C#实现堆栈(Stack):原理、接口与实例解析
109 浏览量
更新于2024-09-01
收藏 72KB PDF 举报
"C#数据结构之堆栈(Stack)实例详解"
在C#中,堆栈是一种重要的数据结构,它的特点是遵循“后进先出”(Last In, First Out,简称LIFO)的原则。堆栈在计算机科学和编程中有广泛的应用,如函数调用的返回地址管理、表达式求值、浏览器的前进/后退功能等。本篇内容将详细讲解堆栈的概念、工作原理以及如何在C#中实现堆栈。
堆栈是一种线性数据结构,每个元素都有一个前驱元素和一个后继元素。然而,与顺序表和链表不同的是,堆栈仅允许在结构的一端(称为栈顶)进行插入和删除操作,即“压栈”(Push)和“弹栈”(Pop)。在C#中,我们可以使用数组或链表来实现堆栈。
首先,我们定义堆栈的接口IStack,它包含了以下方法:
1. Count():返回堆栈中的元素数量。
2. IsEmpty():检查堆栈是否为空。
3. Clear():清除堆栈中的所有元素。
4. Push(T item):向堆栈中添加一个元素(压栈)。
5. Pop():移除并返回堆栈顶部的元素(弹栈)。
6. Peek():返回堆栈顶部的元素,但不删除。
接下来,我们将介绍两种实现堆栈的方法:
1. **基于数组的顺序堆栈**(SeqStack):使用数组作为底层数据结构,通过索引来访问元素。初始化时需要指定最大容量,当堆栈满时,无法再进行压栈操作;反之,当堆栈为空时,可以继续弹栈,直到达到最小容量。在C#中,可以通过动态调整数组大小来处理这种情况,但这会带来额外的性能开销。
```csharp
public class SeqStack<T> : IStack<T>
{
private int maxSize;
private T[] data;
private int top;
// 构造函数,传入最大容量
public SeqStack(int maxSize)
{
this.maxSize = maxSize;
data = new T[maxSize];
top = -1;
}
// 其他实现IStack接口的方法...
}
```
2. **链式堆栈**:使用链表作为底层数据结构,每个节点包含一个元素和一个指向下一个节点的引用。链式堆栈的优点是动态扩展性好,不会受限于预设的最大容量。在C#中,可以使用LinkedList<T>类来实现链式堆栈。
```csharp
public class LinkStack<T> : IStack<T>
{
private LinkedList<T> stack;
public LinkStack()
{
stack = new LinkedList<T>();
}
// 其他实现IStack接口的方法...
}
```
无论选择哪种实现方式,堆栈的主要操作Push和Pop都是关键。Push操作在栈顶添加新元素,Pop操作则返回并移除栈顶元素。Peek方法用于查看栈顶元素而不改变堆栈状态。在C#中,这些操作的时间复杂度均为O(1),因为它们都是直接访问或修改栈顶元素。
