HyperDex: 探索分布式键值存储的搜索功能
需积分: 9 201 浏览量
更新于2024-09-14
收藏 704KB PDF 举报
Sigcomm 2012论文《HyperDex: A Distributed, Searchable Key-Value Store》是一篇关于分布式存储系统的重要研究成果。该论文主要关注高性能Web服务和云计算应用中的核心组件——键值存储。相比于传统的数据库,键值存储在性能和可扩展性上具有显著优势,但其接口限制了对象的检索能力,即一个对象只能通过插入时指定的主键来获取。
作者罗伯特·埃斯克里瓦(Robert Escriva)来自康奈尔大学计算机科学系,伯纳德·黄(Bernard Wong)来自滑铁卢大学计算机科学 Cheriton 学院,以及埃米尼·G·辛瑟尔(Emin Gün Sirer)同样来自康奈尔大学计算机科学系,共同探讨了HyperDex这一创新设计。HyperDex突破了传统键值存储的局限,引入了超空间哈希的概念,将具有多个属性的对象映射到一个多维的超空间中。
这个关键洞察使得HyperDex能够支持对次要属性进行查询,从而极大地扩展了数据检索的可能性。通过这种多维度的映射,HyperDex不仅实现了高效的查找操作,而且还允许用户在处理复杂的数据结构和查询时保持较高的性能。这对于那些需要处理大量数据并频繁进行关联搜索的应用场景,如推荐系统、社交网络分析等,具有重大意义。
论文详细讨论了如何设计和实现超空间哈希算法,如何处理分布式环境中的数据一致性问题,以及如何在保证查询效率的同时,处理并发访问和负载均衡。此外,文中还可能包含了实验评估,比较了HyperDex与其他键值存储系统的性能和可扩展性,展示了其在实际应用中的优势。
总结来说,这篇Sigcomm论文为分布式存储系统领域带来了革新性的解决方案,特别是在提供高级查询功能和优化数据检索方面。它不仅推动了键值存储技术的发展,也为其他相关领域的研究者提供了新的思考角度和实践指导。对于任何关注云计算、大数据和分布式系统的人来说,深入理解HyperDex的设计理念和技术细节都是十分有价值的。
First Name
Phone Number
Last Name
John
Smith
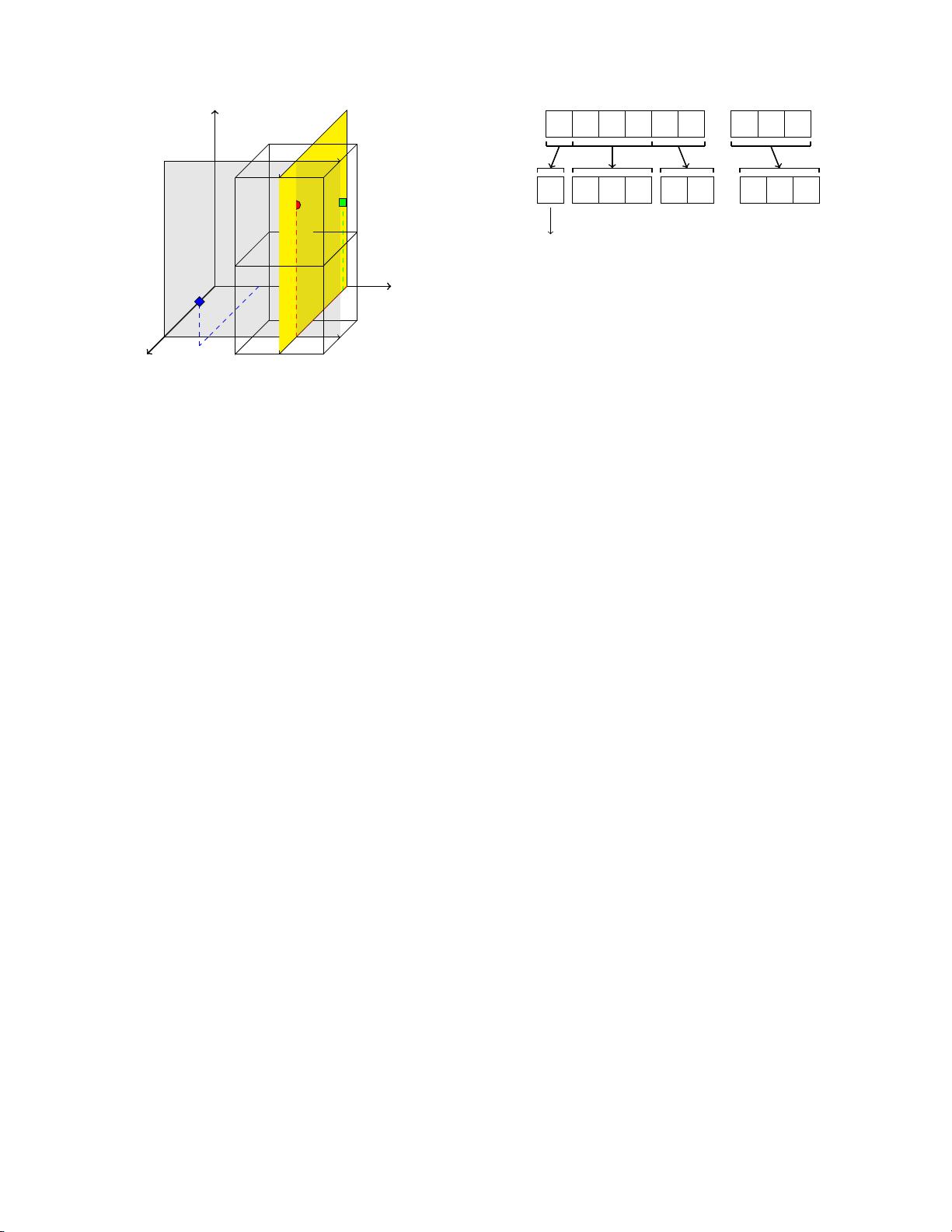
Figure 1: Simple hyperspace hashing in three di-
mensions. Each plane represents a query on a sin-
gle attribute. The plane orthogonal to the axis for
“Last Name” passe s through al l points for last_name
= ‘Smith’, while the other plane passes through all
points for first_name = ‘John’. Together they rep-
resent a line formed by the intersection of the two
search conditions; that is, all phone numbers for
people named “John Smith”. The two cubes show
regions of the space assigned to two different servers.
The que ry for “John Smith” needs to contact only
these servers.
op erations. In HyperDex, a search specifies a set of at-
