探索Flink核心技术:流处理与批处理的统一平台
125 浏览量
更新于2024-08-28
收藏 462KB PDF 举报
Apache Flink,作为一个新兴的大数据处理框架,以其独特的设计理念和高效性能吸引了众多关注。它不同于传统的MapReduce、Spark和Storm等框架,Flink的核心是流式数据流执行引擎,专注于数据流的分布式计算,提供了数据分布、数据通信和容错机制,这使得它能够在实时性和批处理之间实现无缝切换。
Flink的主要特性包括三个核心API:DataSet API、DataStream API和Table API。DataSet API专用于批处理操作,允许用户以分布式数据集的形式处理静态数据,提供丰富的操作符支持,涵盖Java、Scala和Python等多种编程语言。DataStream API则针对流处理,将数据视为连续的数据流,支持实时操作,仅限于Java和Scala。Table API则引入了结构化数据查询的概念,用户可以使用类SQL的Domain Specific Language (DSL) 对关系表进行查询,同样支持Java和Scala。
除了基础API,Flink还针对特定应用场景提供了扩展库,如FlinkML用于机器学习,提供了机器学习管道和多种算法实现;Gelly则专注于图计算,提供图算法的API。这表明Flink不仅仅是一个通用的大数据处理工具,它还能够满足复杂的业务需求。
Flink技术栈的完整性使其能够与Hadoop生态系统无缝集成,比如读取HDFS或HBase中的数据,或者使用Kafka作为流数据源。更重要的是,Flink能够将批处理和流处理任务统一在一个平台上执行,打破了传统框架对任务类型的限制,这意味着开发者可以在同一个系统中灵活处理实时和批量数据,提高了效率和灵活性。
总结来说,深入理解Apache Flink的核心技术包括其流式数据流执行引擎、多模式API的设计、领域库的支持以及与Hadoop生态系统的集成能力。掌握这些核心特性和优势,对于大数据处理开发者来说,无疑能够提升其在实时和批处理场景下的解决方案构建能力。
深入理解深入理解ApacheFlink核心技术核心技术
Apache Flink(下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越
来越多人的关注。本文将深入分析Flink的一些关键技术与特性,希望能够帮助读者对Flink有更加深入的了解,对其他大数据
系统开发者也能有所裨益。本文假设读者已对MapReduce、Spark及Storm等大数据处理框架有所了解,同时熟悉流处理与批
处理的基本概念。
Flink简介
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于
流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符
对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各
种操作,支持Java和Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支
