"基于BERT的自动化微博情绪分类技术报告:模型融合取得第一名"
需积分: 0 31 浏览量
更新于2024-01-19
收藏 918KB PDF 举报
Tencent-SMP2020-EWECT评测技术报告1总结
本报告旨在总结微博情绪分类任务参赛方基于BERT等预训练模型所采用的训练策略和方法,并呈现其在SMP2020-EWECT微博情绪分类评测中取得的成果。
在微博情绪分类任务中,参赛方以自动化的方式进行训练,通过随机选择和组合增量预训练、半监督学习、对抗训练、数据增强、模型融合等策略,训练出了一系列具有低偏差-高方差的分类模型。这些模型在无需过多人工介入的情况下,针对不同的训练数据进行训练,以期获得更好的性能。
通过深层模型融合,参赛方将训练好的模型进行整合,在通用微博数据集和病毒微博数据集上分别取得了0.7856和0.7078的分数,排名第一。这说明参赛方采用的训练策略和方法在微博情绪分类任务上取得了显著的成绩。
关键词:自然语言处理,情感分析,预训练模型,模型融合
1. 引言
微博情绪分类任务是为了识别微博中所包含的情绪而设立的,输入是一条微博,输出是该微博所蕴含的情绪类别。本次评测中,微博情绪被分为六个类别:积极、愤怒、悲伤、恐惧、惊奇和无情绪。微博情绪分类评测任务共包含两个测试集:一个是通用微博数据集,其中的微博是随机收集的,包含了各种不同情绪的微博;另一个是病毒微博数据集,其中的微博是与疫情相关的。
2. 训练策略和方法
参赛方基于BERT等预训练模型,采用了一系列训练策略和方法,包括增量预训练、半监督学习、对抗训练、数据增强和模型融合。
增量预训练:参赛方随机选择部分数据进行增量预训练,通过利用更多的训练数据进行预训练,提高模型的泛化能力和性能。
半监督学习:参赛方利用未标注的数据进行半监督学习,将未标注的数据也纳入训练过程,扩大了训练数据集,提升了模型的表现。
对抗训练:参赛方引入对抗训练,通过生成对抗网络的训练,使得模型对输入微博的干扰更加鲁棒,提高了分类的准确性。
数据增强:参赛方通过各种方法对训练数据进行增强,如同义词替换、句子重组等,增加了训练数据的多样性,使得模型能够更好地处理各种输入情况。
模型融合:参赛方将训练好的多个模型进行融合,通过投票、加权等方式综合利用各个模型的预测结果,提高了整体性能。
3. 结果
经过训练策略和方法的应用,参赛方在SMP2020-EWECT微博情绪分类评测中取得了显著的成绩。在通用微博数据集上,参赛方的模型获得了0.7856的分数,在病毒微博数据集上获得了0.7078的分数,两者均排名第一。这表明参赛方采用的训练策略和方法对于微博情绪分类任务具有很好的效果。
4. 总结
通过本次评测,参赛方基于BERT等预训练模型,运用增量预训练、半监督学习、对抗训练、数据增强和模型融合等多种训练策略和方法,成功训练了一系列具有低偏差-高方差的情绪分类模型。这些建模方法在无需过多人工介入的情况下,能够自动化地训练大量高性能的分类模型。通过深层模型融合,参赛方在通用微博数据集和病毒微博数据集上取得了优异的成绩,证明了训练策略和方法的有效性。这对于微博情绪分类任务的研究和实践具有一定的参考价值。
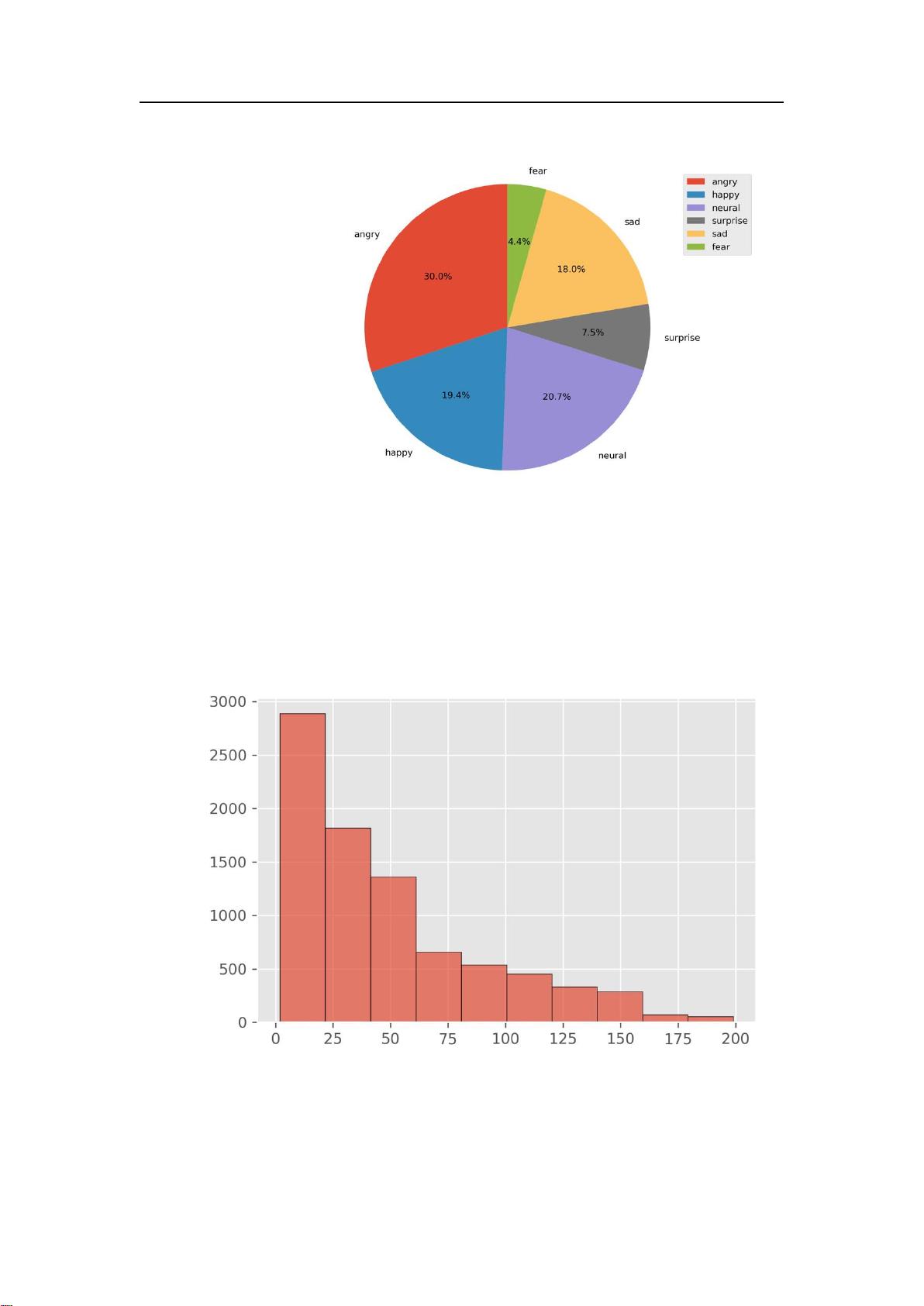
SMP2020-EWECT 微博情绪分类评测
4
图 2 usual 标签分布
图 3 virus 长度分布
剩余16页未读,继续阅读
2022-08-08 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传

我要WhatYouNeed
- 粉丝: 46
- 资源: 287
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