tributes and the values that they must match (or, in the case
of numeric values, a range they must fall between). Hyper-
Dex returns objects which match the search. Each search
op eration uniquely maps to a hyperplane in the hyperspace
mapping. A search with one attribute specified map s to
a hyperplane that intersects th at attribute’s axis in exactly
one location and intersects all other axes at every point. Al-
ternatively, a search that specifies all attributes maps to
exactly one point in hyperspace. The hyperspace mapping
ensures that each additional search t erm potentially reduces
the number of servers to contact and guarantees that addi-
tional search terms will not increase search complexity.
Clients maintain a copy of th e hyperspace mapping, and
use it to deterministically execute search operations. A
client first maps the search into the hyperspace using the
mapping. It then determines which servers’ regions intersect
the resulting hyperplane, and issues the search request to
only those servers. The client may then collect matching
results from the servers. Because the hyperspace mapping
maps objects and servers into the same hyperspace, it is
never necessary to contact any server whose region does not
intersect the search hyp erplane.
Range queries correspond to extruded hyperplanes. When
an attribute of a search specifies a range of values, the cor-
responding hyperplane will intersect the attribute’s axis at
every point that falls between the lower and upper bounds of
the range. N ote that for such a scheme to work, objects’ rela-
tive orders for the attribute must be preserved when mapped
onto th e hyperspace axis.
