R语言文本挖掘:整洁之道
需积分: 12 71 浏览量
更新于2024-07-18
收藏 12.97MB PDF 举报
"Text Mining with R A Tidy Approach" 是一本由 Julia Silge 和 David Robinson 合著的专业书籍,专注于使用 R 语言进行文本挖掘。该书于2017年由 O'Reilly Media 出版,旨在提供一个整洁、结构化的途径来处理和分析文本数据。
在当今大数据时代,文本挖掘已经成为理解和提取有价值信息的关键技术,特别是在社交媒体分析、市场研究、情感分析等领域。R 语言因其强大的统计分析能力和丰富的数据分析包库,成为文本挖掘的理想选择。本书作者 Julia Silge 和 David Robinson 是数据科学领域的专家,他们结合自己的实践经验,将文本挖掘的方法与 R 语言的 tidyverse 套件相结合,为读者提供了一种高效、可复用且易于理解的文本分析方法。
本书的主要内容包括:
1. **文本预处理**:讲解如何清洗和规范化文本数据,包括去除停用词、标点符号和数字,以及词干提取和词形还原等步骤。
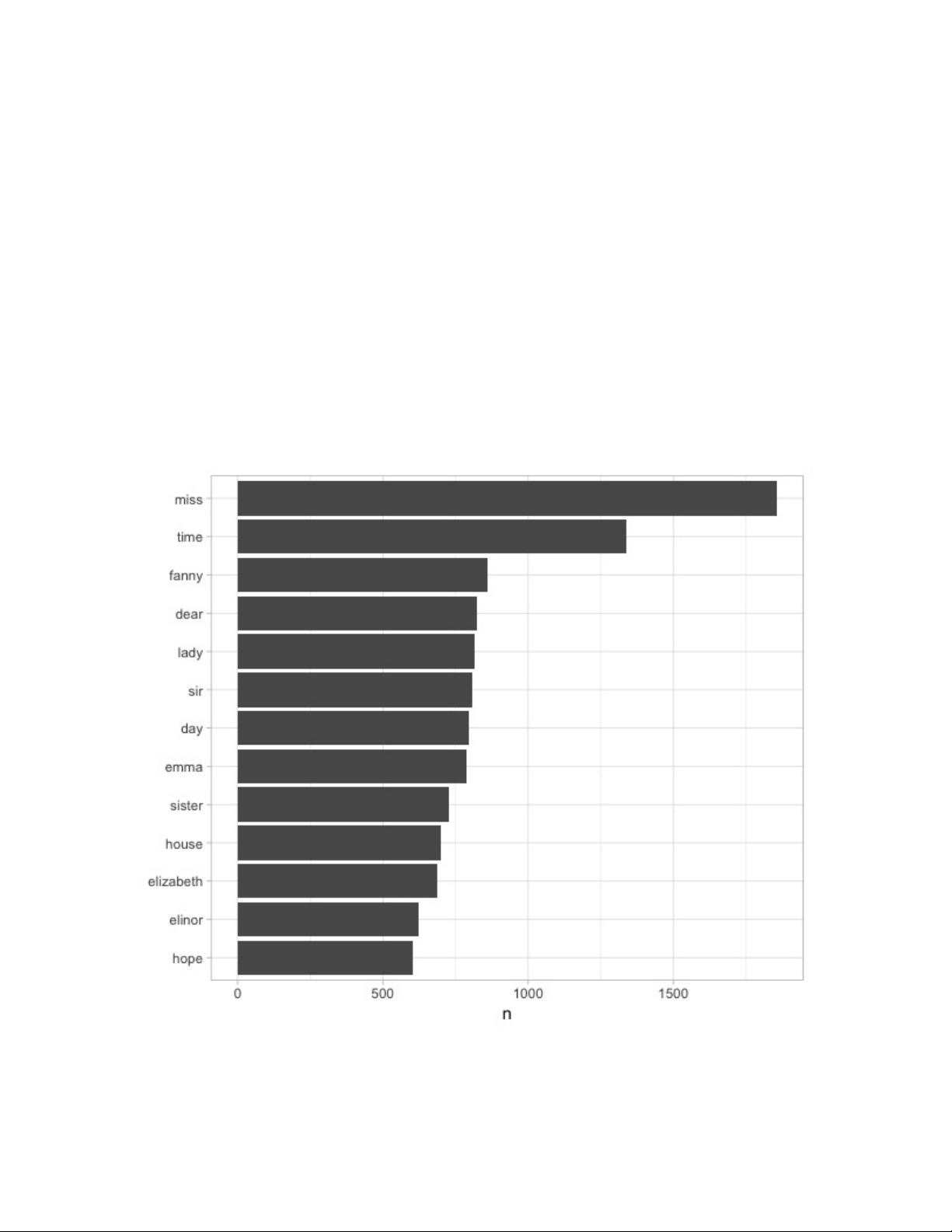
2. **词汇量分析**:介绍如何使用频率分布和词云等可视化工具来探索文本中的关键词和主题。
3. **文档-术语矩阵**:解释如何构建 DTMs(Document-Term Matrices)来表示文本数据,并使用它来进行进一步的分析。
4. **主题建模**:探讨 LDA(Latent Dirichlet Allocation)和其他主题模型,用于发现隐藏在大量文本中的潜在主题。
5. **情感分析**:讲解如何评估文本中的情感倾向,包括使用预训练的情感词典和训练自定义模型。
6. **网络分析**:利用网络图来揭示文本中的实体关系,例如人名、组织名之间的关联。
7. **案例研究**:通过实际项目案例,展示如何应用上述方法解决具体问题,如分析推特数据或新闻报道等。
此外,书中还强调了 tidyr、dplyr、ggplot2 等 tidyverse 包的应用,这些工具使得数据处理更加简洁和一致。书中的代码示例和实践练习将帮助读者快速上手并掌握文本挖掘的核心技巧。
