"电影推荐系统大数据实训案例:问题与解决方案"
需积分: 5 155 浏览量
更新于2024-01-11
3
收藏 19.87MB DOCX 举报
在电影推荐系统的大数据综合实训项目中,我们面临了以下几个主要问题,并采取了相应的解决方案:
问题1:数据规模和处理效率
由于电影数据集非常庞大,我们需要高效地处理和分析大量的数据。为解决这个问题,我们使用了Apache Spark作为主要的数据处理工具。Apache Spark具有并行计算和分布式架构的优点,可以大大提高数据处理效率。
解决方案:我们根据数据集的规模和处理需求,将数据分成小块进行并行处理,并利用Spark的内存计算能力和分布式存储功能,提高数据处理的效率和速度。此外,我们还对数据进行预处理、清洗和归约,以减少数据处理的复杂度和时间。
问题2:推荐算法选择与优化
在实现电影推荐功能时,我们面临了选择和优化推荐算法的挑战。不同的推荐算法对用户的喜好和行为有不同的考虑因素,因此需要选择合适的算法,并对其进行优化,以提高推荐结果的准确性和性能。
解决方案:我们采用了协同过滤算法,包括基于用户的协同过滤和基于物品的协同过滤。通过分析用户的历史浏览记录、评分和喜好,我们可以建立用户之间的相似度模型和物品之间的关联度模型。然后,根据这些模型,我们可以预测用户对未知物品的喜好,并向其推荐相似的电影。
为了优化算法的性能,我们调整了算法的参数和模型配置,并进行了模型评估和优化。通过交叉验证和测试集的准确性评估,我们不断改进和优化推荐模型,以提高推荐结果的质量和精确度。
