Hadoop:分布式计算的开源框架解析
"分布式计算开源框架Hadoop介绍"
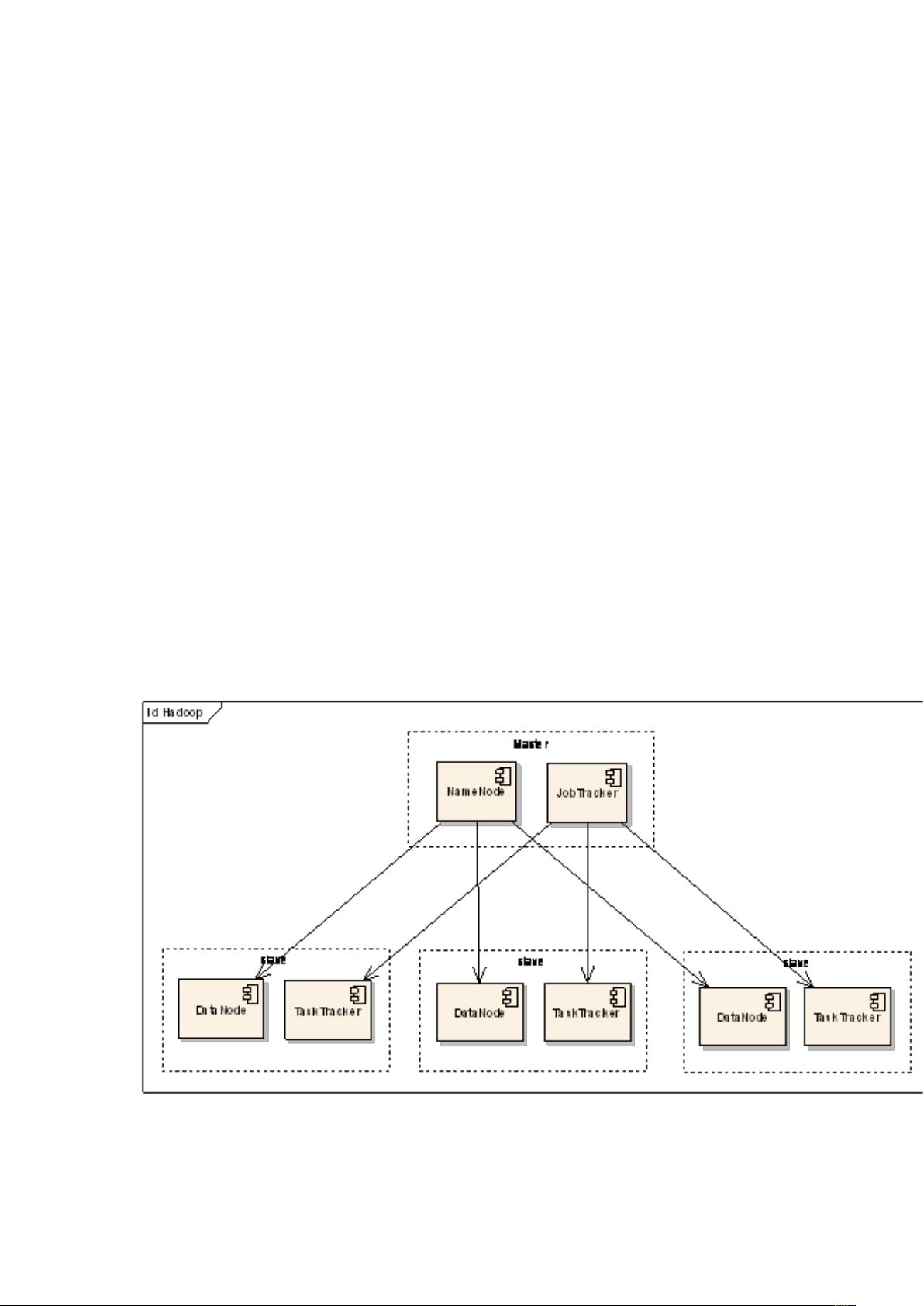
Hadoop是一个由Apache基金会开发的开源分布式计算框架,它设计的目标是处理和存储大规模数据。Hadoop的核心包括两个主要组件:Hadoop Distributed File System (HDFS) 和 MapReduce。HDFS是分布式文件系统,用于存储大量数据,而MapReduce则是一种编程模型,用于并行处理这些数据。
**什么是Hadoop?**
Hadoop是一个允许在普通硬件上运行的开源框架,它可以高效地处理PB级别的数据。它的设计灵感来源于Google的两篇论文——"Google File System"和"MapReduce"。Hadoop的主要特点是高度容错性和可扩展性,能够处理节点故障,并且能够随着硬件的增加而无缝扩展。
**为什么要选择Hadoop?**
1. **可扩展性**:Hadoop可以在低成本的普通硬件上构建大规模集群,轻松处理大数据量。
2. **高容错性**:通过数据复制,Hadoop可以在节点故障时自动恢复,保证数据的安全性和服务的连续性。
3. **并行处理**:MapReduce使得复杂数据处理任务可以被分割成小任务,分发到集群的不同节点并行执行,极大地提高了处理效率。
4. **成本效益**:相比于专有解决方案,Hadoop基于开放源码,降低了硬件和软件的成本。
5. **适应性强**:Hadoop适用于各种类型的数据,包括结构化、半结构化和非结构化的数据。
**环境与部署考虑**
部署Hadoop需要考虑网络环境、硬件配置、操作系统选择、集群规模等因素。理想的环境应具备高速的内部网络,以减少数据传输延迟。硬件配置应足够强大以处理计算任务,同时也要考虑冗余以防止故障。操作系统的稳定性和兼容性也很重要,通常Linux被广泛采用。集群规模需根据实际数据量和处理需求来规划。
**实施步骤**
1. **安装配置Hadoop**:设置Hadoop环境变量,配置Hadoop配置文件如`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`。
2. **格式化HDFS**:初始化HDFS文件系统。
3. **启动Hadoop**:启动NameNode、DataNode、ResourceManager、NodeManager等进程。
4. **测试Hadoop**:运行简单的MapReduce程序验证集群是否正常工作。
**Hadoop基本流程**
Hadoop的工作流程主要包括数据存储(HDFS)和数据处理(MapReduce)两个阶段:
1. **数据存储**:数据被分割成块,复制到不同的DataNodes上,确保数据可用性和容错性。
2. **数据处理**:MapReduce将大任务拆分成Map和Reduce阶段,Map阶段在各个节点并行处理数据块,Reduce阶段对结果进行聚合。
