MapReduce:分布式计算模型详解
需积分: 10 102 浏览量
更新于2024-07-29
收藏 1.12MB PDF 举报
"MapReduce概述——暨南大学信息科技学院07级研究生周敏,2008年"
本文是一篇关于MapReduce的综述性文献,由周敏于2008年撰写,主要探讨了分布式计算的背景、MapReduce的基本原理以及不同实现方式,并对相关案例进行了分析和对未来进行了展望。
1. 分布式计算概述:
- 摩尔定律:随着计算机技术的发展,芯片处理能力每18个月翻一番,这导致了数据量的爆炸式增长,需要更高效的处理方式。
- 免费的午餐:在处理大数据时,通过分布式计算可以利用多台计算机的并行处理能力,实现计算能力的叠加。
- 串行与并行编程:串行计算在单个处理器上执行,而并行计算则在多个处理器或计算节点上同时进行,以提高效率。
2. MapReduce基本原理:
- MapReduce是一种处理海量数据的编程模型,由Google提出,它将大规模数据处理分解为两个主要阶段:Map(映射)和Reduce(化简)。
- WordCount示例:展示了MapReduce如何统计文本中单词的出现次数,Map阶段将输入数据切分成键值对,Reduce阶段对相同键的值进行聚合。
3. MapReduce实现:
- Google的MapReduce实现:其内部细节是保密的,但知道它包括一个Master节点来协调任务,Worker节点执行实际工作,有良好的容错机制和任务调度策略。
- Apache Hadoop:开源社区的实现,用Java编写,提供了与Google MapReduce类似的框架,包括HDFS(分布式文件系统)和YARN(资源调度器)。
- Stanford的Phoenix系统:尝试将MapReduce应用于共享存储硬件平台,其API设计简化了编程,有独特的缓冲管理和并发控制策略。
4. 案例研究与未来展望:
- Google应用MapReduce处理搜索引擎索引、日志分析等任务。
- Lucene和Nutch(搜索引擎项目)利用MapReduce进行索引构建和更新。
- Yahoo!的M45和PIG:M45是大型集群,PIG是基于Hadoop的数据分析平台。
- Amazon的EC2(弹性计算云)和S3(简单存储服务)提供云计算基础设施,支持MapReduce运算。
