我国小康指数SPSS数据分析报告
版权申诉
"我国各省小康指数基于SPSS的数据分析,涵盖了数据来源、数据处理、描述性统计分析、散点图绘制、多元回归分析和非参数检验分析。"
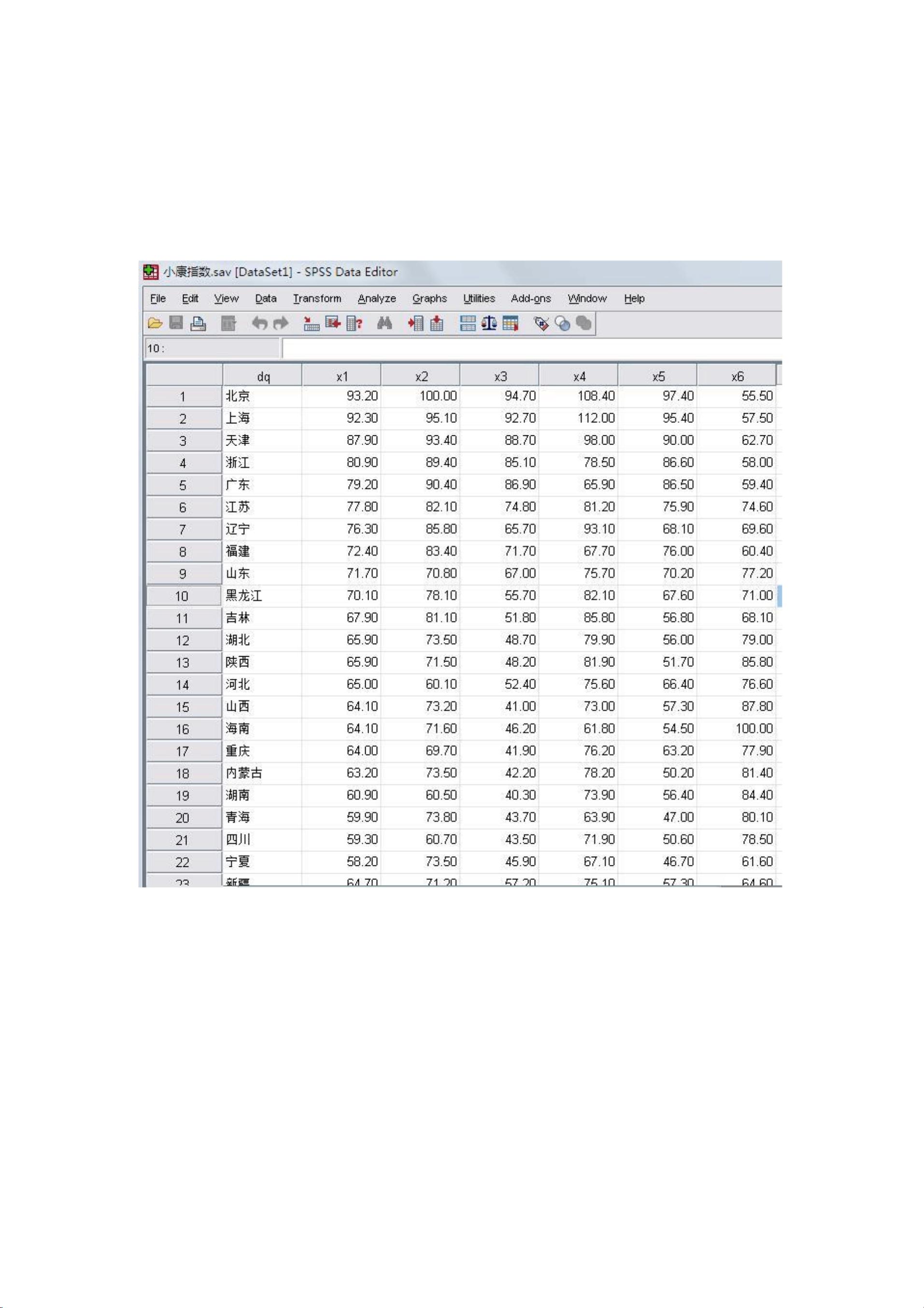
在本报告中,作者探讨了我国各省小康指数的SPSS数据分析,旨在理解不同因素如何影响各省的小康水平。数据来源未具体说明,但提及数据包含了多元变量,如经济技术、生活质量、社会结构和人口素质。
在数据处理阶段,首先进行了数据排序以快速识别最大值和最小值以及异常值。接着,通过分组和频数分析对数据进行了离散化处理,以便初步了解数据分布。由于涉及的是多元变量分析,SPSS被用于执行描述性统计分析、多元线性回归和非参数检验。
描述性统计分析(EXAMINE命令)用于计算变量的统计量,如平均值、百分位数、标准差等,并进行箱线图、茎叶图等可视化分析,以评估数据的集中趋势和分布形态。例如,表3-1的散点图揭示了社会结构与小康指数之间的关系,而表3-2的离散正态概率分布图则暗示人口素质与小康指数的相关性可能不符合正态分布。
接下来的多元线性回归分析旨在探究这些变量(如经济技术、生活质量、社会结构和人口素质)如何共同影响居民的小康指数。这种分析方法能估计各变量对因变量(小康指数)的权重,从而理解哪些因素对小康水平的影响最为显著。
非参数检验分析则用于处理可能不遵循正态分布的数据,提供了一种不依赖于数据分布假设的统计检验,可能包括Mann-Whitney U检验、Kruskal-Wallis H检验等,以检测不同群体间是否存在显著差异。
报告的最后部分总结了分析结果,强调了各个因素对小康指数的影响程度,指出社会结构、人口素质、生活质量和技术经济发展在构建全面小康社会中的重要作用。然而,具体的回归模型和非参数检验结果未在提供的内容中详述,这部分分析可能包含系数、显著性水平和其他统计指标,以深入理解变量间的关联性。
这份报告通过严谨的SPSS数据分析,提供了对我国小康社会建设现状的深入洞察,为政策制定者和研究者提供了有价值的参考信息。
关于我国小康指数的 spass 数据分析
一. 数据来源
二、数据的处理及选用分析方法简述
在数据文件建立好后, 通常还需要对待分析的数据进行必要的预加工处理 , 首先,
为了便于数据的浏览, 快捷的找到数据的最大值和最小值, 同时,快捷的发现数
据的异常值, 先将数据按照降序重新进行排列; 其次,为了粗略的把握数据的分
布,实现数据的离散化处理和对数据进行频数分析, 和对数据进行频数分析, 利
用 spss 软件中的分组功能对数据进行简单的分组 。鉴于本案例所涉及的变量为
剩余10页未读,继续阅读
2021-11-11 上传
2021-07-14 上传
2019-08-27 上传
2018-09-15 上传
2012-11-30 上传
2009-11-29 上传
2021-11-28 上传

jh035511
- 粉丝: 0
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- java中MyEclipse快捷大全.pdf
- Java开源项目Hibernate快速入门
- 现代电子技术基础(数电部分)课后习题答案 第二章
- 用户界面设计分析文档
- AnyData 无线模块,AT指令全集【MODEM专用】
- asp新闻发布系统daima
- linux驱动编程(LED3)
- dx的入门pdf文件
- arm 片上系统设计要点
- javaScript语言精髓和编程实践迷你书
- Asp.net数据库常用的Sql操作
- 3G技术讲解.pdf 3G技术讲解.pdf
- javabean操作数据库
- 直驱永磁同步风力发电机的最佳风能跟踪控制[1]
- Thinking in C++ 02.pdf
- JSF in action(英文完整版)