**业务场景和代码范例**
Hadoop常用于日志分析、推荐系统、搜索引擎索引构建、社交网络分析等多种场景。例如,通过MapReduce分析用户日志,可以提取用户行为模式,用于广告定向或个性化推荐。
**Hadoop集群测试**
测试Hadoop集群包括检查数据读写性能、MapReduce任务执行效率以及集群稳定性等。通过基准测试工具如TeraSort和NDFS-IO进行性能评估。
在实际应用中,Hadoop不仅是一个分布式计算框架,更是大数据生态系统的重要组成部分,与其他开源项目如Hive、Pig、Spark等紧密配合,为企业提供全面的大数据解决方案。对于初学者来说,理解Hadoop的基本原理和使用方法,是进入大数据领域的关键一步。

3. Client 将文件划分为多个 Block,根据 DataNode 的地址信息,按顺序写入到每
一个 DataNode 块中。
文件读取:
1. Client 向 NameNode 发起文件读取的请求。
2. NameNode 返回文件存储的 DataNode 的信息。
3. Client 读取文件信息。
文件 Block 复制:
1. NameNode 发现部分文件的 Block 不符合最小复制数或者部分 DataNode 失效。
2. 通知 DataNode 相互复制 Block。
3. DataNode 开始直接相互复制。
最后再说一下 HDFS 的几个设计特点(对于框架设计值得借鉴):
1. Block 的放置:默认不配置。一个 Block 会有三份备份,一份放在 NameNode 指
定的 DataNode,另一份放在与指定 DataNode 非同一 Rack 上的 DataNode,
最后一份放在与指定 DataNode 同一 Rack 上的 DataNode 上。备份无非就是为
了数据安全,考虑同一 Rack 的失败情况以及不同 Rack 之间数据拷贝性能问题就
采用这种配置方式。
2. 心跳检测 DataNode 的健康状况,如果发现问题就采取数据备份的方式来保证数
据的安全性。
3. 数据复制(场景为 DataNode 失败、需要平衡 DataNode 的存储利用率和需要平
衡 DataNode 数据交互压力等情况):这里先说一下,使用 HDFS 的 balancer
命令,可以配置一个 Threshold 来平衡每一个 DataNode 磁盘利用率。例如设置
了 Threshold 为 10%,那么执行 balancer 命令的时候,首先统计所有
DataNode 的磁盘利用率的均值,然后判断如果某一个 DataNode 的磁盘利用率
超过这个均值 Threshold 以上,那么将会把这个 DataNode 的 block 转移到磁盘
利用率低的 DataNode,这对于新节点的加入来说十分有用。
剩余25页未读,继续阅读
2021-06-22 上传
2015-06-16 上传
2020-04-19 上传
2020-03-23 上传
2022-10-22 上传
2021-09-21 上传

jd_yong
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
