深入解析Hadoop RPC机制
14 浏览量
更新于2024-09-02
收藏 163KB PDF 举报
"深入解析Hadoop的RPC机制在HBase中的应用"
在分布式系统中,远程过程调用(RPC)机制是实现组件间通信的关键技术。Hadoop的RPC机制允许节点间进行高效、透明的通信,使得客户端能够像调用本地方法一样调用远程服务器上的方法。本文将对Hadoop0.20.203.0版本中的RPC机制进行源码级别的深度分析。
首先,我们需要理解RPC的本质。在低级别的网络通信中,客户端和服务器之间的交互通常涉及字节流的发送与接收。然而,这种粒度较细的通信方式并不利于理解和设计大规模的网络系统。因此,Hadoop引入了一种"架构层次的协议",即定义了一系列接口和方法,客户端和服务端只需实现这些接口,即可实现通信。这种方式降低了通信的复杂性,使系统设计更为清晰。
Hadoop的RPC机制基于`VersionedProtocol`接口,这是一个所有RPC协议接口的父接口,它只有一个方法`getProtocolVersion()`,用于获取协议的版本号,确保客户端和服务端之间的协议兼容性。
接下来,我们将关注几个重要的RPC协议接口:
1. **ClientDatanodeProtocol**:此接口定义了客户端与DataNode之间的通信协议,主要用于数据块的恢复操作。例如,客户端可能需要从DataNode获取数据块的副本,或者协调数据块的复制,以恢复丢失的数据。
2. **ClientProtocol**:这是客户端与NameNode之间交互的核心接口,包含了所有对文件系统的控制操作,如创建、删除、重命名文件或目录,以及打开、关闭文件等。客户端的所有元数据请求都通过此接口传递给NameNode。
3. **DatanodeProtocol**:DataNode使用这个接口与NameNode保持同步,发送心跳信息,报告存储块的状态,以及执行NameNode指示的数据块复制和其他管理任务。
在实现RPC时,Hadoop使用了自定义的序列化框架Writables,将对象转换为字节数组进行网络传输。同时,它使用了反射机制来动态地实例化远程服务器上的方法。此外,Hadoop的RPC还包含了服务端的线程池管理和连接管理,以优化并发处理和资源利用。
RPC的调用流程大致如下:
1. 客户端创建一个Proxy对象,该对象实现了服务端的接口,并封装了实际的网络通信细节。
2. 当调用Proxy上的方法时,请求会被序列化并发送到服务端。
3. 服务端接收到请求后,反序列化并执行相应的操作,然后将结果返回给客户端。
4. 客户端接收到结果后,将其反序列化并返回给调用者。
这种RPC机制在HBase中也得到了广泛应用。HBase作为一个分布式的列式存储系统,其RegionServer与Master节点之间的通信,以及客户端与RegionServer的交互,都依赖于Hadoop的RPC机制。例如,客户端通过RPC向RegionServer查询数据、更新表记录,或者RegionServer向Master汇报状态等。
Hadoop的RPC机制是其核心组件之间高效通信的基础,通过精心设计的接口和协议,实现了分布式系统中的透明通信,为HBase这样的大数据存储系统提供了可靠的支撑。理解并掌握这一机制,对于开发和优化Hadoop生态下的应用程序至关重要。
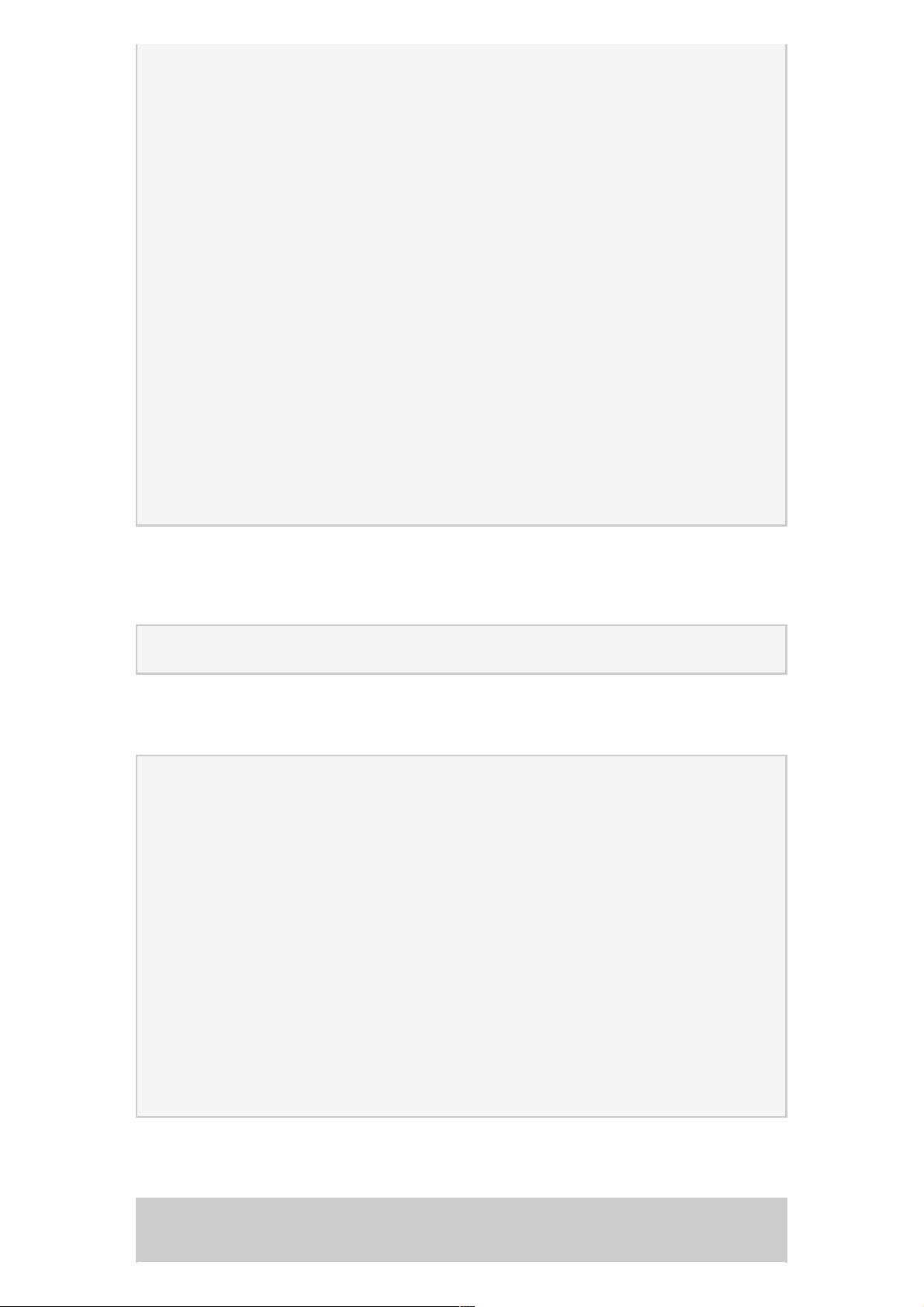
public Writable call(Writable param, ConnectionId remoteId)
throws InterruptedException, IOException {
Call call = new Call(param); //将传入的数据封装成call对象
Connection connection = getConnection(remoteId, call); //获得一个连接
