无监督图像翻译:自注意力与相对鉴别提升
版权申诉
112 浏览量
更新于2024-06-27
收藏 746KB DOCX 举报
图像翻译是一种计算机视觉任务,旨在将输入图像从一个领域转换为另一个领域的输出图像,例如风格转换、图片域适应和数据预处理。它主要依赖于生成对抗网络(GANs),如Pix2Pix和CycleGAN。Pix2Pix由Isola等人在2017年提出,采用条件GAN(CGAN)框架,利用U-Net作为生成器和PatchGAN作为判别器,进行有监督的图像转换,依赖于配对训练数据。
然而,有监督方法的局限性在于它需要大量的配对图像数据,这对于艺术风格转换等场景并不易得。因此,无监督图像翻译应运而生,如CycleGAN和UNIT。CycleGAN通过双生成器和判别器的对偶学习,以及循环重构一致性约束,实现无配对图像间的转换,仅改变目标图像域的特性,但可能会牺牲图像内容的完整性。
UNIT进一步改进了无监督学习,通过共享中间层网络权重,提取低维潜在向量,然后分别构建这些向量与每个图像域的映射,以增强对图像域之间关系的理解。这种方法能更好地保留图像内容结构,尽管无监督训练可能导致生成图像的质量和翻译效果有所欠缺。
问题主要体现在两个方面:一是生成器的卷积神经网络结构受限于卷积核大小,往往过度依赖局部信息,造成图像域转换不彻底,图像的协调性和真实性受到影响;二是由于缺乏目标图像域的精确指示,生成器可能在翻译过程中引入无关的图像特征,影响翻译效果。此外,GAN的博弈对抗中,生成器仅间接地依赖判别器的反馈,而未充分利用判别器区分真假图像的先验知识,这限制了模型性能的提升。
为了改善这些问题,研究人员正在探索更先进的网络架构、注意力机制的整合以及更有效的训练策略,以提高无监督图像翻译的精度和一致性,使之在实际应用中发挥更大的潜力。
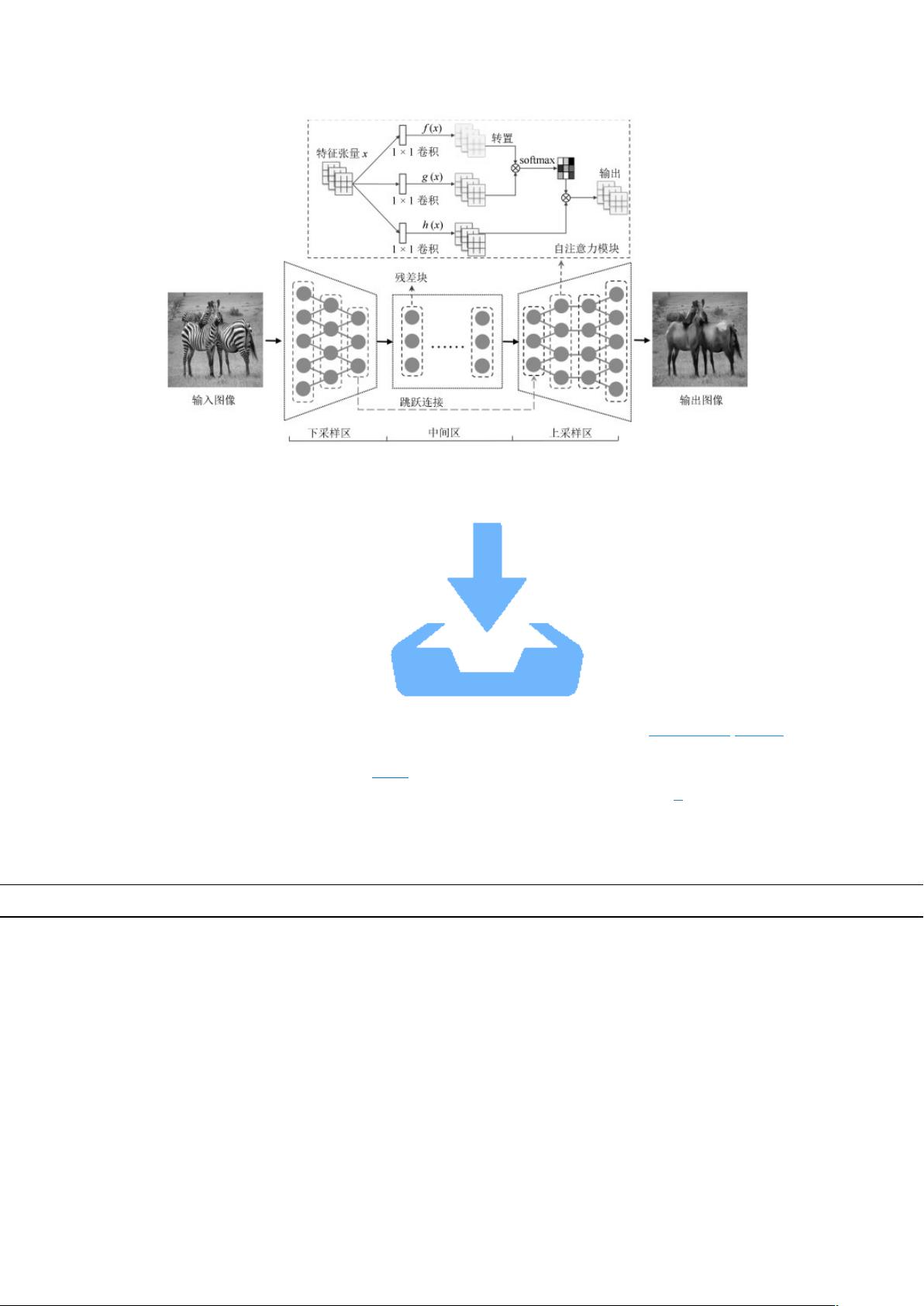
图 2 生成器网络
Fig. 2 Generator
下载: 全尺寸图片 幻灯片
生成器网络结构参数设置如表 1 所示, 除第 12 层输出层使用 Tanh 激活函数外, 包括
残差网络在内的卷积神经网络均使用实例归一化(Instance normalization, IN)
[13]
和 ReLU 激活
函数.
表 1 生成器网络结构参数设置
Table 1 The parameter setting of generator
序号
区域划分
层类型
卷积核
步长
深度
归一化
激活函数
