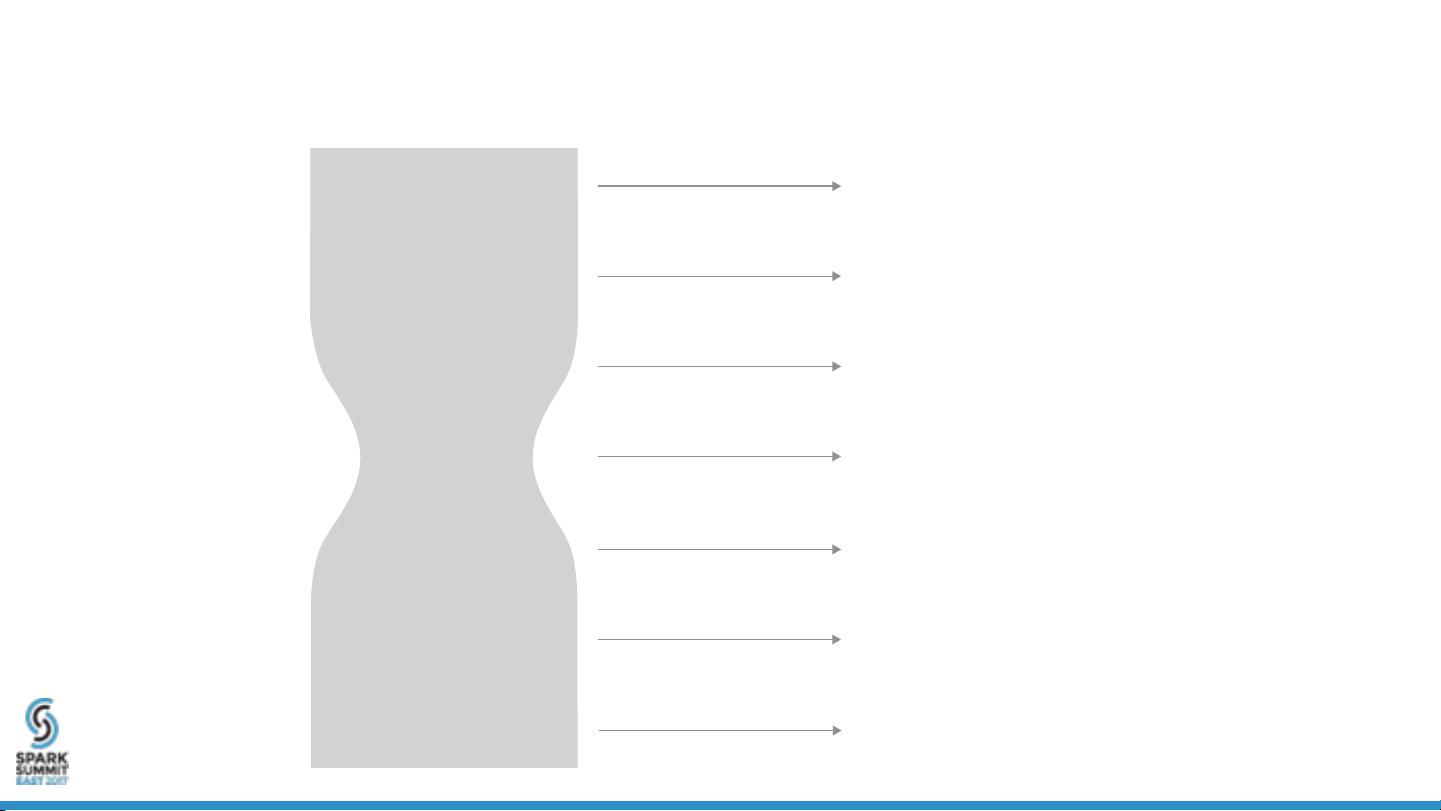
ADAM uses a schema as a narrow waist
Application
Transformations
Physical Storage
Attached Storage
Data Distribution
Parallel FS
Materialized Data
Columnar Storage
Evidence Access
MapReduce/DBMS
Presentation
Enriched Models
Schema
Data Models
Variant calling & analysis,
RNA-seq analysis, etc.
Disk, SDD, block
store, memory cache
HDFS, Tachyon, HPC file
systems, S3
Load data from Parquet and
legacy formats
Spark, Spark-SQL,
Hadoop
Enriched Read/Variant
Avro Schema for reads,
variants, and genotypes
Users define analyses
via transformations
Enriched models provide convenient
methods on common models
The evidence access layer
efficiently executes transformations
Schemas define the logical
structure of basic genomic objects
Common interfaces map logical
schema to bytes on disk
Parallel file system layer
coordinates distribution of data
Decoupling storage enables
performance/cost tradeoff
下载后可阅读完整内容,剩余21页未读,立即下载
相关推荐
2023-09-09 上传
167 浏览量
2022-01-16 上传
2022-01-07 上传
2022-10-31 上传
138 浏览量
2019-08-29 上传
2020-02-05 上传
2021-10-13 上传

weixin_40191861_zj
- 粉丝: 92
 我的内容管理
展开
我的内容管理
展开








最新资源
- Discuz模板安装教程与糗事百科风格仿制指南
- SSH2网络硬盘源代码及数据库建表教程
- 基于Caesar密码的MATLAB网络安全GUI应用
- 全面掌握PB编程:函数、问题与技巧集锦
- KX3552一键安装方法及效果展示
- VB6打造定制IE风格WEB浏览器教程
- LinkCreator0.7:将URL转换为电驴edk地址的实用工具
- MATLAB 2D Quiver Plot绘图教程与示例分析
- MATLAB在喷墨打印中的应用:单元格数组输出至CSV
- ibatis-2.3.0.677源码分析与下载指南
- 实现鼠标悬停图片3D旋转效果的技术教程
- VB简易版软件功能介绍及使用说明
- 掌握软件测试:企业实战教程与内部课件
- 微信小程序聊天室开发教程与问题解决
- 2007天津市程序设计竞赛初赛VB折半查找解析
- 深入解析USB协议与S3C2410控制器应用






