connection.sendParam(call); // 向服务端发送call对象
boolean interrupted = false;
synchronized (call) {
while (!call.done) {
try {
call.wait(); // 等待结果的返回,在Call类的callComplete()方法里有notify()方法用于唤醒线程
} catch (InterruptedException ie) {
// 因中断异常而终止,设置标志interrupted为true
interrupted = true;
}
}
if (interrupted) {
Thread.currentThread().interrupt();
}
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
} else { // 本地异常
throw wrapException(remoteId.getAddress(), call.error);
}
} else {
return call.value; //返回结果数据
}
}
}
具体代码的作用我已做了注释,所以这里不再赘述。但到目前为止,你依然不知道RPC机制底层的网络连接是怎么建立的。
呵呵,那我们只好再去深究了,分析代码后,我们会发现和网络通信有关的代码只会是下面的两句了:
代码四:
Connection connection = getConnection(remoteId, call); //获得一个连接
connection.sendParam(call); // 向服务端发送call对象
先看看是怎么获得一个到服务端的连接吧,下面贴出ipc.Client类中的getConnection()方法。
代码五:
private Connection getConnection(ConnectionId remoteId,
Call call)
throws IOException, InterruptedException {
if (!running.get()) {
// 如果client关闭了
throw new IOException("The client is stopped");
}
Connection connection;
//如果connections连接池中有对应的连接对象,就不需重新创建了;如果没有就需重新创建一个连接对象。
//但请注意,该//连接对象只是存储了remoteId的信息,其实还并没有和服务端建立连接。
do {
synchronized (connections) {
connection = connections.get(remoteId);
if (connection == null) {
connection = new Connection(remoteId);
connections.put(remoteId, connection);
}
}
} while (!connection.addCall(call)); //将call对象放入对应连接中的calls池,就不贴出源码了
//这句代码才是真正的完成了和服务端建立连接哦~
connection.setupIOstreams();
return connection;
}
如果你还有兴趣继续分析下去,那我们就一探建立连接的过程吧,下面贴出Client.Connection类中的setupIOstreams()方法:
代码六:
剩余10页未读,继续阅读
2015-07-15 上传
104 浏览量
点击了解资源详情
2015-12-07 上传
2014-07-10 上传
2011-05-21 上传
2014-12-11 上传
2011-09-01 上传
2016-05-12 上传

weixin_38669674
- 粉丝: 11
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