本书适合有一定 R 语言基础和对文本分析感兴趣的读者,无论是数据科学家、分析师还是研究人员,都能从中获益。通过学习这本书,读者不仅可以提升在 R 语言环境下的文本挖掘技能,还能了解到如何以一种结构化、可重复的方式进行数据工作,这对于提升数据分析的效率和质量至关重要。
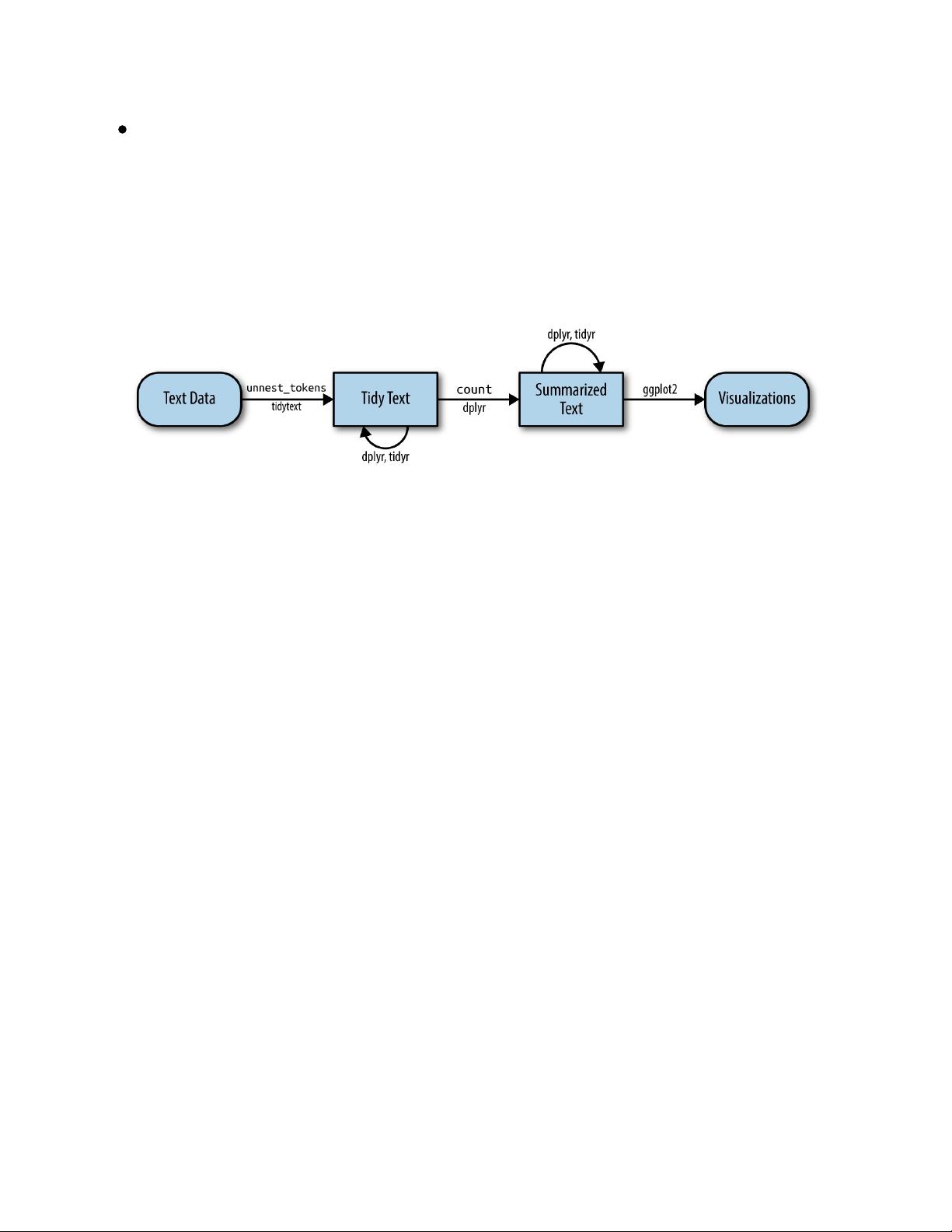
In this first example, we only have one document (the poem), but we will
explore examples with multiple documents soon.
Within our tidy text framework, we need to both break the text into
individual tokens (a process called tokenization) and transform it to a tidy
data structure. To do this, we use the tidytext unnest_tokens() function.
library(tidytext)
text_df %>%
unnest_tokens(word, text)
## # A tibble: 20 × 2
## line word
## <int> <chr>
## 1 1 because
## 2 1 i
## 3 1 could
## 4 1 not
## 5 1 stop
## 6 1 for
## 7 1 death
## 8 2 he
## 9 2 kindly
## 10 2 stopped
## # ... with 10 more rows
The two basic arguments to unnest_tokens used here are column names.
First we have the output column name that will be created as the text is
unnested into it (word, in this case), and then the input column that the text
