基于Flink的实时数据处理平台架构和技术实现
108 浏览量
更新于2024-08-29
收藏 536KB PDF 举报
基于Flink构建用户实时基础行为工程
Flink是目前Qunar主推的实时数据处理开源平台,用于替代SparkStreaming。Flink是一个面向数据流处理和批量数据处理的分布式的开源计算框架,能够支持流处理和批处理两种应用类型。有着低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理的特点。
Flink的特点包括:
1. 有状态计算的Exactly-once语义:Flink能够维护数据在时序上的聚类和聚合,同时它的checkpoint机制可以方便快速的做出失败重试。
2. 支持带有事件时间(eventtime)语义的流处理和窗口处理:事件时间的语义使流计算的结果更加精确,尤其在事件到达无序或者延迟的情况下。
3. 支持高度灵活的窗口(window)操作:支持基于time、count、session,以及data-driven的窗口操作,能很好的对现实环境中的创建的数据进行建模。
4. 轻量的容错处理(fault tolerance):它使得系统既能保持高的吞吐率又能保证exactly-once的一致性。通过轻量的statesnapshots实现。
5. 支持高吞吐、低延迟、高性能的流处理。
6. 支持savepoints机制(一般手动触发):即可以将应用的运行状态保存下来;在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间。
7. 支持大规模的集群模式,支持yarn、Mesos:可以运行在成千上万的节点上。
8. 支持具有Backpressure功能的持续流模型。
9. Flink在JVM内部实现了自己的内存管理,包括完善的内存架构和OOM。
在基于Flink构建用户实时基础行为工程中,可以使用Flink的这些特点来实现高性能、低延迟的流处理和批处理,并且可以处理每天超过12亿条实时数据,数据实时性达到秒级,QPS可支持10万的用户实时基础行为工程的技术实现。
基于基于Flink构建用户实时基础行为工程构建用户实时基础行为工程
导读
Flink 是目前 Qunar 主推的实时数据处理开源平台,用于替代 SparkStreaming。如果你们使用 Flink 也是和我们之前一样,不
知道如何使用我们的 Flink 实时计算平台,或者不知道该怎样合理利用其 Features 去更好构建我们的工程,再或者你想了解
每天处理超过12亿条实时数据,数据实时性达到秒级,QPS 可支持10万的用户实时基础行为工程的技术实现,你在后面应该
能找到你的答案。
Flink简介
Apache Flink 是一个面向数据流处理和批量数据处理的分布式的开源计算框架,能够支持流处理和批处理两种应用类型。有着
低延迟、Exactly-once 保证,而批处理需要支持高吞吐、高效处理的特点。 Flink 是完全支持流处理,也就是说作为流处理看
待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。这与 sparkstreaming 不
同,sparkstreaming 是将流处理视为无限个有界的批处理(microbatch)。
1 Flink 特点
(1)有状态计算的 Exactly-once 语义。状态是指 flink 能够维护数据在时序上的聚类和聚合,同时它的 checkpoint 机制可以
方便快速的做出失败重试; (2)支持带有事件时间(event time)语义的流处理和窗口处理。事件时间的语义使流计算的结