堆栈的其他应用包括深度优先搜索(DFS)、拓扑排序、括号匹配等。在C#编程中,可以利用System.Collections.Generic命名空间中的Stack<T>类,这是一个预定义的堆栈实现,提供了丰富的API供开发者使用。
总结,堆栈作为一种基本的数据结构,在C#编程中扮演着重要角色。通过理解其工作原理和实现方式,我们可以更有效地设计和实现各种算法和功能。无论是基于数组的顺序堆栈还是链式堆栈,都能满足不同场景下的需求,为程序的高效运行提供支持。
C#数据结构之堆栈数据结构之堆栈(Stack)实例详解实例详解
主要介绍了C#数据结构之堆栈(Stack),结合实例形式较为详细的分析了堆栈的原理与C#实现堆栈功能的相关技
巧,具有一定参考借鉴价值,需要的朋友可以参考下
本文实例讲述了C#数据结构之堆栈(Stack)。分享给大家供大家参考,具体如下:
堆栈堆栈(Stack)最明显的特征就是最明显的特征就是“先进后出先进后出”,本质上讲堆栈也是一种线性结构,符合线性结构的基本特点:即每个节点有且只
有一个前驱节点和一个后续节点。
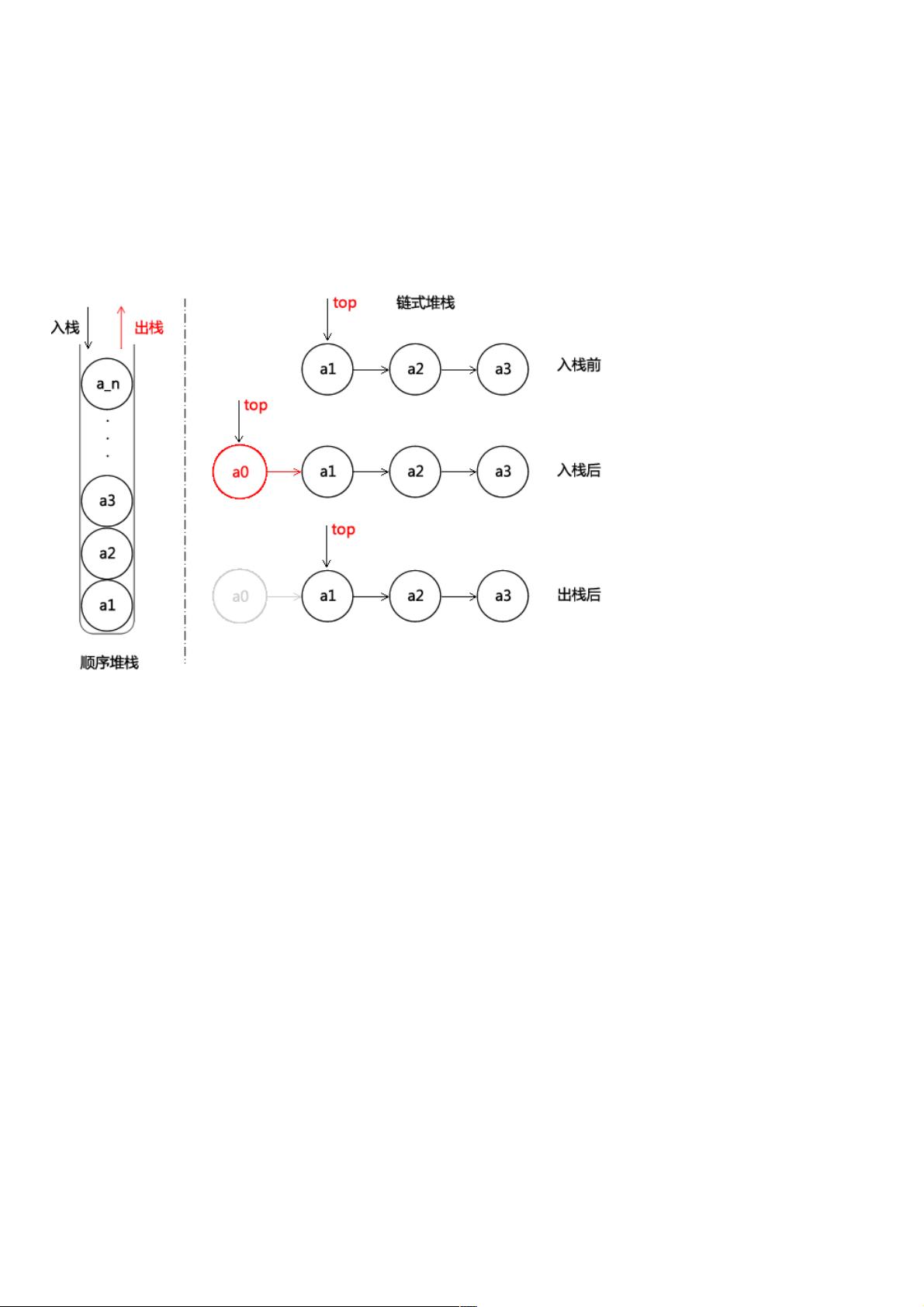
相对前面学习过的顺序表、链表不同的地方在于:Stack把所有操作限制在把所有操作限制在"只能在线性结构的某一端只能在线性结构的某一端"进行进行,而不能在中间插
入或删除元素。下面是示意图:
从示意图中可以看出,堆栈有二种实现方式:基于数组的顺序堆栈实现、类似链表的链式堆栈实现
先抽象堆栈的接口先抽象堆栈的接口IStack:
namespace 栈与队列
{
public interface IStack<T>
{
/// <summary>
/// 返回堆栈的实际元素个数
/// </summary>
/// <returns></returns>
int Count();
/// <summary>
/// 判断堆栈是否为空
/// </summary>
/// <returns></returns>
bool IsEmpty();
/// <summary>
/// 清空堆栈里的元素
/// </summary>
void Clear();
/// <summary>
/// 入栈:将元素压入堆栈中
/// </summary>
/// <param name="item"></param>
void Push(T item);
/// <summary>
/// 出栈:从堆栈顶取一个元素,并从堆栈中删除
/// </summary>
/// <returns></returns>
T Pop();
/// <summary>
/// 取堆栈顶部的元素(但不删除)
/// </summary>
/// <returns></returns>
T Peek();
}
下载后可阅读完整内容,剩余4页未读,立即下载
2020-08-29 上传
2010-12-28 上传
2020-09-04 上传
2013-12-24 上传
2020-09-02 上传
2020-08-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38732912
- 粉丝: 6
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
