MySQL高效查询与删除表中重复数据的方法
98 浏览量
更新于2024-08-31
收藏 196KB PDF 举报
在MySQL数据库中,处理表中的重复数据是一项常见的任务,尤其是在进行数据分析、清洗或优化时。本文档详细介绍了如何查询和处理表内的重复数据记录,主要有两种场景和相应的解决策略。
**场景一:统计重复的用户名(username)**
要找出某个字段(如username)中有重复值的情况,可以使用以下SQL语句:
```sql
SELECT username, COUNT(*) AS count
FROM hk_test
GROUP BY username
HAVING count > 1;
```
这个查询将返回每个username及其出现次数,通过`HAVING count > 1`条件筛选出重复的记录。如果需要按重复次数降序排列,可以在`ORDER BY`子句中添加`COUNT(*) DESC`。
**场景二:获取具体重复记录**
尽管上述方法能统计重复数量,但若想获取每个重复组的所有信息,可以使用子查询和`IN`关键字,但这在大型数据集上可能效率不高:
```sql
SELECT * FROM hk_test
WHERE username IN (SELECT username FROM hk_test GROUP BY username HAVING count(username) > 1);
```
由于MySQL在处理这类子查询时可能不会自动创建临时表,这可能导致查询速度变慢。
**解决方法:使用临时表和连接查询**
为了提高查询性能,建议先创建一个临时表存储重复的记录,然后使用多表连接来查找重复数据:
1. 建立临时表:
```sql
CREATE TABLE `tmptable` AS
SELECT `name` FROM `table`
GROUP BY `name` HAVING count(`name`) > 1;
```
2. 使用连接查询找到重复的完整记录:
```sql
SELECT a.id, a.name
FROM `table` a
JOIN `tmptable` t ON a.name = t.name;
```
或者,如果只需要唯一组合,可以使用`DISTINCT`关键字:
```sql
SELECT DISTINCT a.id, a.name
FROM `table` a
JOIN `tmptable` t ON a.name = t.name;
```
这样,通过临时表的方式,即使数据量较大,也能更快地找到并处理表内的重复数据。这些方法对于维护数据质量和性能优化都有重要作用。
mysql查询表里的重复数据方法查询表里的重复数据方法
主要介绍了mysql查询表里的重复数据方法,需要的朋友可以参考下
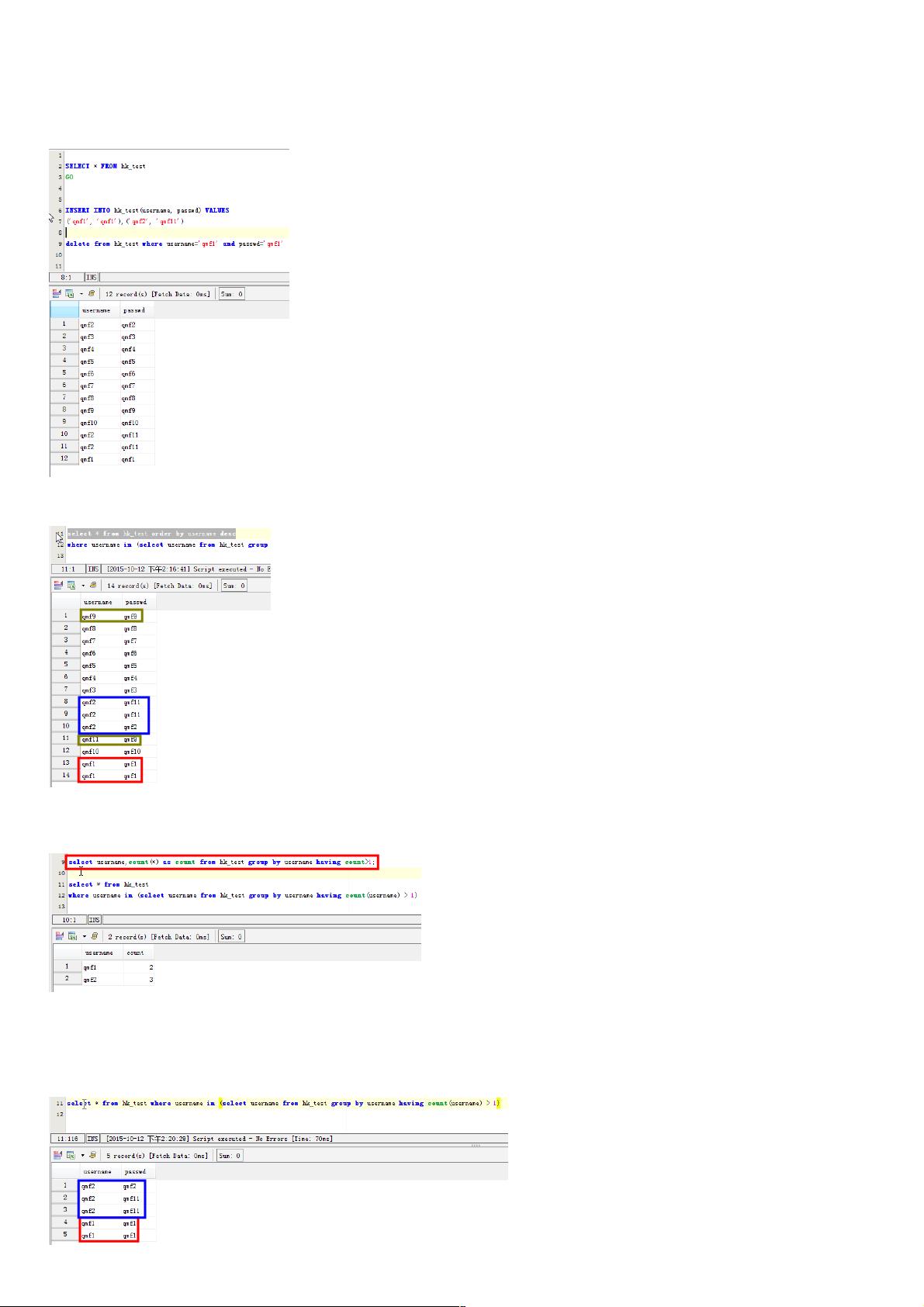
INSERT INTO hk_test(username, passwd) VALUES
('qmf1', 'qmf1'),('qmf2', 'qmf11')
delete from hk_test where username='qmf1' and passwd='qmf1'
MySQL里查询表里的重复数据记录:
先查看重复的原始数据:
场景一:列出username字段有重读的数据
select username,count(*) as count from hk_test group by username having count>1;
SELECT username,count(username) as count FROM hk_test GROUP BY username HAVING count(username) >1 ORDER BY count DESC;
这种方法只是统计了该字段重复对应的具体的个数
场景二:列出username字段重复记录的具体指:
select * from hk_test where username in (select username from hk_test group by username having count(username) > 1)
SELECT username,passwd FROM hk_test WHERE username in ( SELECT username FROM hk_test GROUP BY username HAVING count(username)>1)
但是这条语句在mysql中效率太差,感觉mysql并没有为子查询生成临时表。在数据量大的时候,耗时很长时间
下载后可阅读完整内容,剩余3页未读,立即下载
2020-12-16 上传
2021-01-19 上传
2023-06-10 上传
2023-06-10 上传
2023-06-02 上传
2023-06-02 上传
2023-07-13 上传
2020-09-09 上传
2017-08-24 上传

weixin_38624557
- 粉丝: 8
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