果更加精确,尤其在事件到达无序或者延迟的情况下; (3)支持高度灵活的窗口(window)操作。支持基于 time、count、
session,以及 data-driven 的窗口操作,能很好的对现实环境中的创建的数据进行建模; (4)轻量的容错处理(fault
tolerance)。 它使得系统既能保持高的吞吐率又能保证 exactly-once 的一致性。通过轻量的 state snapshots 实现; (5)支
持高吞吐、低延迟、高性能的流处理; (6)支持 savepoints 机制(一般手动触发)。即可以将应用的运行状态保存下来;
在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间; (7)支持大规模的集群模式,支持 yarn、Mesos。可
运行在成千上万的节点上; (8)支持具有 Backpressure 功能的持续流模型; (9)Flink 在 JVM 内部实现了自己的内存管
理,包括完善的内存架构和 OOM error prevention;
(10)支持迭代计算; (11)支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果进行缓存。
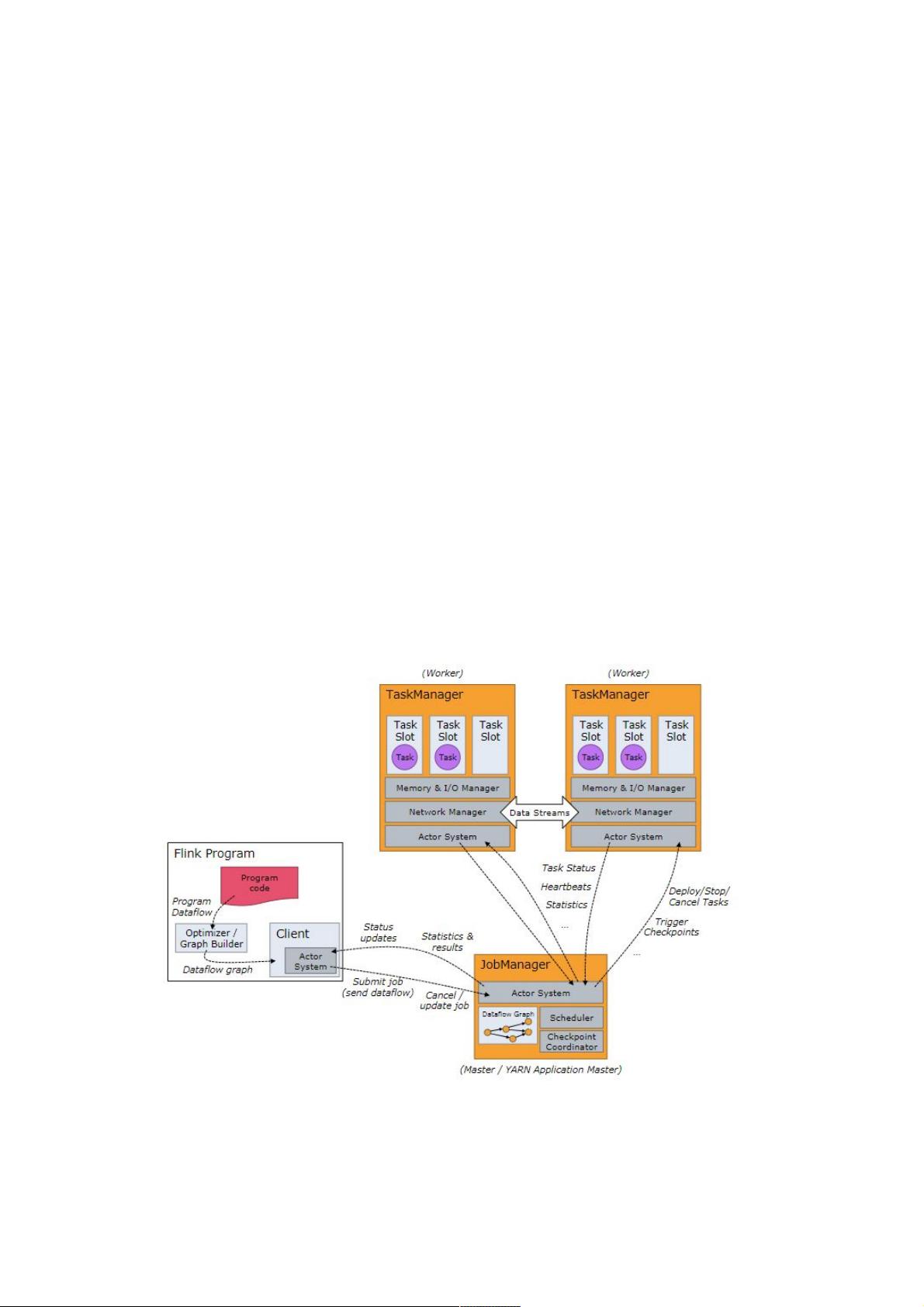
2 Flink 分布式 runtime
(1)JobManager 主要工作是协调分布式系统的运行。比如协调各个任务的执行时间,管理 checkpoint 和协调异常状态的恢
复等。 (2)TaskManager 是任务的真正执行者,包括数据流的缓存和交换等操作。 (3)client 不是 Flink Runtime 的一部
分,也不参与任务的真正执行,只是用来启动 Job 时生成执行计划并交给 JobManager。
3 Flink 流式(DataStream)编程模型
3.1 编程抽象层级
下载后可阅读完整内容,剩余7页未读,立即下载
2022-07-03 上传
2022-05-28 上传
2021-10-19 上传
点击了解资源详情
点击了解资源详情
2023-06-14 上传
2022-06-19 上传
2021-10-26 上传
点击了解资源详情

weixin_38546789
- 粉丝: 3
- 资源: 911
 我的内容管理
展开
我的内容管理
展开







最新资源
- vue3自定义指令实现图片懒加载
- DummyDataLake:数据湖实现学习
- 【STK+Python仿真】搭建仿真环境调试效果_屏幕录像.mp4.zip
- c代码-出租车记价表
- 温顺:温顺使您的Ruby DSL保持驯服且行为规范
- pr-title-check:基于常规提交的PR标题验证
- React-Redux-Dungeon
- iOS强制屏幕旋转兼容iOS11到iOS17
- Malware-Detection-Using-Two-Dimensional-Binary-Program-Features:使用二维二进制程序功能进行基于深度神经网络的恶意软件检测的文档,源代码和数据链接
- 省份地图系列图标下载
- 实现基于spartan3与CAN总线连接后的的汽车时速的模拟仿真.7z
- ObjectPoolingUnity:在BulletHell游戏中使用Unity中的Top Down Architecture进行ObjectPooling
- awslayer-manager:这是一个简单的工具,可将项目需求构建和上传为AWS Lambda层
- 上传文件FileZilla.zip
- 严峻:用于从pdf中提取页面作为图像和文本作为字符串的工具
- atmacup10:atmacup10的代码
