Redis中scan命令的高效查询策略及实现原理
195 浏览量
更新于2024-08-29
收藏 514KB PDF 举报
Redis中的scan命令是一种高效且安全的替代keys命令的方法,尤其适用于大规模数据存储场景。它在Redis 2.8.0版本中引入,旨在解决在大量键值对中查找符合特定模式键的问题,避免因一次性加载所有键而导致的服务性能下降和数据库压力过大。
当运维人员需要查询具有特定前缀的所有键,但又不想使用效率低下的keys命令时,scan命令就显得尤为重要。scan通过游标机制分批扫描键空间,每次请求返回一定数量的匹配项,以及一个新的游标值,以便下一次迭代。这样,即使数据量巨大,也不会像keys命令那样瞬间耗尽内存和CPU资源。
scan命令的工作原理基于哈希表的数据结构,特别是对于散列表(例如哈希表)存储的键值对。当键值对的数量和大小超过hash-max-ziplist-value和hash-max-ziplist-entries的限制时,keys命令的全量扫描会导致性能瓶颈。scan则采用逐节点的方式进行,确保在哈希表的rehash过程中,既不会重复遍历已处理过的节点,也不会漏掉任何未处理的节点。
rehash是redis的哈希表动态扩展策略,通过渐进式的方式将键分配到新的哈希表中,这期间可能会发生数据迁移。scan命令巧妙地设计了游标逻辑,确保在rehash过程中,即使数据迁移正在进行,也能保持数据的一致性和完整性,即不会丢失或重复返回键。
具体来说,scan命令的实现核心在于dictScan函数,它维护了一个游标值(初始化为0),每次迭代时更新游标,然后通过二进制逆序操作进一步处理。例如,在四个节点的哈希表中,游标会按照0->2->1->3的顺序遍历。当面对更复杂的8节点情况时,这种递进式的遍历方式确保了稳定性和性能。
总结起来,scan命令是Redis提供的一种高效查找机制,它通过游标机制有效地避免了keys命令的潜在风险,特别是在处理大容量数据集时,显著提高了查询性能并降低了对数据库系统的冲击。这对于保证Redis服务的稳定性和响应速度至关重要。
redis中中scan命令的基本实现方法命令的基本实现方法
前言前言
在一个天朗气清的日子,小灰登上了线上的redis打算查询数据。然而他只记得前缀而不知道整个键是多少,于是在命令行敲入了“keys xxx*”命令。
瞬间服务卡死,报警邮件堆满了邮箱,而小灰,只能目瞪狗呆的等待着即将降临的case study。
基本上,keys *命令都是在线上是被运维禁止的。
redis的键在键值对大小大于hash-max-ziplist-value且个数小于hash-max-ziplist-entries的时候,是存放在散列表数据结构中的,在运行keys命令的时候,需要遍历数据库键空间,把所有键都取
出来后与keys后面的pattern匹配。
在键很多的情况下,redis可能的卡顿会在秒级以上,导致所有流量都打到数据库,使得数据库雪崩。
那我们怎么才能够在查找到目标键呢?在redis2.8.0的时候加入了scan命令,可以分批次扫描redis键。虽然在应用的时候会使得要查询到全部符合要求的key的时间变长,但是大大大大减少了
redis卡顿的几率
在这里先补充一下背景:在这里先补充一下背景:
redis中的字典rehash是渐进式哈希,即不是一次性把所有的键都迁移到新的哈希表,而是在下面两种情况下迁移数据:
每次哈希表操作的时候,如果当前正在rehash,则迁移一个节点;
服务空闲时,会rehash一百个节点。
scan命令可以保证在(没有键修改的)字典正在rehash的过程中做到以下两点:
不出现重复数据
不遗漏数据
那scan命令是怎么做到在rehash过程中都能不重复不遗漏地遍历所有节点的呢?让我们来一起走读一下源码。
Let’s GO!