comes from (text, in this case). Remember that text_df above has a column
called text that contains the data of interest.
After using unnest_tokens, we’ve split each row so that there is one token
(word) in each row of the new data frame; the default tokenization in
unnest_tokens() is for single words, as shown here. Also notice:
Other columns, such as the line number each word came from, are
retained.
Punctuation has been stripped.


剩余246页未读,继续阅读
相关推荐




dkzzw
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开








最新资源
- 商网中国静态html网址导航快速生成指南
- Java开发经典闹钟小程序教程
- C#实现的Modbus-RTU通讯源码工具
- nodeplayer实现Spotify后端服务教程
- 全面解读erhem蒙文输入法功能及应用
- 掌握SQL数据插入技巧,提高数据库操作效率
- 客户机部署DXperienceEval-7.1.1的简易指南
- 全面升级版电子商务解决方案:时代购物系统V2.0
- CP2102 USB转UART驱动安装教程
- Matlab机器人设计仿真工具箱应用指南
- iPad基础开发教程源码下载
- Node.js项目模板:基本摩卡与柴模板安装与使用
- C# ASP.NET实现XML留言板模块功能详解
- 醍醐网秀:最美网址导航程序源码
- IC 3D模型集合,兼容Allegro PCB的STEP格式文件下载
- 高效数据插入技巧:SQL批量操作详解











