Tiny语言词法分析程序实现与指南
需积分: 0 164 浏览量
更新于2024-08-04
收藏 265KB DOCX 举报
"Tiny词法分析程序实验指导手册1提供了Tiny语言的词法规则和相应的词法分析程序实现。"
Tiny语言的词法规则通常包括不同的符号和结构,如标识符(identifier)、赋值操作符、数字(number)、注释以及保留关键字。在这个实验中,词法分析程序的目标是识别这些元素并将其转换为相应的标记(token)以便于后续的语法分析。词法分析是编译器或解释器的第一步,它将源代码分解成一个个有意义的单元,即词法单元。
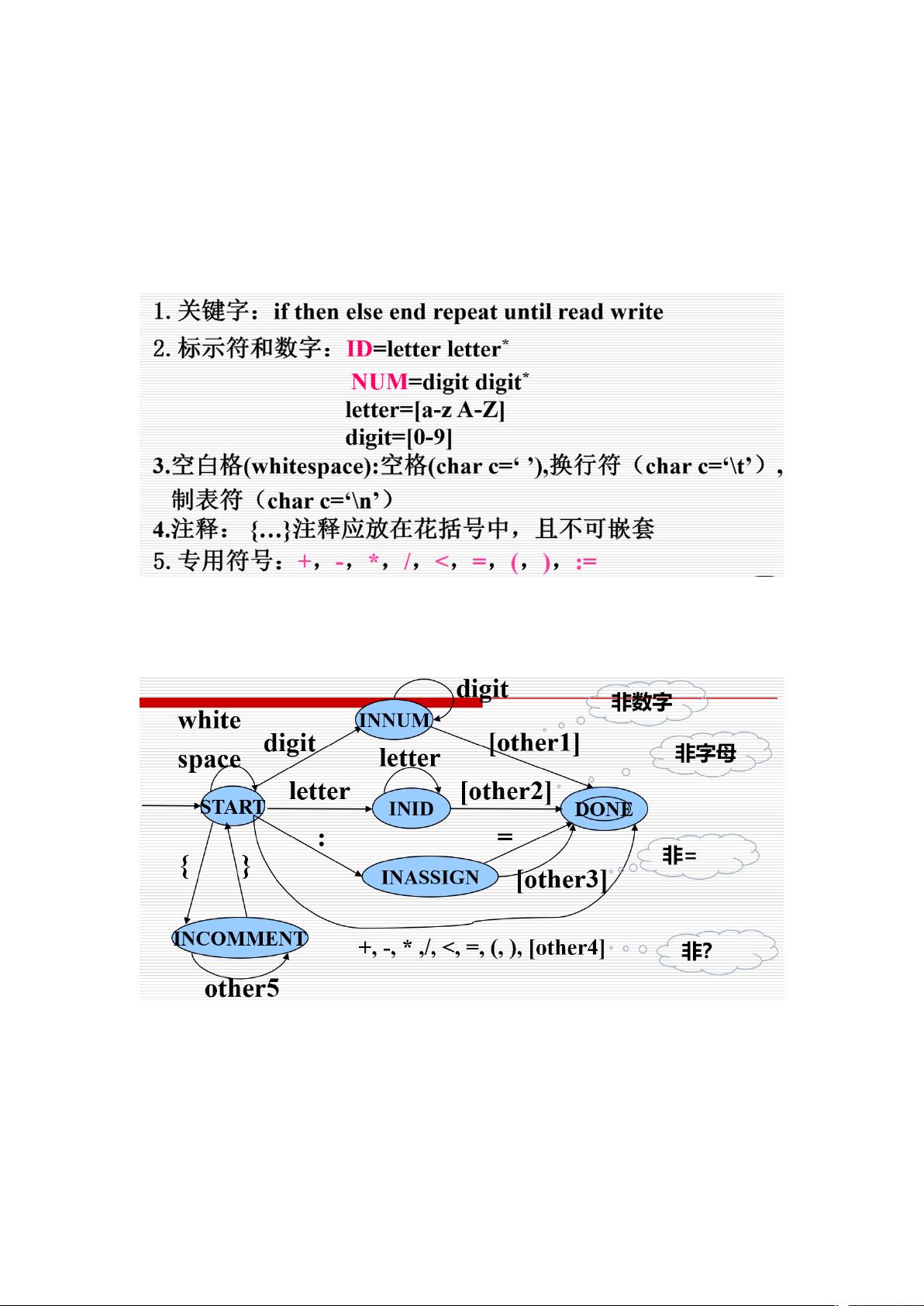
Tiny语言的词法规则对应的确定性有穷自动机模型(DFA,Deterministic Finite Automaton)是一种状态机,用于识别输入字符串中的模式。DFA由一系列状态组成,每个状态代表了在处理输入字符串时可能遇到的不同情况。例如,`START`状态可能是初始状态,`INASSIGN`可能表示正在处理赋值操作符,`INNUM`表示读取数字,`INID`用于处理标识符,而`DONE`则表明词法分析过程已经完成。
在提供的`Scan.h`和`Scan.c`文件中,`Scan.h`定义了词法分析的接口,包括`getToken()`函数,该函数负责从源文件中获取下一个词法单元。`MAXTOKENLEN`常量定义了最大标记长度,`tokenString`数组用于存储每个词法单元的文本形式。`Scan.c`包含了词法分析的具体实现,它可能包含处理不同状态的逻辑,并且通过调用`getToken()`函数来实现对源代码的逐字符扫描。
`TokenType`是用于表示不同类型的词法单元的枚举类型,可能包括`ID`(标识符)、`ASSIGN`(赋值操作符)、`NUMBER`(数字)、`COMMENT`(注释)以及其他可能的保留关键字。在`Scan.c`的实现中,`StateType`枚举用于跟踪词法分析过程中的当前状态。
在词法分析过程中,`getState()`和`setState()`等辅助函数可能会用来根据输入字符动态地切换状态。例如,当读取到字母或数字时,状态可能会从`START`变为`INID`或`INNUM`;遇到等号(=)时,状态可能切换到`INASSIGN`;如果遇到`/`和`*`组合,可能进入`INCOMMENT`处理多行注释。
