V100服务器离线安装CUDA10.0、cudnn、anaconda3及TensorFlow-GPU指南
需积分: 50 47 浏览量
更新于2024-08-29
收藏 745KB DOCX 举报
"该文档详细介绍了在V100服务器上进行CUDA驱动、CUDA10.0、cudnn、anaconda3以及tensorflow-gpu的离线安装过程。"
在高性能计算领域,NVIDIA的GPU,尤其是Tesla V100,因其强大的并行计算能力而被广泛用于深度学习和科学计算。为了在这样的服务器上运行GPU加速的程序,例如TensorFlow,首先需要安装必要的软件栈,包括CUDA驱动、CUDA工具包、cudnn和Anaconda环境。离线安装通常适用于网络不畅或安全性要求高的环境。
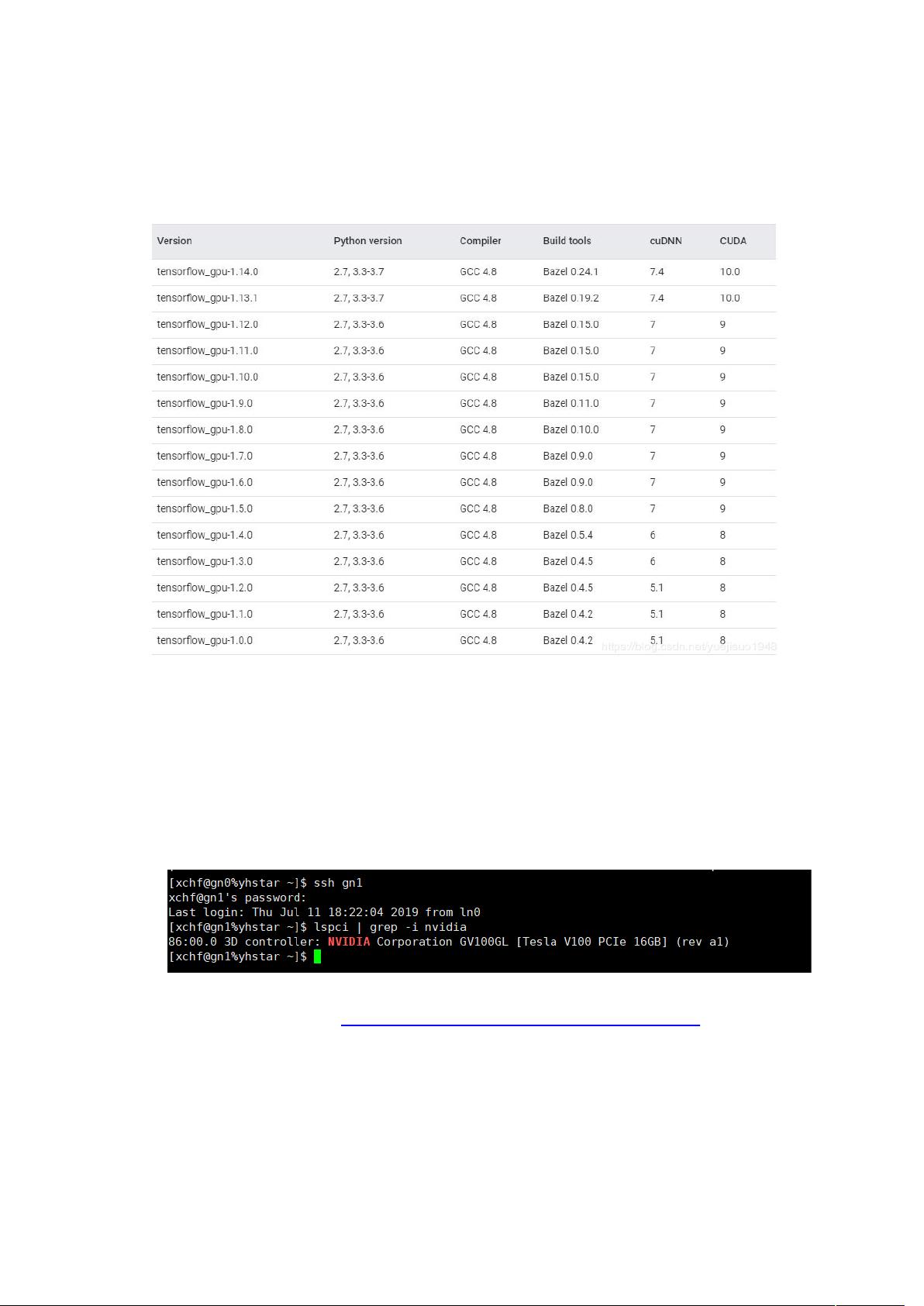
1. **检查GPU硬件**:首先,通过`lspci | grep -invidia`命令来确认服务器上是否有NVIDIA GPU,这一步是安装CUDA驱动的前提。
2. **禁用 nouveau 驱动**:在某些Linux发行版中,如Ubuntu,系统可能会默认加载开源的nouveau驱动,这与NVIDIA官方驱动冲突,因此需要在安装NVIDIA驱动前禁用它。
3. **安装CUDA驱动**:从NVIDIA官方网站下载对应版本的驱动,例如文档中提到的`nvidia-diag-driver-local-repo-rhel7-410.104-1.0-1.x86_64.rpm`,然后使用`rpm`命令安装。接着,使用`yum`命令安装CUDA驱动,并在安装完成后重启服务器。通过`nvidia-smi`命令检查驱动是否正确安装和运行。
4. **安装CUDA工具包**:访问CUDA的官方网站下载CUDA 10.0的安装包,这里使用的是`cuda_10.0.130_410.48_linux.run`。在安装过程中,按照提示接受许可协议,选择不安装驱动,同意安装工具包,并指定工具包的安装路径。最后,设置环境变量,将CUDA的bin目录添加到`PATH`中,以便于后续的命令行操作。
5. **安装cudnn**:cudnn是NVIDIA提供的深度学习库,加速了深度学习框架的运算速度。下载对应的cudnn版本解压后,将头文件复制到CUDA的include目录,库文件复制到CUDA的lib64目录,并更新系统的动态链接库配置文件`ldconfig`。
6. **安装Anaconda**:Anaconda是一个Python分发版,包含了众多科学计算库和数据科学工具。下载Anaconda的离线安装包,然后按照官方指南进行安装,创建一个新的环境,并在环境中安装TensorFlow-gpu。
7. **安装TensorFlow-gpu**:在Anaconda环境中,使用`conda`或`pip`命令安装TensorFlow-gpu版本。这将确保TensorFlow能够利用GPU进行计算。
完成以上步骤后,V100服务器就具备了运行GPU加速的TensorFlow程序的能力。用户可以通过编写和运行TensorFlow代码,验证安装是否成功,比如通过检查GPU设备是否能被识别并使用。在实际应用中,还应注意更新软件版本,保持与最新稳定版本兼容,以获取最佳性能和新特性。同时,根据服务器的内存和计算需求,合理调整TensorFlow的配置参数也是优化性能的关键。
下载后可阅读完整内容,剩余7页未读,立即下载
2019-07-25 上传
2021-03-05 上传
2020-12-21 上传
2021-01-06 上传
2021-03-05 上传
2019-06-10 上传
2021-03-05 上传
2021-01-20 上传
398 浏览量

卒小小名无呵
- 粉丝: 2
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
