淘宝海量数据架构:分布式MySQL与NoSQL解析
需积分: 10 64 浏览量
更新于2024-07-24
收藏 1.61MB PDF 举报
"该资源是关于淘宝数据架构的分析研究,涵盖了互联网公司的技术架构,特别是海量数据系统的构建。主要讨论了数据产品总体架构、分布式MySQL集群、NoSQL存储与计算、统一的数据中间层以及通用数据报表框架。内容还涉及到淘宝每天产生的大量数据,如店铺浏览、交易笔数,以及数据产品的需求,如统计汇总结果和数据查询请求。"
在淘宝的数据架构中,面对每天30亿次的店铺和宝贝浏览以及千万级别的交易,数据处理面临着巨大的挑战,包括计算能力、存储空间和高效读写的架构设计。为了应对这些挑战,淘宝采用了如下策略:
1. 分布式MySQL集群(MyFOX):为满足SQL查询、海量存储、可扩展性以及对应用透明的需求,淘宝构建了一个透明的中间层。通过分库分表,基于业务特点进行数据分布,同时引入冗余复制来提升小表、高访问频率表和JOIN操作的效率。分片规则根据路由字段的值进行条目切割,每个切片对应一个物理表,以分散压力并实现并行查询。
2. NoSQL存储与计算:在存储层,可能采用了如Hadoop这样的分布式计算框架来处理非结构化或半结构化数据,提供大规模数据处理能力。
3. 统一的数据中间层:淘宝可能使用了一种名为“云梯”的系统,作为数据中间层,它负责数据的装载、查询以及集群的管理。
4. 实时流数据处理:对于实时性的需求,淘宝可能利用了实时流数据处理技术,以便快速响应和处理源源不断的数据流。
5. 通用数据报表框架:淘宝数据魔方和淘宝指数等产品,利用数据中间层和查询层,提供了高效的数据报表生成和分析服务,同时也通过开放API向外部开发者开放部分数据。
6. DataX/TimeTunnel 和主站日志:这些工具和系统用于数据同步和迁移,确保数据的一致性和完整性。
7. 主站备库和RAC(Real Application Clusters):为了保证数据的安全性和高可用性,淘宝可能使用了数据库备份和高可用集群技术,如Oracle的RAC,来处理主站数据。
通过以上技术手段,淘宝构建了一套能够处理海量数据、支持高并发查询、具备弹性扩展能力和高效数据处理的架构。这套架构不仅服务于内部业务,也为用户和第三方开发者提供了丰富的数据服务。
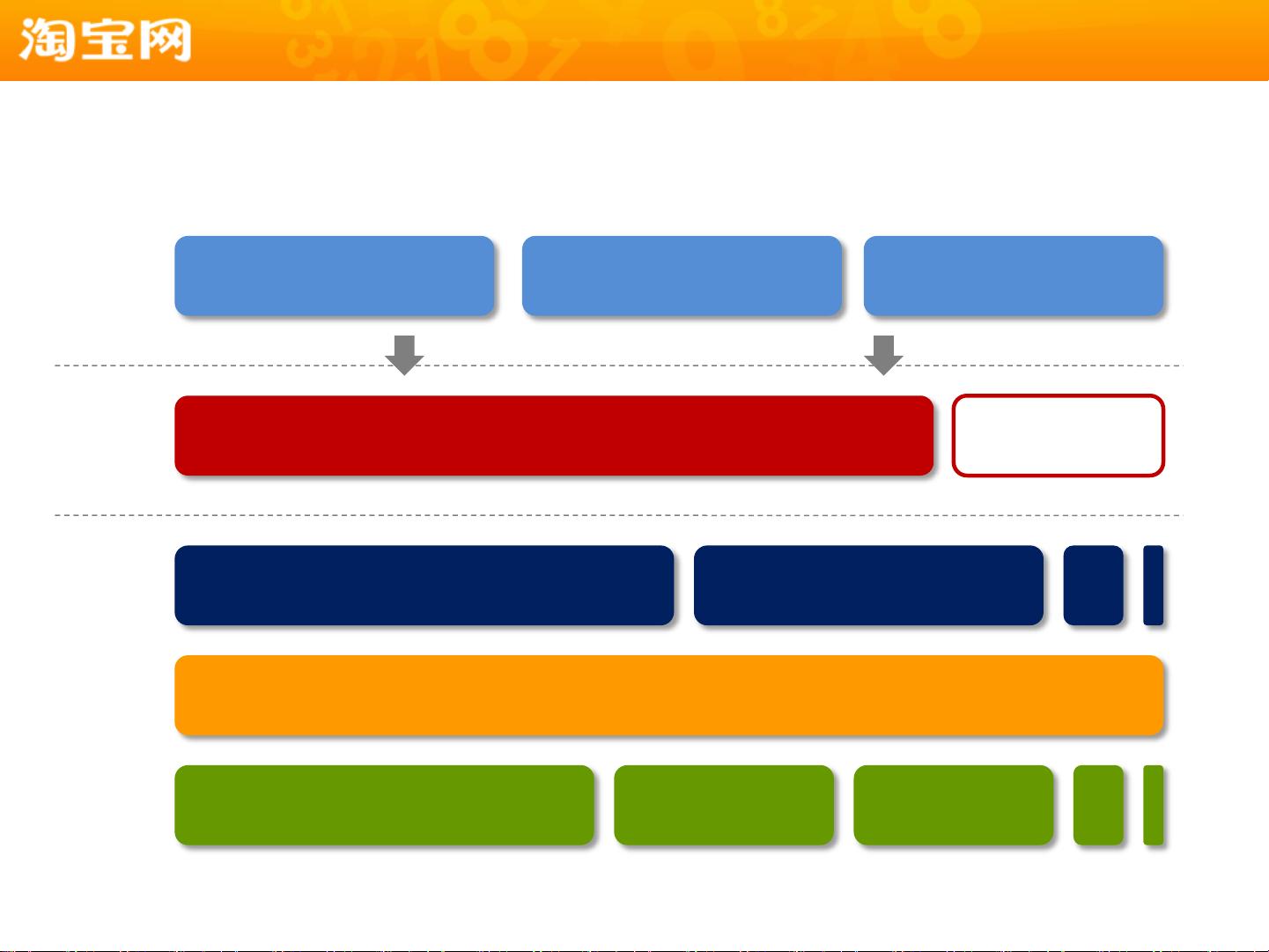
架构总览
MyFOX Prom
存
储
层
Hadoop集群
计
算
层
实时流数据
数据中间层 / glider
查
询
层
数据魔方 淘宝指数 开放API
产
品
DataX / TimeTunnel
主站备库 RAC 主站日志
数
据
源
剩余32页未读,继续阅读
2019-05-16 上传
2022-07-13 上传
2012-12-15 上传
2012-01-19 上传
2023-01-07 上传
2021-07-14 上传
2024-04-21 上传
2021-07-14 上传
2018-09-30 上传

zerosnow
- 粉丝: 4
- 资源: 49
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