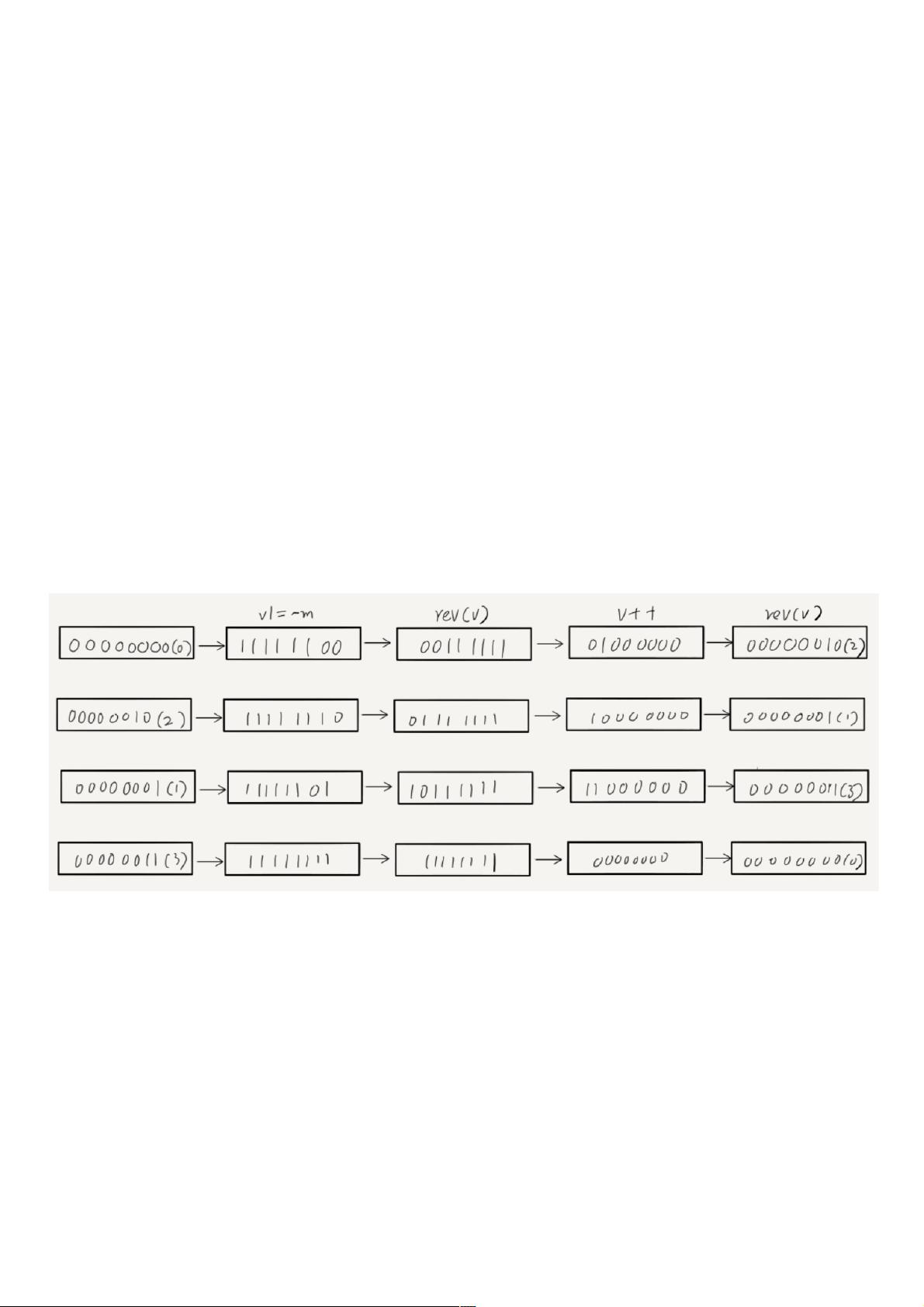
在使用scan命令的时候,我们每次传入一个游标(从0开始),然后下一轮继续使用本轮redis返回的游标。scan字典的核心函数是dictScan,而dictScan的更新游标的核心代码如下:
v |= ~m0;//或者m1
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
其中m0、m1为当前哈希表大小减一,rev是二进制逆序。
看到这里,不知道在座的各位是不是也是跟我一样是下面这个表情
让我们来模拟一下问题,就清楚了。
我们假设现在在一个四个节点的哈希表中遍历,如下图,游标的遍历节点为:0 -> 2 -> 1 -> 3 :
再来模拟8节点的情况:
下载后可阅读完整内容,剩余3页未读,立即下载
2020-09-08 上传
2021-01-19 上传
2023-09-18 上传
2020-09-09 上传
2024-06-10 上传
2020-09-08 上传
2022-09-20 上传
2013-11-26 上传
2020-09-09 上传

weixin_38750209
- 粉丝: 9
- 资源: 836
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