0
下采样
Convolution
$ 7 \times 7 $
1
64
IN
ReLU
1
下采样
Convolution
$ 3 \times 3 $
2
128
IN
ReLU
2
下采样
Convolution
$ 3 \times 3 $
2
256
IN
ReLU
3
中间区
Residual Block
$ 3 \times 3 $
1
256
IN
ReLU
4
中间区
Residual Block
$ 3 \times 3 $
1
256
IN
ReLU
5
中间区
Residual Block
$ 3 \times 3 $
1
256
IN
ReLU
6
中间区
Residual Block
$ 3 \times 3 $
1
256
IN
ReLU
7
中间区
Residual Block
$ 3 \times 3 $
1
256
IN
ReLU
剩余19页未读,继续阅读
2022-06-09 上传
2022-11-28 上传
2022-12-15 上传
2023-02-23 上传

罗伯特之技术屋
- 粉丝: 4501
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- jquery-DOMwindow:最初来自http的jQuery DOMwindow插件的更新版本
- NLP_Basics:自然语言处理基本概念和高级概念
- go-clock
- [论坛社区]Google Sitemap生成器 v3.0 for phpwind 6.3.2_sitemap.rar
- 已加星标
- CentralLimit,modbusc#源码,c#
- AndroidStudioDemo
- Natural-Language-Processing-CS60075-:该存储库包含2020年秋季获得的NLP(CS60075)的已解决任务
- FireDoom::fire:动画DOOM feita em Java脚本
- Whowatch Hide Item Animation-crx插件
- dataVis
- Qt基于QGraphicsView绘图架构实现不同图形(多边形、圆形、矩形)的动态绘制(所见即所得)
- AnalyseFileData.zip
- NailPHP-master.zip
- ToolConvertEnglish
- SPINNER:使用 3 个 uicontrol 创建一个简单的微调控件。-matlab开发