为了实现词法分析,程序会逐个读取源文件的字符,根据DFA的状态转移规则进行判断。一旦识别出一个完整的词法单元,如一个标识符或数字,`getToken()`函数就会返回对应的标记类型,同时清理`tokenString`以便存储下一个词法单元。
Tiny语言的词法分析程序通过确定性有穷自动机模型实现,能够有效地识别源代码中的各种元素,为编译器或解释器的后续步骤提供基础。这个实验旨在帮助学生理解词法分析过程及其在编译原理中的作用。
Tiny 词法分析程序撰写示例
Tiny 语言的词法
Tiny 语言的词法规则对应的确定性有穷自动机模型
基于自动机模型的 Tiny 语言的词法程序如下:
Scan.h
/****************************************************/
下载后可阅读完整内容,剩余9页未读,立即下载
798 浏览量
5042 浏览量
2022-08-03 上传
2025-01-24 上传
2022-08-04 上传
145 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

乐居买房
- 粉丝: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 实现文字与图片无缝滚动效果的js技巧
- 使用Microsoft USMT和PowerShell GUI工具迁移Windows用户配置文件
- 《语义万维网:工程实践指南》第2版深入解析
- Packer插件实现Windows更新安装自动化
- 完全使用HTML和CSS复刻的下一个网站范例
- 蓝色WAP手机旅游网站模板源码解析与应用
- 体验在线JSON编辑器:JSONeditor的便捷之道
- 掌握Linux输出重定向:学习与之间的区别
- Android实现不规则瀑布流布局效果
- Jupyter笔记本仓库:算法、机器学习与日常日记管理
- Qt在CentOS 7环境下实现文件对话框实例教程
- 2005年哈工大通信工程电子考研复试题解析
- Twitch聊天叠加工具开发指南
- Microsoft Press出品HTML5学习教程英文版
- WAPEQ 1.4:WAP建站系统源代码及多技术项目资源
- js文字滚动插件:实现公告列表文字自动上下滚动效果
