美团点评SRE在云端的发展与实战探索
133 浏览量
更新于2024-08-29
收藏 997KB PDF 举报
“云端的SRE发展与实践”
随着互联网行业的快速发展,SRE(Site Reliability Engineering)已经成为确保服务稳定性和效率的关键角色。SRE的概念起源于Google,它将软件工程的思维引入到运维工作中,旨在降低人工维护成本,提高服务的可用性(SLA)并优化资源利用率。
在美团点评这样的多元化互联网服务平台中,SRE面临着多重挑战。业务的快速扩张导致机器数量急剧增加,人工运维成本上升,同时对服务等级协议(SLA)的要求也越来越高。新业务可能遭遇大流量冲击,资源调度成为一大难题。此外,各种复杂多样的业务和技术方案使得SRE的工作变得更为复杂,增加了整体维护成本。
面对这些挑战,美团点评的SRE策略主要集中在三个方面:稳定性、效率和成本。稳定性的首要地位不言而喻,是SRE的核心任务。效率方面,涉及云主机交付速度和内部系统的运行效率,力求快速响应业务需求。成本控制则要求在有限的资源下提供最高质量的服务。
在SRE的演进历程中,经历了从“手工时代”到“云基础设施”的转变。早期,运维工作依赖于人工操作,没有成熟运维系统的支持。随着业务扩展,架构转向微服务化,引入了更多开发语言,并逐步迁移到云端。云基础设施的使用将主机和网络管理抽象化,提供了统一的平台接口,降低了运维复杂度。此时,SRE团队开始形成,分工明确,专注于业务层面的优化和问题处理。
在这一过程中,SRE团队面临的问题包括但不限于:服务的稳定性保障、资源的高效利用、快速应对流量波动等。解决方案可能涉及自动化运维工具的开发、监控系统的完善、故障恢复机制的建立、容量规划的优化以及持续集成/持续部署(CI/CD)的实施等。
SRE在云端的发展与实践是一个不断适应业务需求、提升服务质量、降低成本的过程。随着技术的不断进步,SRE的角色将会更加重要,不仅需要关注技术层面的优化,还需要深入理解业务,提供定制化的解决方案,以确保在复杂多变的环境中,服务能够持续、稳定、高效地运行。
云端的云端的SRE发展与实践发展与实践
背景
SRE(Site Reliability Engineering)是Google于2003年提出的概念,将软件研发引入运维工作。现在渐渐已经成为各大互联
网公司技术团队的标配。
美团点评作为综合性多业务的互联网+生活服务平台,覆盖“吃住行游购娱”各个领域,SRE就会面临一些特殊的挑战。
