Hive架构详解:用户接口、元数据管理与MapReduce集成
10 浏览量
更新于2024-09-01
收藏 960KB PDF 举报
Hive是一个基于Hadoop的数据仓库工具,其体系结构主要包括用户接口、元数据管理、查询处理和数据存储四个关键组件。
1. **用户接口**:
- CLI (Command Line Interface) 是Hive最常见的接口,用户通过它编写Hive Query Language (HQL) 并执行查询。启动CLI时,会自动启动一个Hive副本。
- Client 是Hive的客户端程序,允许用户连接到HiveServer,进行交互式查询或批量作业。
- WUI (Web User Interface) 是通过浏览器访问Hive的方式,提供图形化界面,便于非命令行用户操作。
2. **元数据管理**:
- Hive将元数据存储在关系型数据库中,如MySQL或Derby,这些数据存储包括表名、列定义、分区信息、表属性(如是否为外部表)、数据存储路径等。
- Hive支持多种连接模式:单用户模式(Derby内存数据库,用于单元测试)、多用户模式(网络连接到远程数据库)和远程服务器模式(通过Thrift协议访问元数据服务器)。
3. **查询处理**:
- Hive的解释器、编译器和优化器负责解析用户输入的HQL语句,执行词法分析、语法分析、编译、优化,并生成查询计划。
- 查询计划存储在Hadoop分布式文件系统(HDFS)中,随后由MapReduce框架执行,但全表扫描除外(如`SELECT * FROM`操作通常不直接生成MR任务)。
4. **数据存储**:
- 数据存储在HDFS中,Hive不维护特定的数据存储格式,用户可以自由定义数据组织方式,只需指定列分隔符和行分隔符。
- Hive支持的数据模型包括:
- 内部表(Table):存储在HDFS上的普通表,数据与元数据紧密关联。
- 外部表(ExternalTable):指向HDFS上独立存储的数据,元数据仅记录表的位置。
- 分区(Partition):根据某些列值将数据划分为多个逻辑部分,提高查询性能。
- 桶(Bucket):将数据分布到不同的物理位置,用于分区或数据压缩。
- Hive支持多种数据格式,如文本文件(TextFile)、SequenceFile和RCFile。
5. **连接模式与数据模型灵活性**:
- Hive允许用户在不同的数据存储模式下工作,提供了灵活的数据组织和访问选项。
Hive的体系结构设计考虑了易用性、扩展性和性能,使得用户能够高效地在Hadoop平台上进行数据仓库管理和数据分析。理解并掌握Hive的这些核心组件是构建和管理大规模数据仓库的关键。
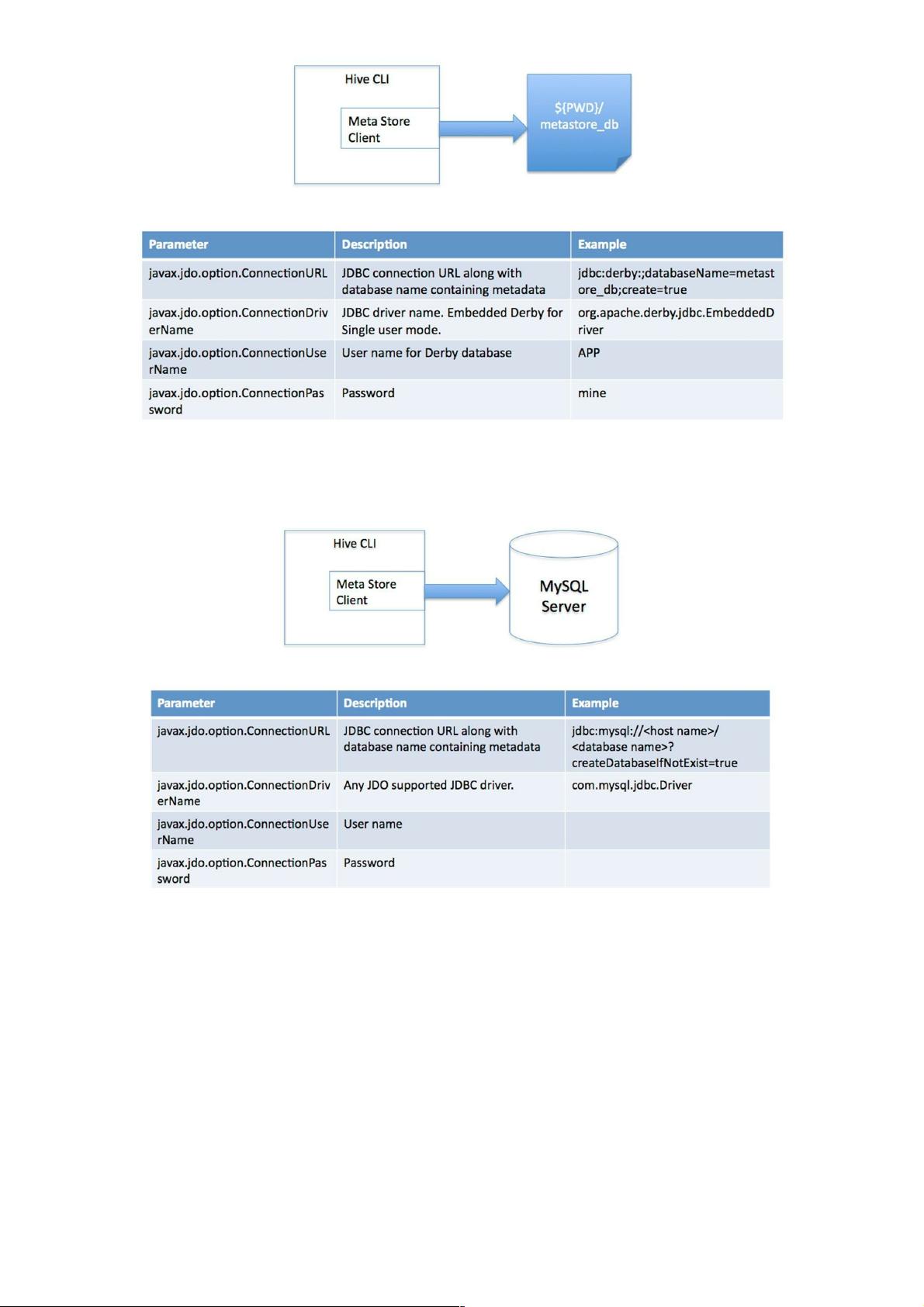
图2.1 单用户模式
(2)多用户模式。通过网络连接到一个数据库中,是最经常使用到的模式。
图2.2 多用户模式
(3) 远程服务器模式。用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过
MetaStoreServer访问元数据库。
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-01-14 上传
2022-11-04 上传
2021-03-04 上传
2019-04-15 上传
2021-10-14 上传
2021-10-04 上传

weixin_38638688
- 粉丝: 2
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
