NLPIR/ICTCLAS2015分词系统开发手册
需积分: 0 72 浏览量
更新于2024-06-30
收藏 1.36MB PDF 举报
"NLPIR-ICTCLAS2014分词系统开发手册2015版1"
NLPIR(Natural Language Processing in Chinese, 中文自然语言处理)/ ICTCLAS(Institute of Computing Technology Chinese Lexical Analysis System, 计算技术研究所中文词法分析系统)是2015年版本的分词系统,由Kevin Zhang版权所有。该系统专注于中文文本的处理,特别是分词任务,这是自然语言处理中的基础环节。NLPIR/ICTCLAS2015提供了开发文档,帮助开发者理解和使用这一工具。
NLPIR系统旨在提供高效、准确的中文分词服务,它不仅包含分词功能,还可能涵盖词性标注、命名实体识别等NLP任务。NLPIR的最新信息可以通过官方网站http://ICTCLAS.nlpir.org获取,这个平台也提供系统的最新版本下载。此外,用户可以通过关注张华平博士在新浪微博上的账号@ICTCLAS张华平博士,获取相关的技术支持和交流。
该文档的标识符为NLPIR-ICTCLAS-2013-WHITEPAPER,版本号为V4.0,安全性级别为Public(公开),意味着任何人都可以访问和使用。文档状态显示为创建和初步草案,用于评论,作者是张华平,发布日期为2013年12月19日。文档的版本历史管理严谨,每个版本增加0.1,只有当有重大变化时才会更新版本号,例如根据评审意见进行的修改。
NLPIR/ICTCLAS2015分词系统在设计上考虑了可扩展性和灵活性,可能采用了统计学习方法,如基于概率的模型或深度学习模型,来提高分词的准确性。这些方法通常包括HMM(隐马尔科夫模型)、CRF(条件随机场)或者更现代的LSTM(长短期记忆网络)等神经网络模型。分词系统可能还包含了词典和规则相结合的策略,既能处理常见词汇,又能应对未登录词的识别。