问题3:用户反馈和评价
为了改进推荐系统,我们需要收集用户的反馈和评价。然而,如何有效地获取用户反馈是一个具有挑战性的问题。为解决这个问题,我们设计了一个用户界面,让用户可以方便地给出反馈和评分。
解决方案:我们在推荐系统中添加了一个用户界面,用户可以在其中浏览电影、查看推荐结果,并给出反馈和评分。通过收集用户的反馈和评分数据,我们可以分析和理解用户的喜好和行为。结合用户行为数据和评分数据,我们可以不断优化推荐模型,提高用户满意度。
问题4:系统可扩展性和并发性
由于大量用户可能同时访问推荐系统,我们需要保证系统具有良好的可扩展性和并发性,以确保系统的稳定性和性能。
解决方案:为解决这个问题,我们使用了分布式计算和存储技术,将电影推荐系统部署在具有可扩展性的云平台上。同时,我们对系统进行水平扩展,通过增加服务器的数量和分布式存储的容量,来应对并发访问的压力。此外,我们还进行了负载均衡和故障恢复的设计,以确保系统的可用性和稳定性。
总结:
在电影推荐系统的大数据综合实训项目中,我们通过使用Apache Spark进行高效的数据处理,选择和优化推荐算法,设计用户界面收集用户反馈,以及保证系统的可扩展性和并发性,解决了数据规模和处理效率、推荐算法选择与优化、用户反馈和评价、系统可扩展性和并发性等一系列挑战。通过不断地改进和优化,我们成功地实现了一个准确、高效并具有良好用户体验的电影推荐系统。

11
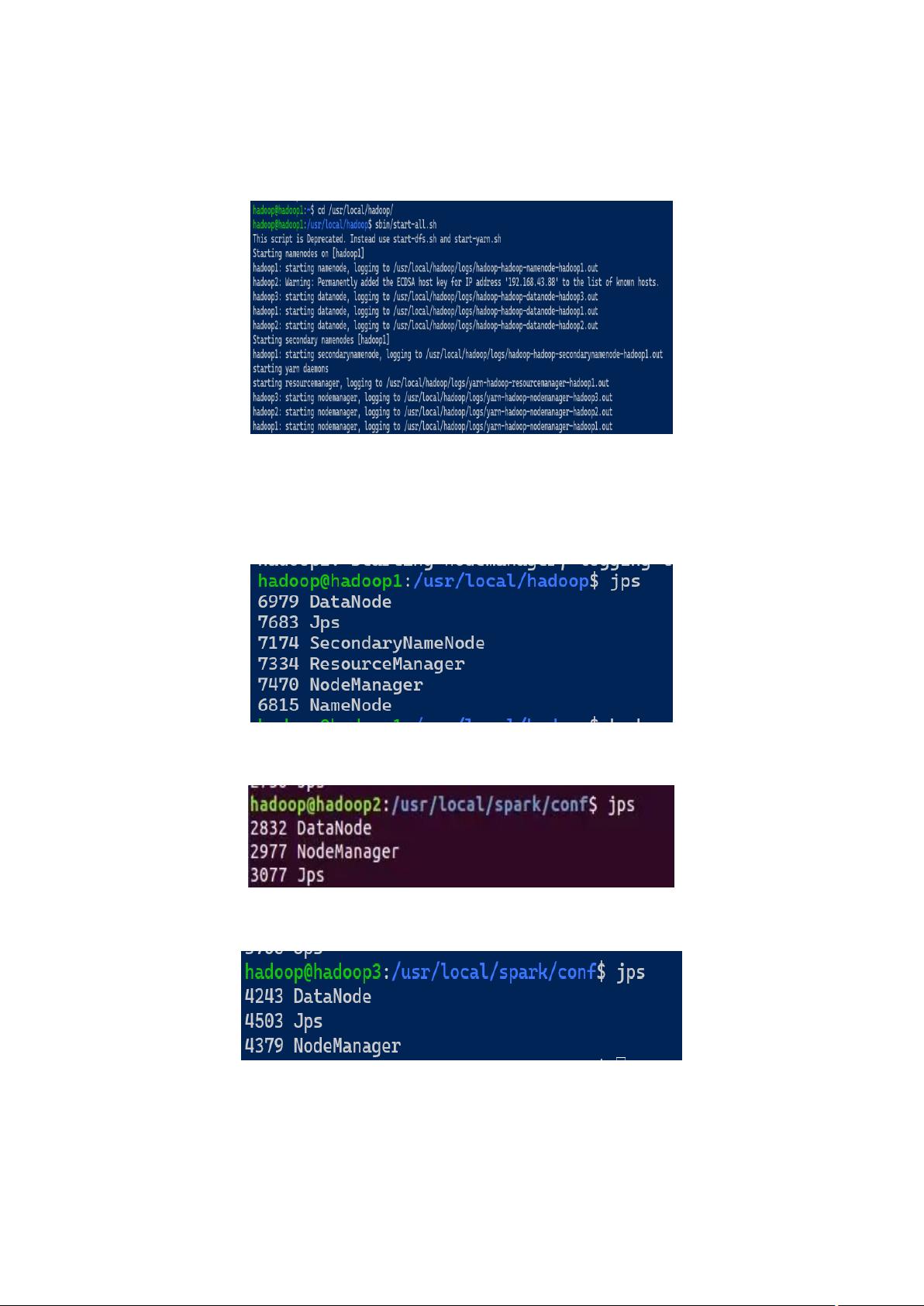
