MFS分布式文件系统详解:原理、搭建与维护
需积分: 12 90 浏览量
更新于2024-09-09
收藏 394KB DOC 举报
"MFS分布式文件系统"
MFS( Massive File System)是一种分布式文件系统,它通过将文件数据分散存储在多个物理服务器上,提供给用户一个统一的访问接口,从而实现高可用性、数据容灾和性能提升。分布式文件系统的概念是基于网络连接的存储资源,使得文件可以跨越不同地理位置的设备进行访问,简化了用户管理和访问的过程。
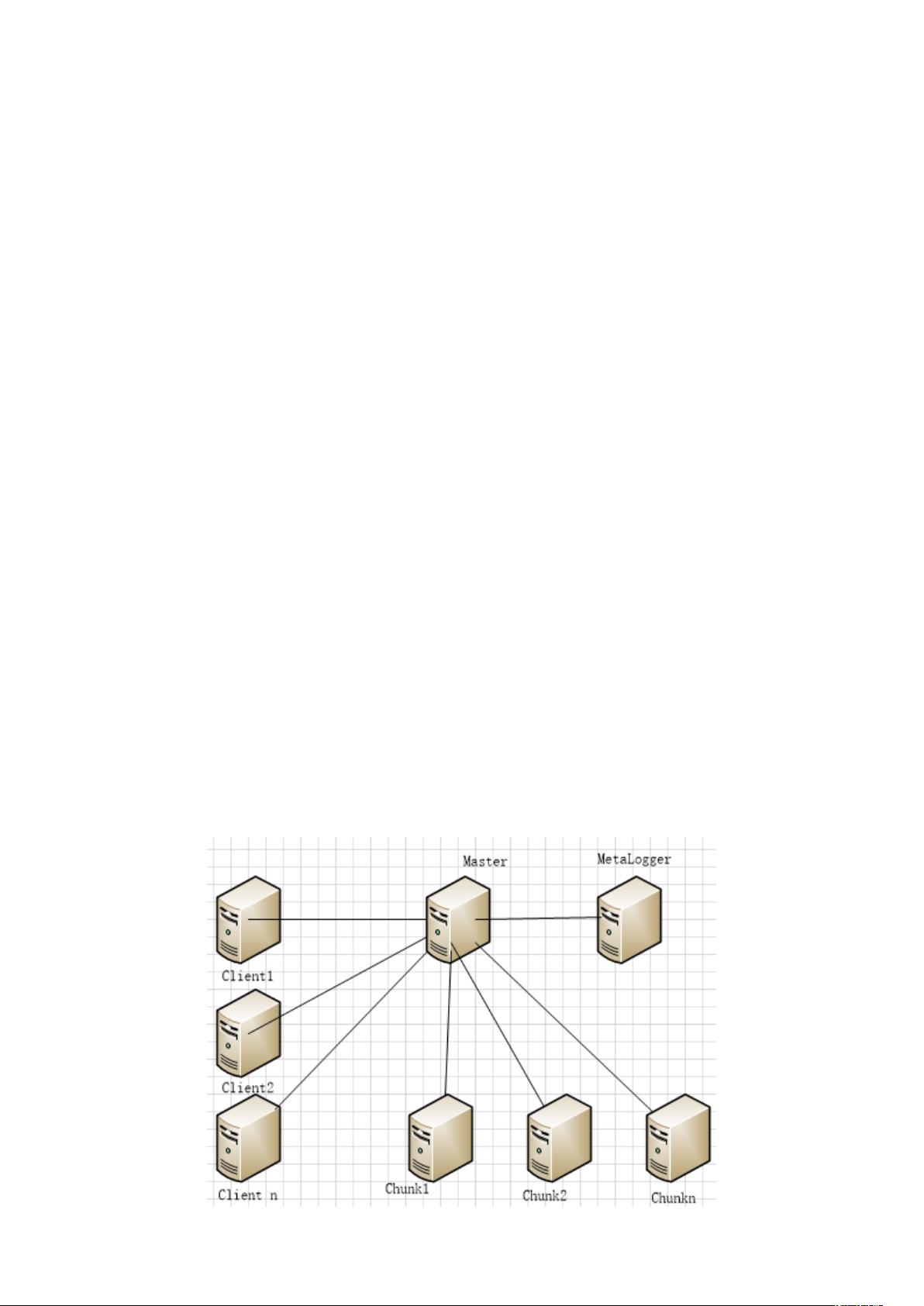
MFS的运行原理主要包括以下几个关键组件:
1. 元数据服务器(Master):作为整个系统的核心,管理文件系统的元数据,如文件路径、权限、文件与数据块的映射关系等。尽管当前设计只支持单个Master,但为了防止单点故障,通常会配置高可用的Master服务器。
2. 元数据日志服务器(MetaLogger):备份Master服务器的所有变更日志,以便在Master出现故障时,能够从中恢复元数据。
3. 数据存储服务器(Chunk Server):实际存储文件内容的节点,将大文件分割成多个数据块(chunks)进行存储,并在多个Chunk Server之间进行冗余备份,以提高数据的可靠性和系统的整体性能。
4. 客户端(Client):用户可以通过客户端程序挂载MFS,就像挂载传统的NFS文件系统一样,进行文件的读写操作。
MFS的数据处理流程如下:
- **读取过程**:客户端向Master请求文件的某个部分,Master返回包含数据块位置(Chunk Server的IP地址和Chunk编号)的信息,客户端随后直接从指定的Chunk Server获取数据。
- **写入过程**:客户端向Master发送写入请求,Master协调Chunk Server创建或选择合适的空闲数据块,Chunk Server确认后,Master通知客户端可以将数据写入哪些Chunk Server,最后客户端将数据写入指定的Chunk Server。
MFS的设计目标是为了在大规模集群环境中提供高效、可靠的文件存储解决方案。通过数据的分布式存储和冗余备份,MFS能够有效应对硬件故障,确保数据安全,并通过负载均衡提高文件存取性能。同时,通过元数据服务器的集中管理,简化了文件系统的运维工作,方便进行监控和维护。
为了确保系统的稳定运行和数据的完整性,还需要实施定期的MFS监控,检查Master、MetaLogger和Chunk Server的状态,以及网络连接的稳定性。此外,建立完善的灾难恢复计划,包括定期备份元数据、数据块的复制策略以及在主Master故障时的快速切换机制,都是MFS系统管理的关键环节。
MFS 分布式文件系统
1)分布式原理:
分布式文件系统是指文件系统挂历的物理存储资源不一定直接连接在本地