在实际应用中,NLPIR/ICTCLAS2015可能广泛应用于新闻分析、社交媒体监控、搜索引擎优化、情感分析等多种场景,尤其是在处理大量中文文本数据时,其高效的处理能力和准确的分词结果显得尤为重要。通过接口调用,开发者可以将NLPIR系统集成到自己的应用程序中,实现对中文文本的预处理,从而提升后续NLP任务的性能。
NLPIR/ICTCLAS2015是面向中文自然语言处理的开源分词系统,提供了详细的开发文档,方便开发者进行二次开发和应用,对于研究和应用中文文本处理的人员具有很高的价值。
NLPIR/ICTCLAS2015 分词系统开发文档 http://ICTCLAS.nlpir.org
NLPIR Copyright © 2015 Kevin Zhang. All rights reserved. 10/55
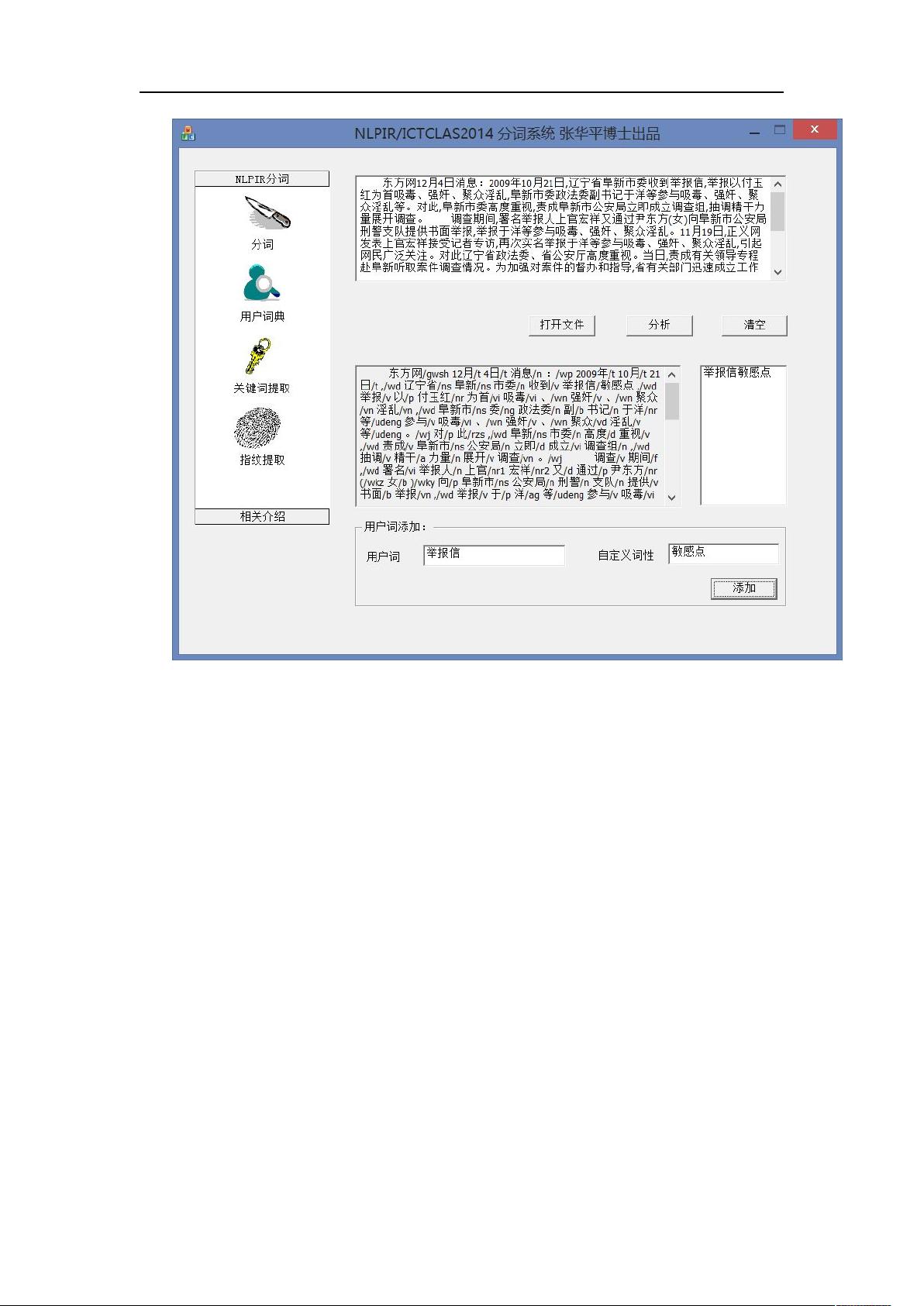
图 5:判别用户定义词“举报信”,设置为自定义词性“敏感点”
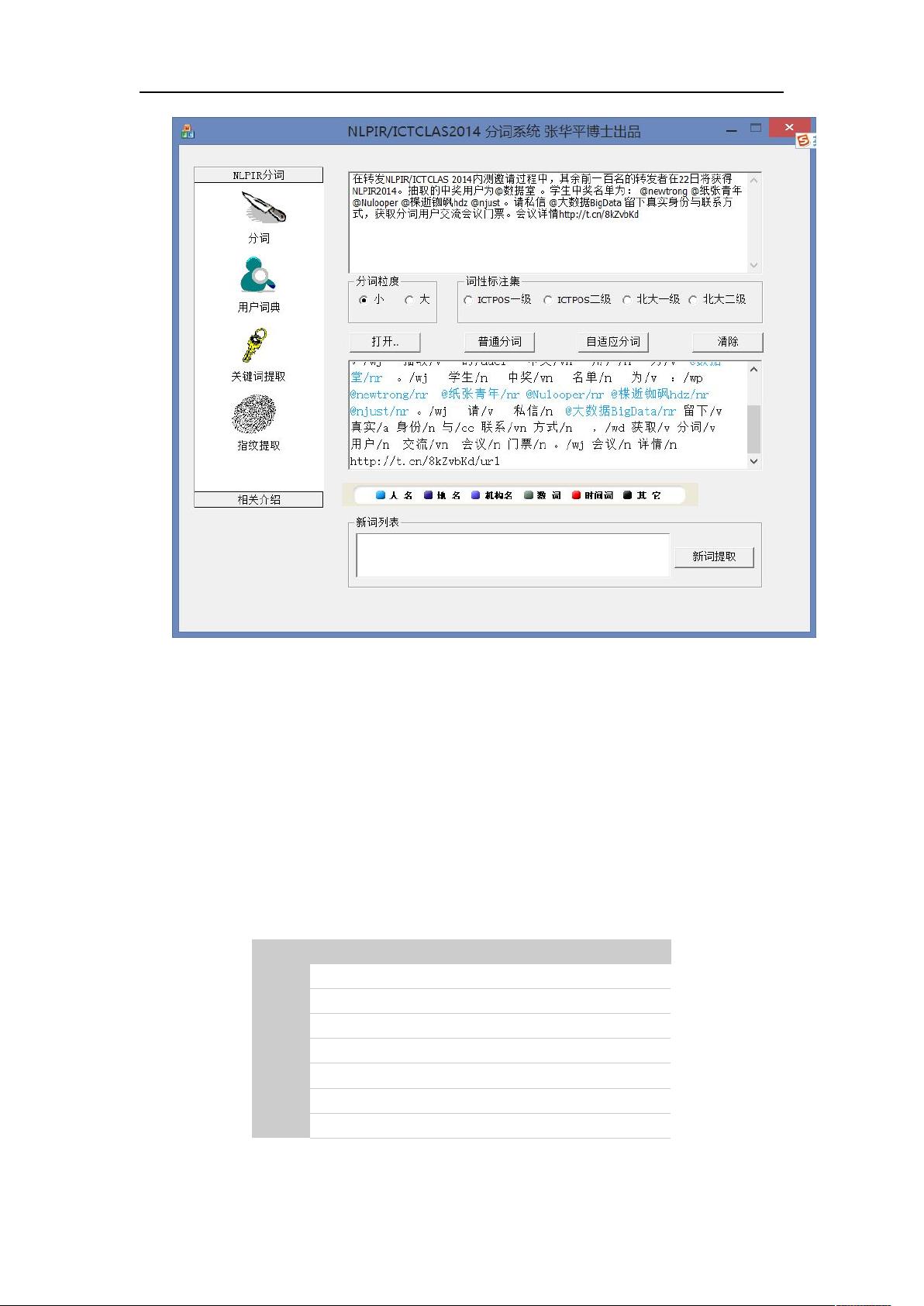
5)微博分词功能
对博主 ID 进行 nr 标示,对转发的会话进行自动分割标示(标示为 ssession),
URL 以及 Email 进行自动标引。
剩余54页未读,继续阅读
2022-08-03 上传
2014-08-04 上传
2022-08-03 上传
2023-09-27 上传
2023-07-29 上传
2024-04-12 上传
2023-05-10 上传
2023-07-15 上传
2023-05-20 上传

石悦
- 粉丝: 19
- 资源: 285
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
