Storm分布式流计算框架详解
需积分: 10 194 浏览量
更新于2024-07-24
收藏 345KB PPTX 举报
"Storm是一个实时分布式计算框架,它提供了高容错性和可扩展性,能够处理大规模数据。与Hadoop MapReduce相比,Storm更注重实时处理,确保所有数据都能得到及时处理。本文将概述Storm的技术架构,包括Nimbus、Supervisor、Zookeeper以及Topology等关键概念,帮助读者理解和学习Storm的基础知识。"
Storm的核心特性在于它的实时计算能力,这与Hadoop的批量处理模式有所不同。Hadoop MapReduce适合离线大数据分析,而Storm则适用于需要实时响应的场景,例如在线数据分析、实时日志处理、连续计算等。
**技术架构**
1. **Nimbus**: 类似于Hadoop的JobTracker,Nimbus是Storm集群的主节点,负责任务调度和监控。它会将工作分配给各个Supervisor,并处理故障恢复。但需要注意的是,Nimbus存在单点故障的风险。
2. **Supervisor**: 在工作节点上运行的进程,负责接收Nimbus的任务分配,并启动或停止Worker进程来执行具体的工作。每个Supervisor管理一部分Task,构成一个拓扑结构的子集。
3. **Zookeeper**: Storm依赖Zookeeper作为协调服务,保证Nimbus和Supervisor之间的通信稳定,实现分布式协调。
4. **Worker**: 运行在Supervisor上的工作进程,每个Worker负责执行一个或多个Task。
5. **Topology**: 是Storm中的核心概念,代表着实时应用程序的逻辑结构,由Spout和Bolt组成,通过StreamGroupings连接形成数据流。Topology可以看作是实时计算逻辑的实现,是Storm的最高抽象级别。
**Spout和Bolt**
- **Spout**: 数据源组件,负责产生数据流。它可以是从消息队列、数据库或其他数据源拉取数据,或者生成模拟数据。
- **Bolt**: 数据处理组件,执行各种计算操作,如过滤、聚合、转换等。Bolt可以连接多个Spout,形成数据处理管道。
**Tuple**: Storm中数据传输的基本单位,用于在Spout和Bolt之间传递消息。一个Tuple通常包含多个字段,这些字段可以被Bolt用来执行相应的操作。
**StreamGroupings**: 定义了Spout和Bolt之间数据流的分发方式,如shuffle grouping(随机分发)、fields grouping(按字段分发)等,决定了数据如何在拓扑中流动。
**应用实例**
以统计单词数量为例,一个简单的Topology可能包含一个Spout读取输入文本,然后通过一系列Bolt进行单词拆分、计数和结果聚合。
理解Storm的这些基本概念和机制后,开发者可以根据实际需求构建复杂的实时数据处理系统。Storm的灵活性和强大功能使其成为实时大数据处理领域的热门选择。
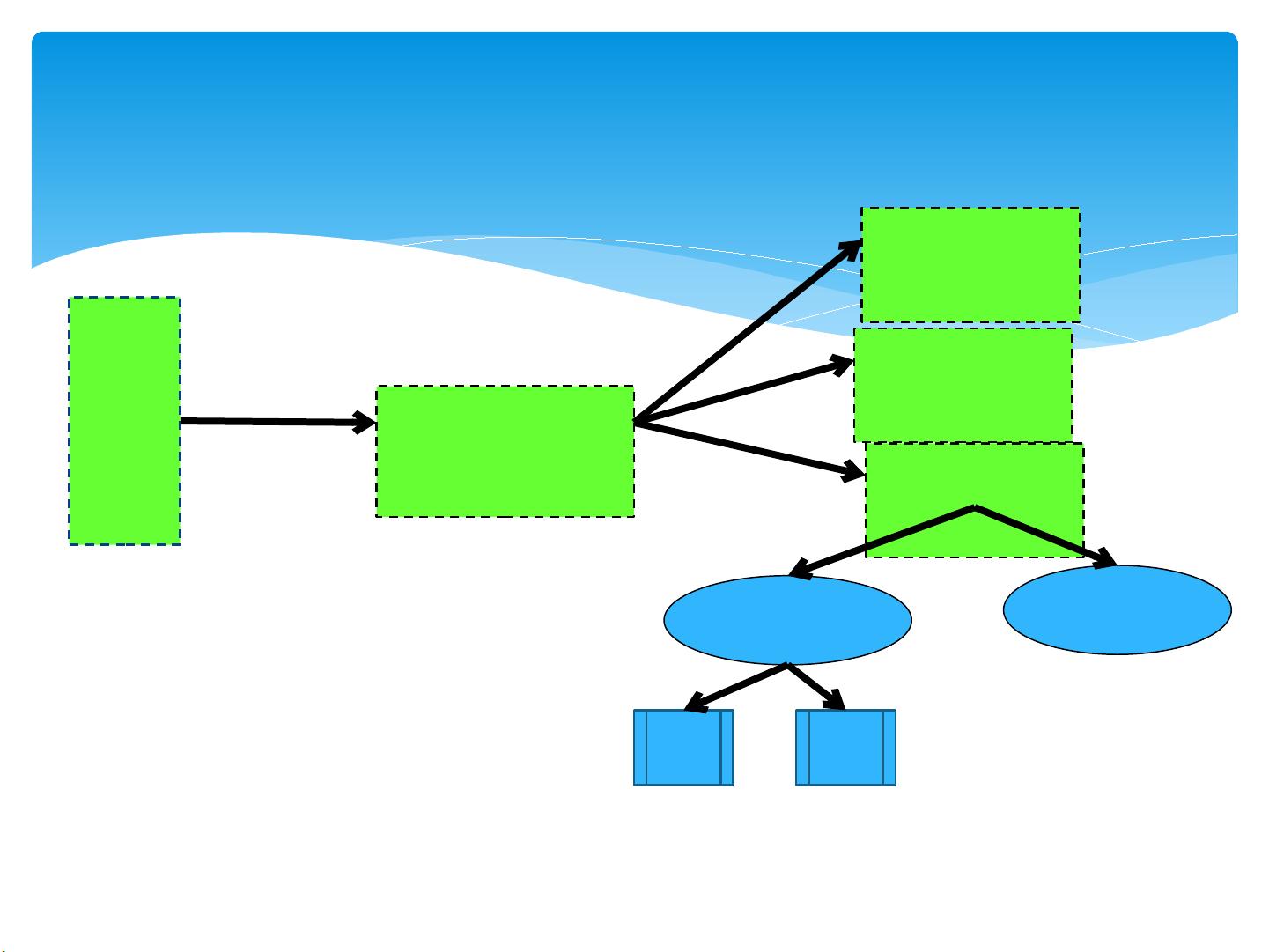
技术架构
nimbu
s
supervis
or
supervis
or
supervis
or
zookeep
er
…
…
Worker
Work er
主机: nimbus 、 zk 、 supervisor
Tas
k
Tas
k
部署与运行视图:
Zookeeper : Zookeeper 是完成 Supervisor 和 Nimbus 之间协调的服务。

剩余25页未读,继续阅读
2015-03-10 上传
2023-11-16 上传
2024-05-29 上传
2023-06-12 上传
2023-09-10 上传
2023-09-13 上传
2023-07-07 上传
2023-04-02 上传

wn1251559861
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