节点上,而是通过计算机网络与节点连接。简单来说就是把一些分散的
(分布在局域网内各个计算机上)共享文件夹,集合到一个文件夹内(虚
拟共享文件夹)。对用户来说,要访问这些共享文件夹是,只要打开这个
虚拟共享文件夹,就可以看到所有链接到虚拟共享文件夹的共享文件夹,
用户感觉不到这些共享文件是分散到各个计算机上的,分布式文件系统的
好处是集中访问、简单操作、数据容灾、提高文件存取性能。
2)MFS 原理:
MFS 是以恶搞具有容错性的网络分布式文件系统,它把数据分散存放在多
个物理服务器上,而呈现给用户的则是一个统一的资源。
(1)MFS 文件系统的组成
元数据服务器(Master):在整个体系中负责管理文件系统,维护元数据 ,
目前版本只支持单个 Master 服务器,存在单点故障的风险,建议采用性能稳定
的服务器充当。
元数据日志服务器(MetaLogger):备份 Master 服务器的变化日志文件,
文件类型为 changelog_ml.*.mfs。当 Master 服务器丢失或者损坏,可以从日志
服务器中取得文件恢复。
数据存储服务器(Chunk Server):真正存储数据的服务器,存储文件时,
会把文件分块保存,并在数据服务器之间复制,数据服务器越多,能使用的“容
量”就越大,可靠性就越高,性能越好。
客户端(Client):可以挂载 NFS 一样挂在 MFS 文件系统,其操作是相同
的。
下载后可阅读完整内容,剩余8页未读,立即下载
313 浏览量
点击了解资源详情
点击了解资源详情
2009-12-07 上传
259 浏览量
118 浏览量
199 浏览量
点击了解资源详情

LinuxStory
- 粉丝: 3
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- js-drum-machine
- 南京某高层住宅小区工程施工组织设计(剪力墙结构).zip
- PrimoCache v3.09
- 20个2.5d 人工智能AI相关图标 .ai素材下载
- parallel-service-controller:Bourne Shell脚本可同时控制多个服务
- 装置的检验程序-第1部分静态称重系统.rar
- jdkapi18chm .zip
- react-native-nlist:原生Listview原生lListView react-native封装内存恢复重用高性能
- 远程控制四路继电器开关-电路方案
- Rick-and-morty-NextJS:在NextJS中构建Rick and morty项目
- angular-php-api
- django-newsfeed:Django的新闻策展人和新闻通讯订阅包
- 28DaysLater
- SVN安装包.rar
- 书法控笔训练-包含40页.zip
- 高维数据研究
