
三次简化一张图: 一招理解 LSTM/GRU 门控机制
张皓
zhangh0214@gmail.com
引言
RNN 是深度学习中用于处理时序数据的关键技术, 目前已在自然语言处理, 语音识别, 视
频识别等领域取得重要突破, 然而梯度消失现象制约着 RNN 的实际应用. LSTM 和 GRU 是
两种目前广为使用的 RNN 变体, 它们通过门控机制很大程度上缓解了 RNN 的梯度消失问
题, 但是它们的内部结构看上去十分复杂, 使得初学者很难理解其中的原理所在. 本文介
绍”三次简化一张图”的方法, 对 LSTM 和 GRU 的内部结构进行分析. 该方法非常通用, 适
用于所有门控机制的原理分析.
预备知识: RNN
RNN (recurrent neural networks, 注意不是 recursive neural networks)提供了一种
处理时序数据的方案. 和 n-gram 只能根据前 n-1 个词来预测当前词不同, RNN 理论上可
以根据之前所有的词预测当前词. 在每个时刻, 隐层的输出 h
t
依赖于当前词输入 x
t
和前一
时刻的隐层状态 h
t-1
:
其中:=表示"定义为", sigm 代表 sigmoid 函数 sigm(z):=1/(1+exp(-z)), W
xh
和 W
hh
是
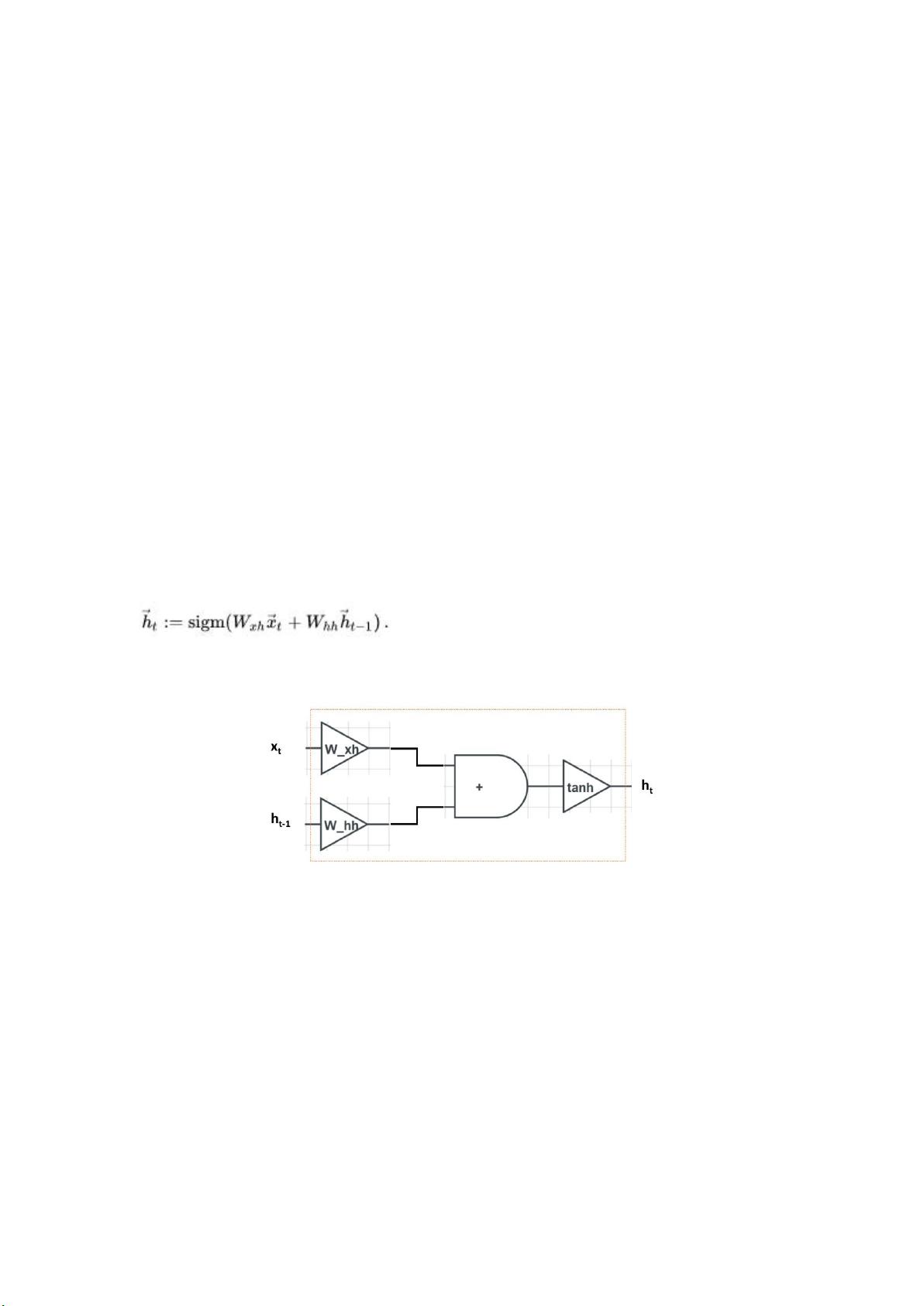
可学习的参数. 结构见下图:
图中左边是输入, 右边是输出. x
t
是当前词, h
t-1
记录了上文的信息. x
t
和 h
t-1
在分别乘以
W
xh
和 W
hh
之后相加, 再经过 tanh 非线性变换, 最终得到 h
t
.
在反向传播时, 我们需要将 RNN 沿时间维度展开, 隐层梯度在沿时间维度反向传播时需要
反复乘以参数 . 因此, 尽管理论上 RNN 可以捕获长距离依赖, 但实际应用中, 根据 谱
半径(spectral radius)的不同, RNN 将会面临两个挑战: 梯度爆炸(gradient explosion)
和梯度消失(vanishing gradient). 梯度爆炸会影响训练的收敛, 甚至导致网络不收敛; 而
梯度消失会使网络学习长距离依赖的难度增加. 这两者相比, 梯度爆炸相对比较好处理, 可
以用梯度裁剪(gradient clipping)来解决, 而如何缓解梯度消失是 RNN 及几乎其他所有深
度学习方法研究的关键所在.
下载后可阅读完整内容,剩余4页未读,立即下载

KaMen-nk
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Flex垃圾回收与内存管理:防止内存泄露
- Python编程规范与最佳实践
- EJB3入门:实战教程与核心概念详解
- Python指南v2.6简体中文版——入门教程
- ANSYS单元类型详解:从Link1到Link11
- 深度解析C语言特性与实践应用
- Gentoo Linux安装与使用全面指南
- 牛津词典txt版:信息技术领域的便捷电子书
- VC++基础教程:从入门到精通
- CTO与程序员职业规划:能力提升与路径指南
- Google开放手机联盟与Android开发教程
- 探索Android触屏界面开发:从入门到设计原则
- Ajax实战:从理论到实践
- 探索Android应用开发:从入门到精通
- LM317T稳压管详解:1.5A可调输出,过载保护
- C语言实现SOCKET文件传输简单教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


