HVR数据复制软件实现实时文件系统备份:步骤与配置详解
需积分: 10 183 浏览量
更新于2024-07-20
收藏 918KB PDF 举报
本文主要介绍了如何使用HVR数据复制软件在Linux系统文件系统上进行实时文件复制,以实现灾备的目的。作者通过具体实例,展示了在Red Hat Enterprise Linux (RHEL) 5.9环境中,使用HVR进行文件复制的过程,包括以下几个关键步骤:
1. **HVR软件背景**:
HVR(High Velocity Replication)是一款用于数据库和文件系统的实时复制工具,它能够在Oracle Database 12.1.0.2版本的HUB数据库上运行。首先,读者需要确保HVR软件已经成功安装,安装教程可参考CSDN博主的相关文章。
2. **环境准备**:
该环境中,主机为RHEL 5.9,内核版本为2.6.18-348.el5,并且安装了Oracle数据库。文件系统上,/tmp目录下有三个待复制的源目录(f1、f2、f3)。
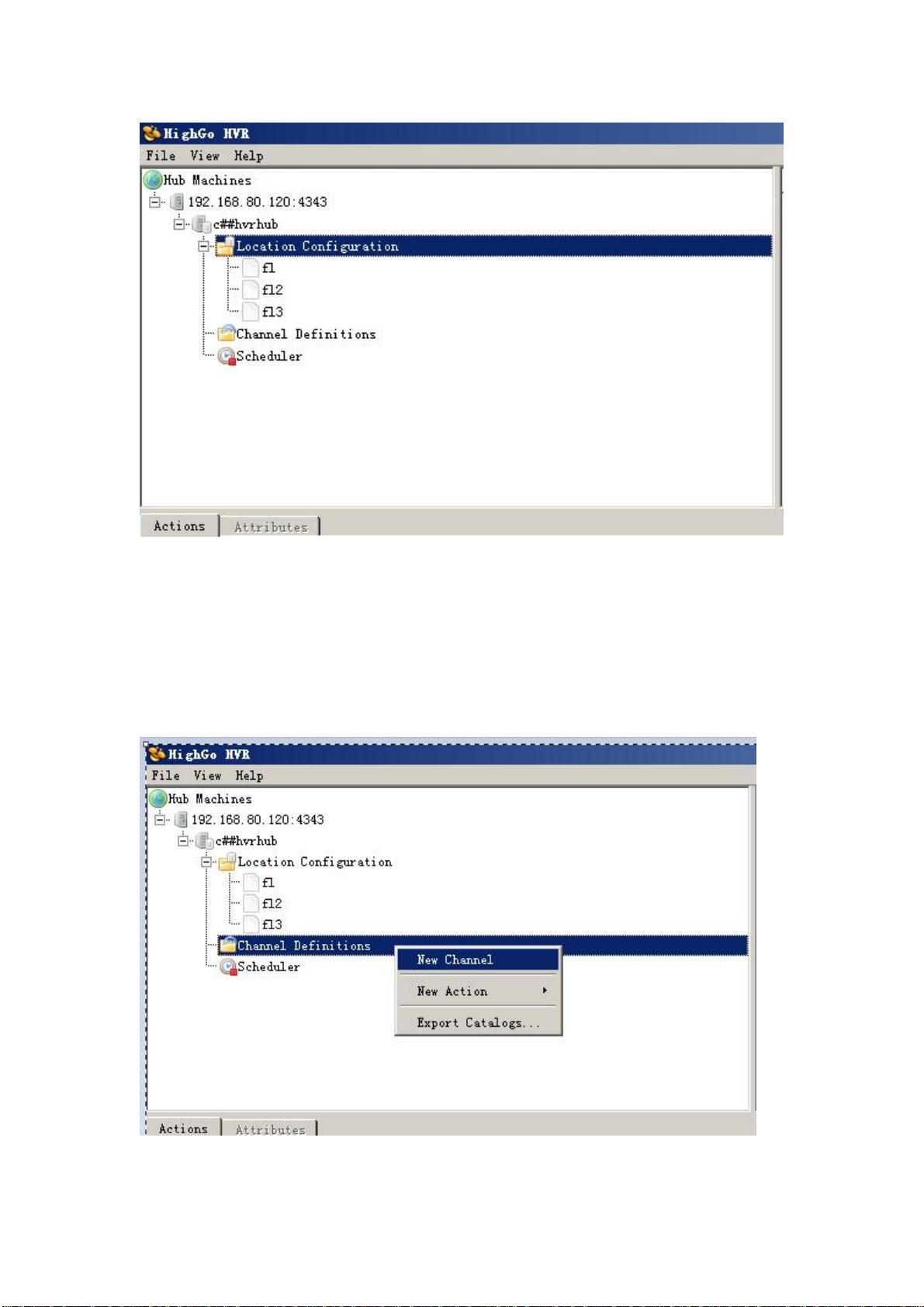
3. **Location和Channel配置**:
- **Location**:这是HVR中的一个重要概念,代表了一个数据存储的位置,比如源目录或目标目录。文中提到创建了三个Location,分别是fl、fl2和fl3。
- **Channel**:通道是连接两个Location的桥梁,负责数据的传输。在命名Channel时,遵循特定规则,即12个字符长度,只允许使用数字和下划线。
4. **Action定义**:
Action负责定义数据复制的方向和规则,即确定哪个Location作为源,哪个作为目标。通过在Location Group上设置Action,确保数据复制策略正确执行。
5. **HVR Load与Job生成**:
当配置完成后,HVR会加载这些设置并生成相应的Job,每个Job对应一个复制任务。启动HVR后,系统会创建三个Job,展示整个复制过程的结构。
6. **Scheduler启动**:
最后一步是启动Scheduler,它负责按照预设的计划执行数据复制操作。启动Scheduler时需注意,这可能会影响HUB主机的操作系统性能。
本文不仅详细阐述了HVR在实际场景中的应用,还提供了技术细节和配置步骤,对于需要进行文件系统灾备的企业或IT管理员来说,是一个实用的指导。
4
第二步:配置 Channel
剩余16页未读,继续阅读
2018-12-14 上传
2019-07-14 上传
2023-05-24 上传
2023-06-12 上传
2023-06-11 上传
2023-06-13 上传
2023-06-11 上传
2014-04-16 上传

msdnchina
- 粉丝: 387
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