同样的,我们需要先将 template 文件拷贝重命名。
将 spark-env.sh.template 拷贝到 spark-env.sh
$ cp ./spark-env.sh.template ./spark-env.sh
分别在三台虚拟机上修改 spark-env.sh 文件:
hadoop1:
图 2-11 更改名称
hadoop2:
图 2-12 更改名称
hadoop3:
图 2-13 更改名称
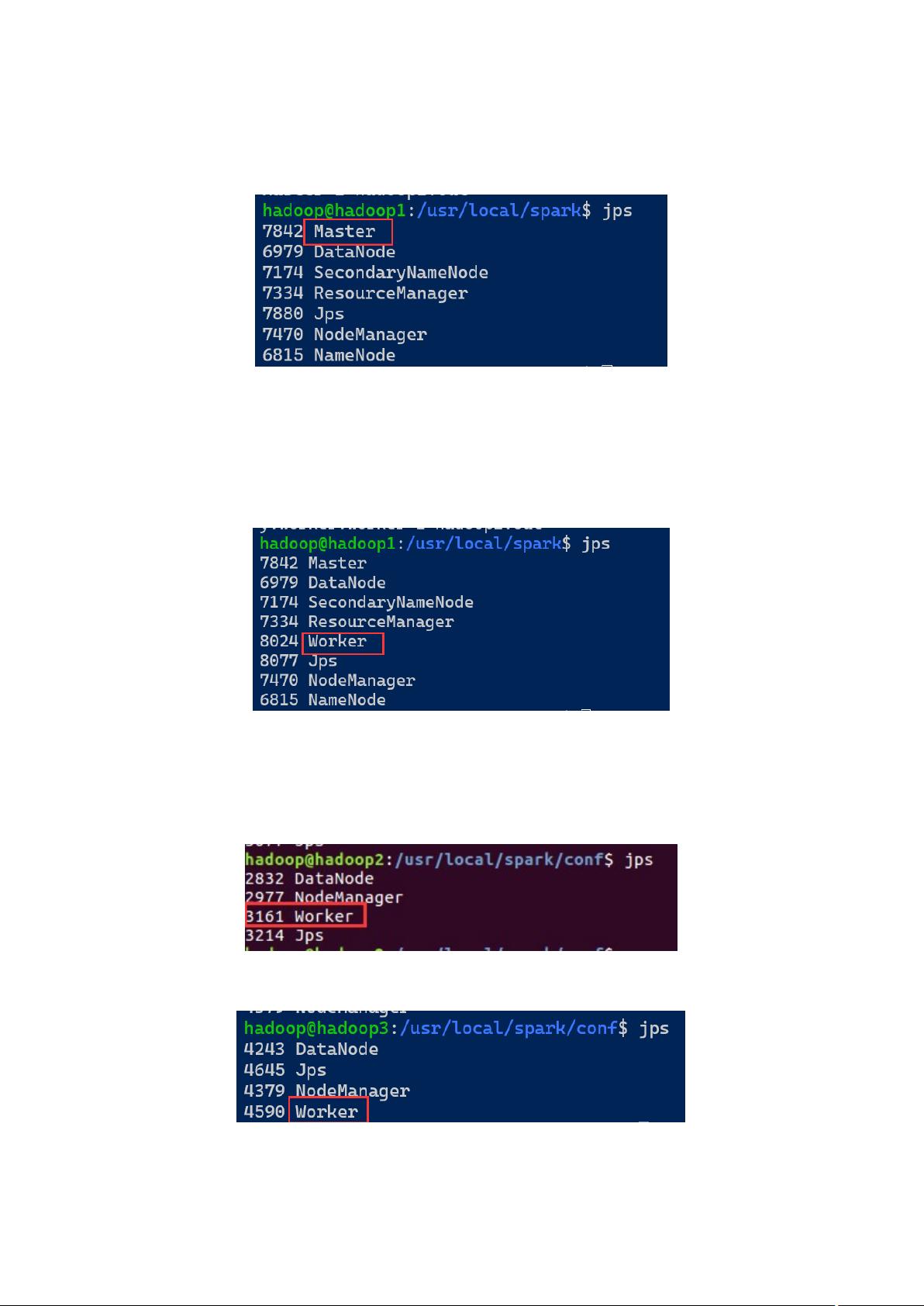
c)集群规划
节点
spark 节点
hadoop 节点
hadoop1
master
worker
datanode
namenode
secondarynamenode(hadoop)
resourcemanager
nodemanager(yarn)
hadoop2
worker
datanode nodemanager
hadoop3
worker
datanode nodemanager
剩余69页未读,继续阅读
2022-06-21 上传
2022-07-03 上传
2023-06-26 上传
2023-07-11 上传
2023-06-10 上传
2023-02-24 上传
2023-05-30 上传
2023-05-31 上传

肉肉肉肉肉肉~丸子
- 粉丝: 284
- 资源: 157
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