业务量的飞速增长,机器数量剧增,导致人工维护成本增大;而交易额的增长,对SLA的要求也不断提高。与此同时,一些新
业务会面临大流量冲击,资源调度的挑战也随之增大。
业务类型复杂多样、业务模型千差万别,对应的技术方案也多种多样,因此SRE的整体维护成本大大提高。
根据上述挑战,我们需要制定相应的解决策略,策略原则主要聚焦在以下三点:
1.稳定,这也是SRE工作的核心。
2.效率,包括云主机交付效率,也包括我们自己内部的一些系统效率。
3.成本,用最少的机器提供最优质的服务。
在此原则的基础上,我们开始了对SRE进行的一系列改进。
SRE演进之路
手工时代
最早期,我们前端是4层负载均衡,静态资源通过Varnish/Squid缓存,动态请求跑在LAMP架构下。这个时候机器很少,需要
的流程很少,也没有区分应用运维、系统运维之类的。运维人员也很少,网络、机器和服务都要负责。运维的工作大部分都是
靠手工,其实当时还没有成型的运维系统,现在很多初创公司都是这种架构。
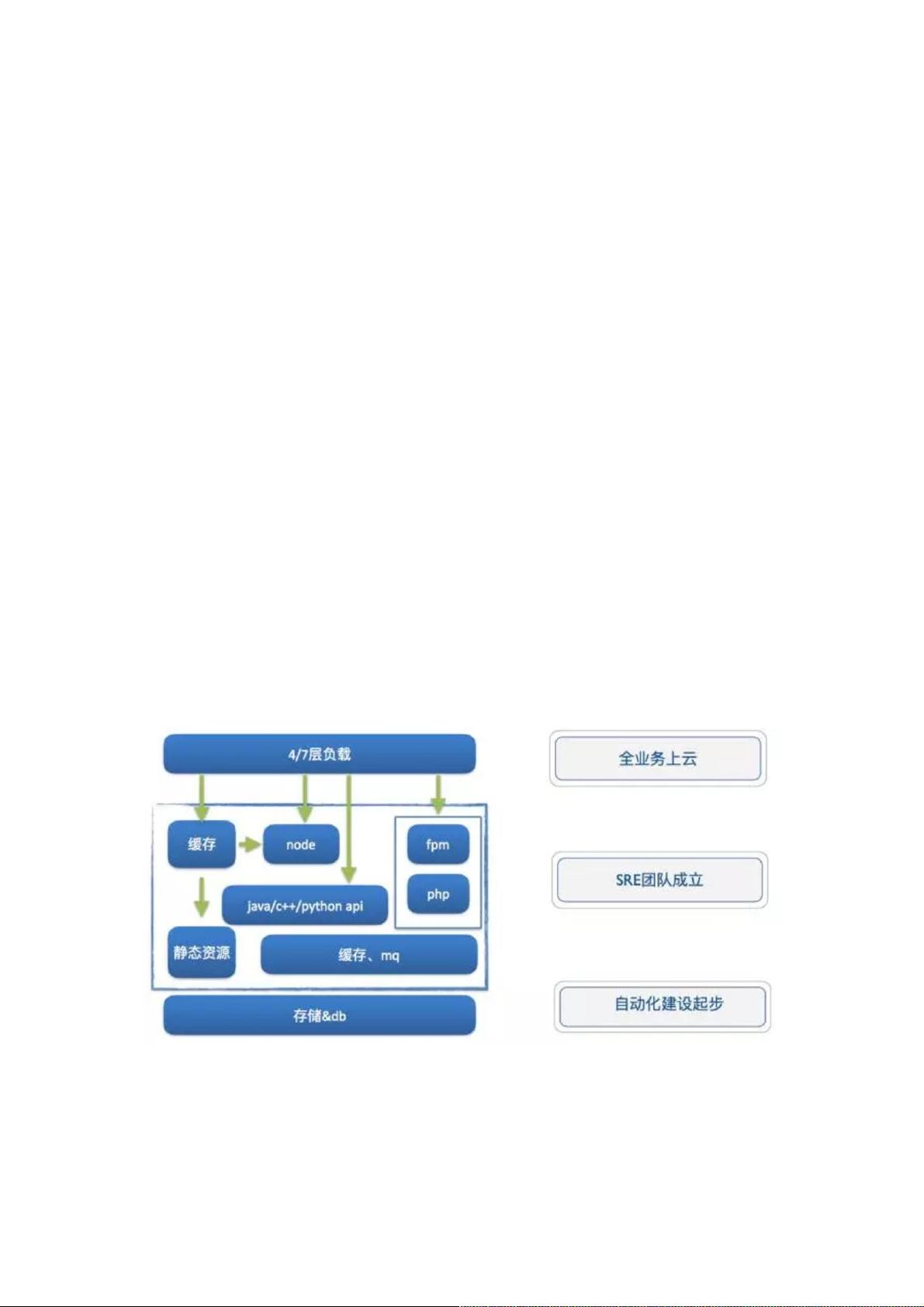
云基础设施
随着业务的发展,我们的架构也做出了适当的调整。尤其是在步入移动时代以后,移动的流量比重越来越大。接入层不只是
Web资源,还包含了很多API接口的服务。后端的开发语言也不再局限于PHP,根据服务需求引入了Java、Python、C++等,
整个业务架构开始向微服务化变迁。伴随业务架构的变化,底层的基础架构也随之改变。最大的变化是,2014年中的时候,
所有的业务已经都跑在了云上,如下图所示。
跑在云上的一个好处是把底层主机和网络抽象化,相当于云平台将主机创建、网络策略修改等封装到相应的系统内,对用户提
供统一的平台接口。我们在做维护的时候,就能把之前很复杂的流程串连起来。也是在此时,SRE团队初步成立,我们对整
个运维相关的工作做了拆分。云计算部分(由美团云负责)主要负责主机、网络,还有系统相关的;SRE对接业务侧,负责
机器的环境、业务侧的架构优化以及业务侧相关问题的处理。
问题&解决方案
接下来介绍一下我们在做云基础建设的过程中,遇到的问题和一些解决方案。
下载后可阅读完整内容,剩余6页未读,立即下载
2021-09-19 上传
2021-01-27 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38593644
- 粉丝: 4
- 资源: 914
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