Figure 1 illustrates a query for first_name = ‘John’ and
last_name = ‘Smith’. The query for first_name = ‘John’
k
v
1
v
2
v
3
v
4
v
5
. . .
v
D-1
v
D-1
v
D
hyperspace
k
v
1
v
2
v
3
v
4
v
5
. . .
v
D-1
v
D-1
v
D
key subspace
subspace 0 subspace 1 subspace S
Figure 2: HyperDex partitions a high-dim ensional
hyperspace into multiple low-dimension subspaces.
corresponds to a two-dimensional plane which intercepts the
first_name axis at the h ash of ‘John’. Similarly, the query
for last_name = ‘Smith’ creates another plane which inter-
sects the last_name axis. The intersection of the two planes
is the line along which all phone numbers for John Smith re-
side. Since a search for John Smith in a particular area code
defines a line segment, a H yperDex search needs to contact
only those nodes whose regions intersect that segment.
3. DATA PARTITIONING
HyperDex’s Euclidean space construction significantly re-
duces the set of servers that must be contacted to find match-
ing objects.
However, the drawback of coupling the dimensionality of
hyperspace with the number of searchable attributes is that,
for tables with many searchable attributes, the hyperspace
can be very large since its volume grows exponentially with
the number of dimensions. Covering large spaces with a grid
of servers may not be feasible even for large data-center de-
ployments. For example, a table with 9 secondary attributes
may require 2
9
regions or more to support efficient searches.
In general, a D dimensional hyperspace will need O(2
D
)
servers.
HyperDex avoids the problems associated with high-di-
mensionality by partitioning tables with many attributes
into multiple lower-dimensional hyperspaces called subspaces.
Each of these subsp aces uses a sub set of object attributes as
the dimensional axes for an independent hyperspace. Fig-
ure 2 shows how HyperDex can partition a table with D
attributes into multiple independ ent su bspaces. W hen per-
forming a search on a table, clients select the subspace that
contacts the fewest servers, and will issue the search to
servers in exactly one subspace.
Data partitioning increases the efficiency of a search by
reducing the dimensionality of the underlying hyperspace.
In a 9-dimensional hyperspace, a search over 3 attributes
would need to contact 64 regions of the hyperspace (and
thus, 64 servers). If, instead, the same table were parti-
tioned into 3 subspaces of 3 attributes each, the search will
never contact more than 8 servers in the worst case, and
exactly one server in the best case. By partitioning the ta-
ble, HyperDex reduces the worst case behavior, decreases
the number of servers necessary to maintain a table, and
increases the likelihood that a search is ru n on exactly one
server.
Data partitioning forces a trade-off between search gener-
ality and efficiency. On the one hand, a single hyperspace
can accommodate arbitrary searches over its associated at-
tributes. On the other hand, a hyperspace which is too large
27
剩余11页未读,继续阅读
2017-04-10 上传
2017-04-10 上传
2018-11-13 上传
2018-11-13 上传
2017-04-10 上传
2017-04-10 上传
2017-04-10 上传
2016-03-24 上传
2016-03-24 上传

shrewdsage
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多功能HTML网站模板:手机电脑适配与前端源码
- echarts实战:构建多组与堆叠条形图可视化模板
- openEuler 22.03 LTS专用openssh rpm包安装指南
- H992响应式前端网页模板源码包
- Golang标准库深度解析与实践方案
- C语言版本gRPC框架支持多语言开发教程
- H397响应式前端网站模板源码下载
- 资产配置方案:优化资源与风险管理的关键计划
- PHP宾馆管理系统(毕设)完整项目源码下载
- 中小企业电子发票应用与管理解决方案
- 多设备自适应网页源码模板下载
- 移动端H5模板源码,自适应响应式网页设计
- 探索轻量级可定制软件框架及其Http服务器特性
- Python网站爬虫代码资源压缩包
- iOS App唯一标识符获取方案的策略与实施
- 百度地图SDK2.7开发的找厕所应用源代码分享
