Python实现神经网络:从基础到2D分类实战
200 浏览量
更新于2024-08-03
收藏 505KB PDF 举报
本资源主要介绍了机器学习中Python实现神经网络的实验,重点在于神经网络的基本概念和应用。实验旨在通过实践加深对神经网络模型原理的理解,包括决策树、信息熵和信息增益这些基础理论在神经网络中的作用。神经网络是一种模仿生物神经系统的数学模型,由大量的人工神经元连接而成,可以自适应地改变内部结构,非线性地处理数据。
实验的核心内容是构建一个2维平面的简单神经网络分类器,通过Python编程实现。在这个过程中,会涉及到神经网络的三个关键部分:
1. **结构** (Architecture): 网络中的变量如权重和神经元激励值的配置决定了网络的拓扑关系。例如,权重决定了神经元之间的连接强度,而激励值则反映了神经元的激活状态。
2. **激励函数** (Activity Rule): 这是神经元动态更新其激励值的规则,通常依赖于网络权重。比如常见的sigmoid函数或ReLU函数,它们将神经元的输入转换为输出。
3. **学习规则** (Learning Rule): 控制权重随着时间调整的策略,通常基于梯度下降或其他优化算法,通过比较预测输出和真实标签来更新权重,以最小化预测误差。
实验步骤包括数据预处理、神经网络模型设计、训练和测试。首先,通过Windows11系统和Python3.6.1版本运行环境,利用Jupyter作为编辑器,创建和导入所需的库,如numpy、matplotlib等。接着,生成并准备训练和测试数据,构建一个包含输入层、隐藏层和输出层的神经网络模型。然后,通过反向传播算法训练网络,调整权重,最后用训练好的模型对新数据进行分类并验证其性能。
通过这个实验,学习者不仅能掌握神经网络的实现方法,还能深入理解神经网络的工作原理,以及如何在实际问题中运用这种强大的机器学习工具进行数据分类。同时,对决策树和信息熵等理论的理解也有助于更好地解释和优化神经网络模型。
一、实验目的
1.理解神经网络的模型原理
2.掌握如何实现神经网络算法,并用其完成分类。
二、实验原理
决策树,信息熵,信息增益。
在机器学习和认知科学领域,人工神经网络(artificial neural network,
缩写 ANN),简称神经网络(neural network,缩写 NN)或类神经网络,是一种
模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型
或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进
行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一
种自适应系统。现代神经网络是一种非线性统计性数据建模工具。我们来了解一
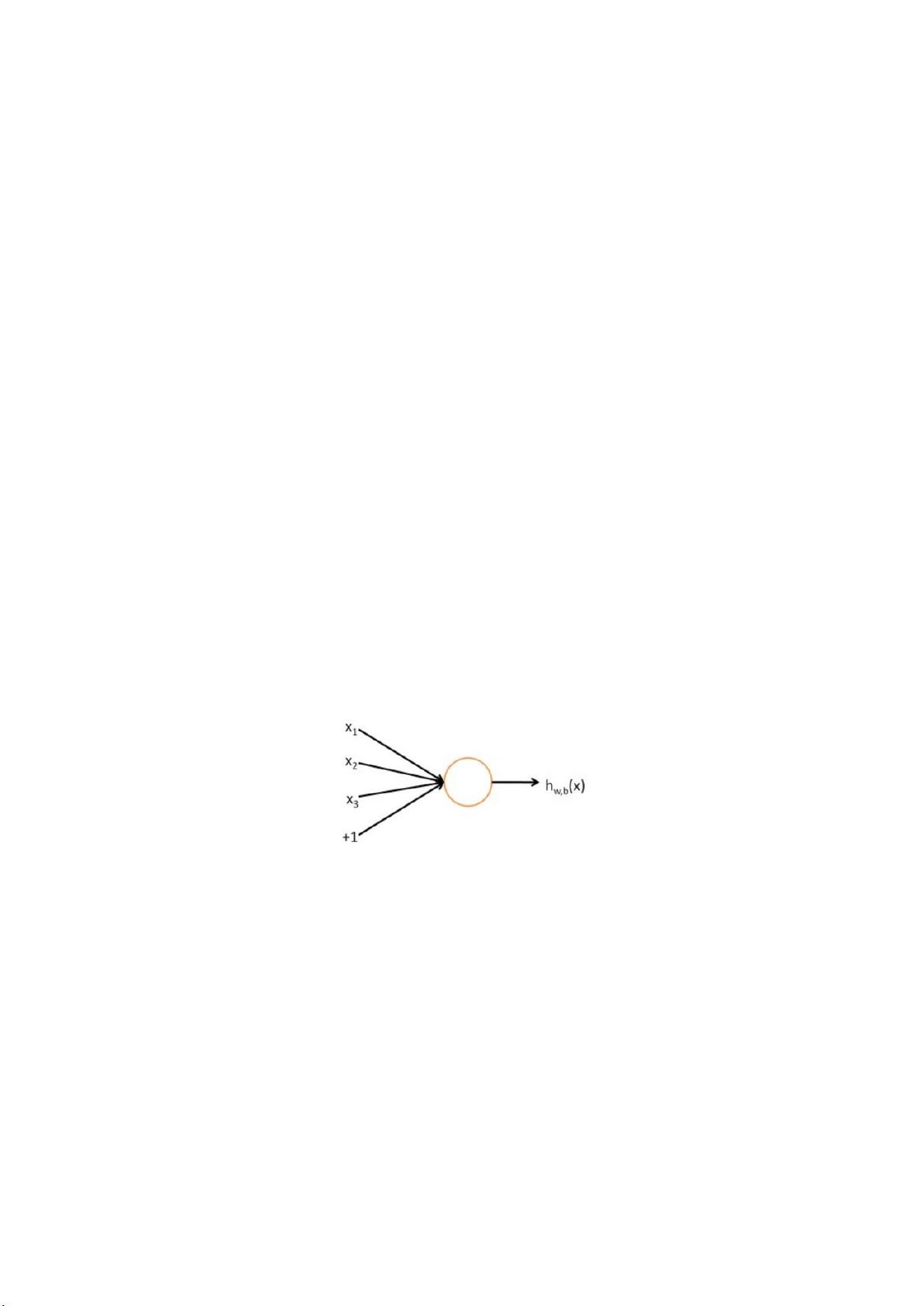
下什么是神经元:
其中,x1、x2、x3 代表输入,中间部分为神经元,而最后的 hw,b(x)是神经
元的输出。整个过程可以理解为输入——>处理——>输出。由多个神经元组成的
就是神经网络,如下图所示,这是一个 4 层结构的神经网络,layer1 为输入层,
layer4 为输出层,layer2,layer3 为隐藏层,即神经网络的结构由输入层,隐
藏层,输出层构成。其中除了输入层以外,每一层的输入都是上一层的输出。
下载后可阅读完整内容,剩余4页未读,立即下载
2024-07-16 上传
2022-04-14 上传
2021-02-03 上传
2021-05-25 上传
2024-05-21 上传
点击了解资源详情
2021-05-26 上传
2024-02-21 上传
2021-06-18 上传

小嘤嘤怪学
- 粉丝: 1515
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
