腾讯大数据治理与优化:基于Apache Iceberg
版权申诉
41 浏览量
更新于2024-07-05
收藏 6.25MB PDF 举报
“3-4+腾讯基于+Apache+Iceberg+的数据治理与优化.pdf”主要探讨了腾讯如何利用Apache Iceberg进行数据治理和优化,特别是在数据入湖、数据治理服务、数据查询优化以及未来展望方面的实践。
Apache Iceberg是一个现代的开源表格式,设计用于大规模数据湖存储,支持流式和批处理的数据处理。在腾讯的实践中,它被用来构建实时数据入湖的链路。Apache Iceberg的核心特性包括:
1. **数据入湖**:Apache Iceberg支持多种列式存储格式,如Parquet、ORC和Avro,这些格式能提供高效的读写性能。在存储层,它不强绑定特定的计算存储引擎,允许灵活选择计算框架,如Flink、Spark或Hive。在数据写入过程中,Iceberg采用基于快照的读写分离和回溯机制,确保数据一致性。
2. **数据治理服务**:Iceberg提供了ACID语义,即原子性、一致性、隔离性和持久性,保证了数据操作的正确性。此外,它支持数据多版本,可以跟踪表、模式和分区的变更,这对于数据治理和审计至关重要。
3. **数据查询优化**:Iceberg的文件组织方式是通过快照和提交时间线来管理数据,每个快照都包含对数据文件和manifest文件的引用。这种结构使得增量读取成为可能,只读取自上次查询以来发生变化的数据,从而提高查询效率。Iceberg的读写流程通过提交时间线进行协调,确保在并发写入和读取时的数据一致性。
4. **Apache Iceberg与Flink的集成**:腾讯使用Iceberg的Flink Sink,如IcebergStreamWriter和IcebergFileCommitter,构建了实时数据入湖的解决方案。这使得Flink能够高效地将流式数据写入到Iceberg表中,实现了流批统一的写入和读取。
5. **未来展望**:随着大数据技术的发展,腾讯可能会继续探索如何利用Iceberg的特性,比如元数据管理、数据生命周期管理、以及进一步优化数据查询性能。同时,可能会考虑与其他数据处理工具和云服务的更深度融合,以提升整个数据湖的效率和灵活性。
总结来说,腾讯通过Apache Iceberg实现了一套高效、灵活且治理完善的数据湖架构,优化了数据入湖、查询和治理流程,为大数据分析和决策支持提供了强大的基础设施。
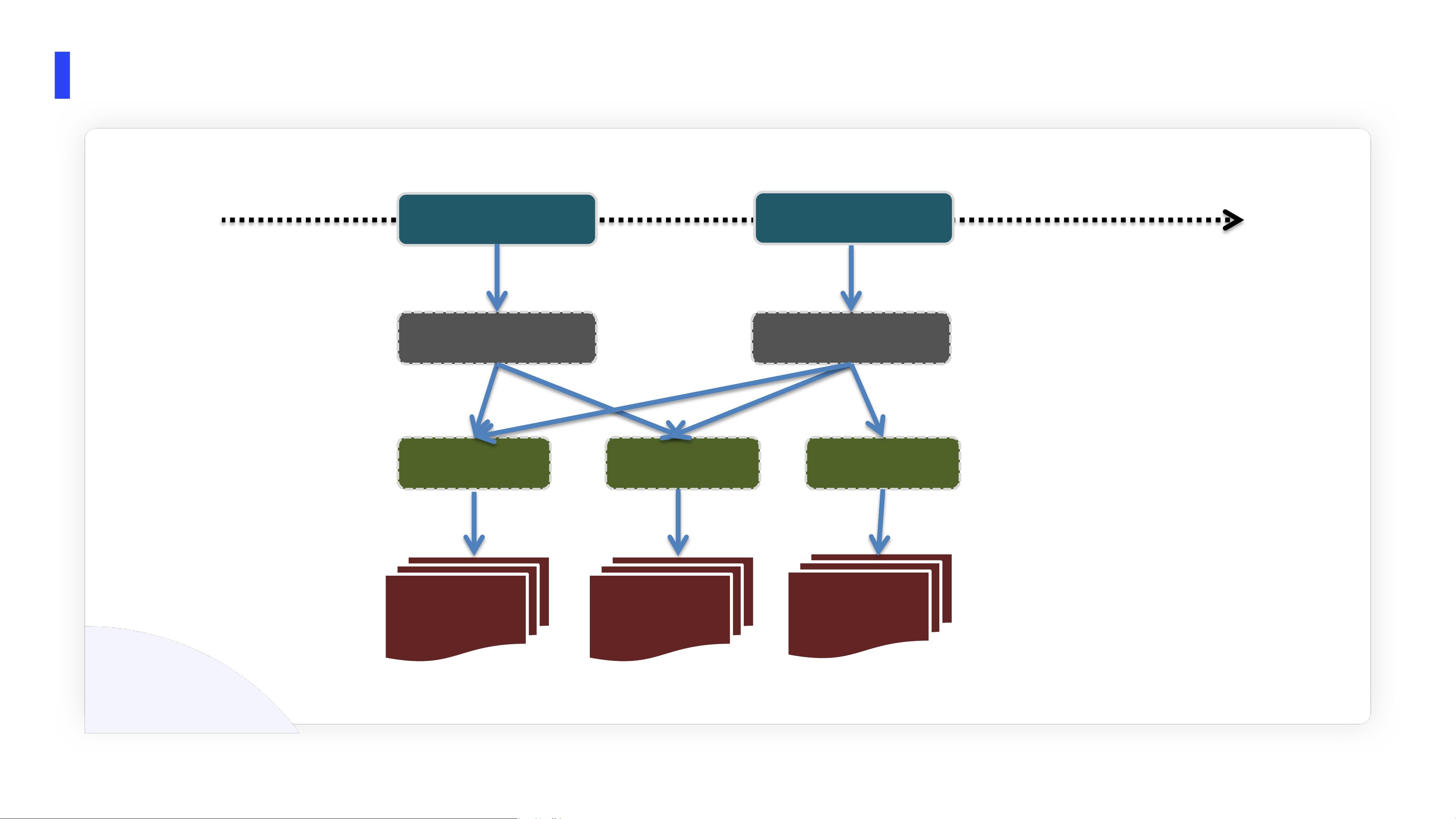
数据入湖
DataFunSummit
Tencent
|
Apache Iceberg 文件组织
What is Apache Iceberg
Snapshot-0
Snapshot-1
manifest list manifest list
manifest0 manifest1 manifest2
DataFiles DataFiles
DataFiles
Commit Timeline
剩余29页未读,继续阅读
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-11-21 上传
2022-03-18 上传
2022-03-18 上传
2022-04-29 上传
2022-03-06 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- gawiga-nextjs
- OOP_assignment
- compose-countdown-timer
- urban-dictionary:一个Node.js模块,可从urbandictionary.com访问术语和定义
- Payroll-6-12
- TeambitionNET
- 行业分类-设备装置-可移动升降平台.zip
- 易语言创建Access数据库-易语言
- starter-research-group
- leetcode-javascript
- hardhat-next-subgraph-mono:具有安全帽,Next和theGraph的Monorepo模板
- Catalog-开源
- du-an-1
- 行业分类-设备装置-可相互连接的纸质板材组件.zip
- SwiftySequencer:AESequencer 的快速实现
- my-profile