- 未来展望:随着大数据和云计算的发展,MapReduce将进一步优化,如资源调度、容错机制和性能提升,同时新的计算模型如Spark、Flink等也在挑战MapReduce的地位。
这篇综述对理解MapReduce的基础概念和实际应用提供了全面的指导,对于想要深入研究分布式计算和大数据处理的读者具有很高的参考价值。
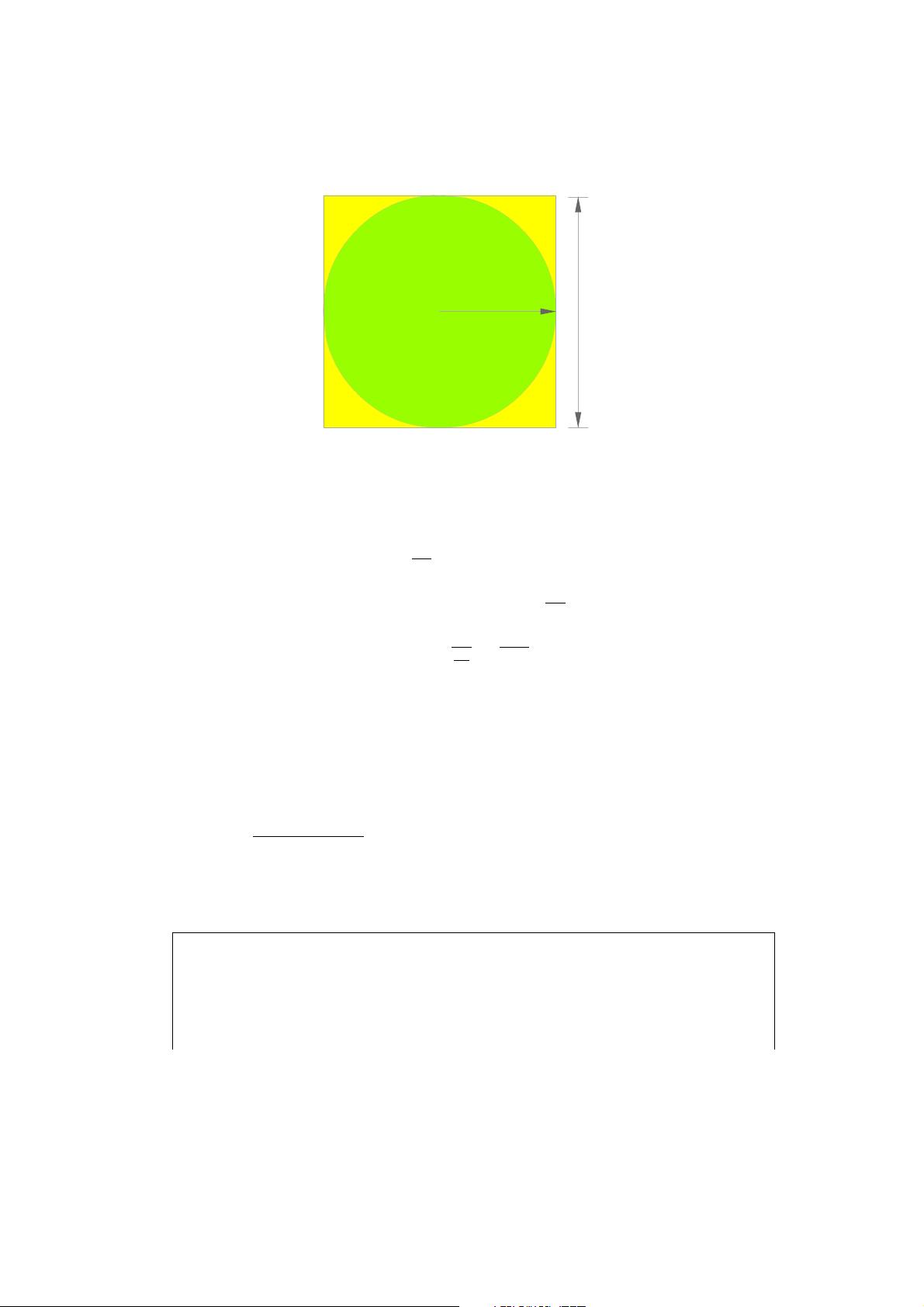
2 r
r
图 2: 计算π的值
为A
c
= πr
2
。所以:
π =
A
c
r
2
,
又A
s
= 4r
2
=⇒ r
2
=
A
s
4
,
=⇒ π =
A
c
A
s
4
=
4A
c
A
s
我们做这个代数推导的原因是我们可以按如下方法 让计算变得可并行
化:
1. 在正方形内随机地生成一些点
2. 计算这些点在圆形内的个数
3. p =
圆形内的点的个数
正方形内的点的个数
4. π = 4p
从而我们可以用下面的程序实现并行:
NUMPOINTS = 100000; // 数越大,越近似
n = worker的数目;
numPerWorker = NUMPOINTS / n;
worker:
5
剩余20页未读,继续阅读
2025-03-10 上传
2025-03-10 上传
2025-03-10 上传
2025-03-10 上传

cet5zs
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Clojure轻量级Testcontainers包装库使用指南
- Android版《是男人就下100层》游戏:一键导入运行指南
- C#实现WinForm记事本功能完全指南
- LaTeX模板:快速上手编写代码指南
- SQL代码存储库:管理与查看数据库结构
- Python自动化测试代码实现详解
- 绿色版Cisco TFTP服务器:IOS与配置备份利器
- 开源每日邮件阅读理解任务的RC-CNN模型分析
- Pads9.5电路设计工具光盘资料详解
- 探索首个信息技术项目的关键步骤
- MFC实现的经典魔塔游戏完整源码分享
- VSCode与jQuery集成安装包介绍与使用
- 微信小程序直播源码实现与应用分析
- Java开发者实践Docker:案例03详解
- 小米开源文件管理器源码解析
- Identity.Dapper: .NET核心中EntityFramework替代品的开源软件包