持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
Gelly,Flink的图计算库,提供了图计算的相关API及多种图计算算法实现。
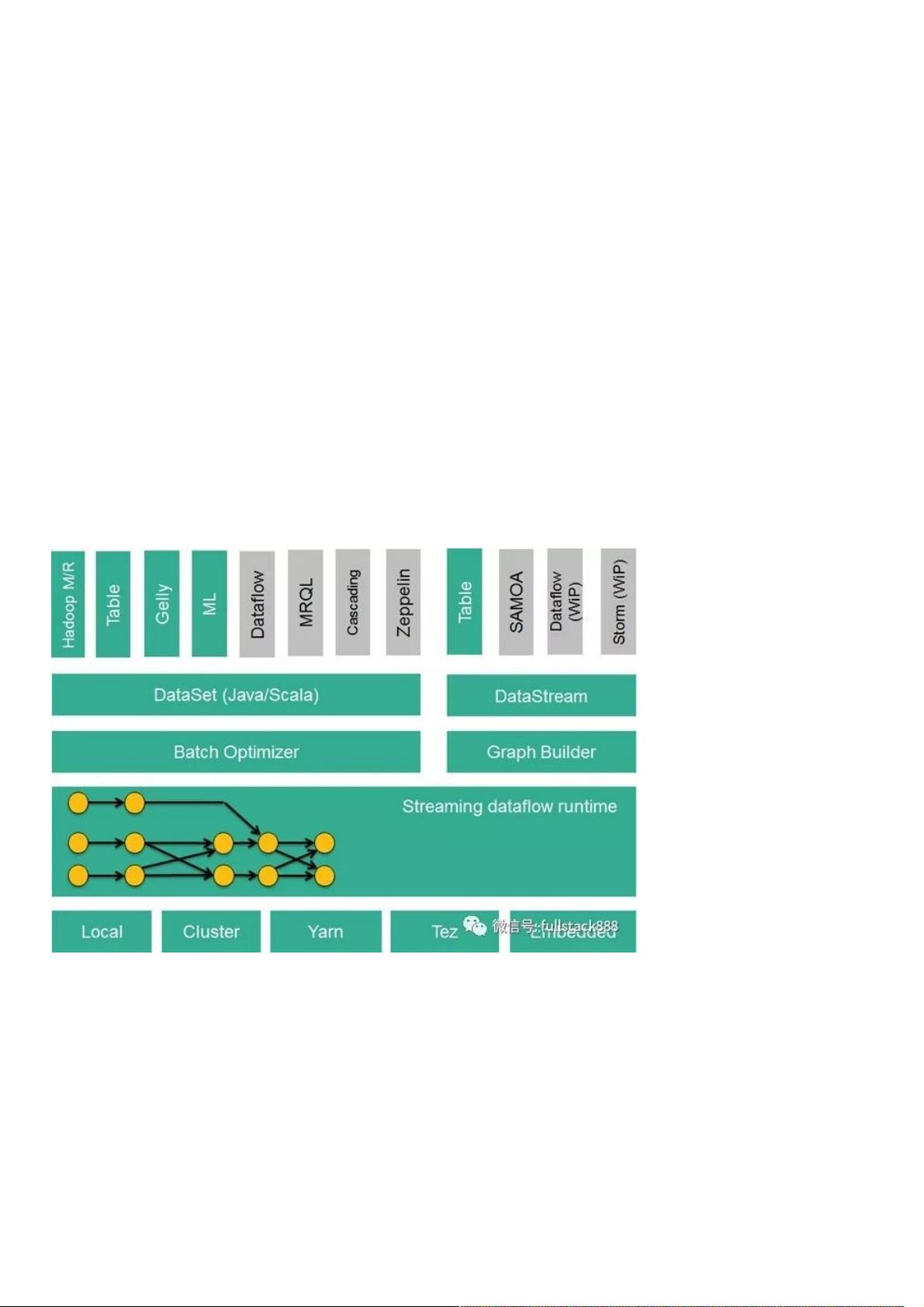
Flink的技术栈如图1所示:
图1 Flink技术栈
此外,Flink也可以方便地和Hadoop生态圈中其他项目集成,例如Flink可以读取存储在HDFS或HBase中的静态数据,以
Kafka作为流式的数据源,直接重用MapReduce或Storm代码,或是通过YARN申请集群资源等。
统一的批处理与流处理系统
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据项目一般会被设计为只能处理其中一
种任务,例如Apache Storm、Apache Smaza只支持流处理任务,而Aapche MapReduce、Apache Tez、Apache Spark只支
持批处理任务。Spark Streaming是Apache Spark之上支持流处理任务的子系统,看似一个特例,实则不然——Spark
Streaming采用了一种micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的
Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Apache Storm、Apache Smaza
等完全流式的数据处理方式完全不同。通过其灵活的执行引擎,Flink能够同时支持批处理任务与流处理任务。
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式。对于一个流处理系统,其节点间数据传输
的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。
而对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-07-26 上传
2020-05-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-12-25 上传

weixin_38591291
- 粉丝: 6
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







最新资源
- example-website:在以下网站发布事件的示例网站
- 学习201
- 电力设备行业:特斯拉产能加速扩建,光伏平价时代方兴未艾.rar
- TechAvailabilityBot
- whoistester WrapEasyMOnkey:查看monkeyrunner 脚本的交互jython 库-开源
- vc游戏编程库的源程序,如A*算法 A星算法 AStar自动寻路算法
- GenomicProcessingPipeline:用于处理“原始”基因组数据的管道(全基因组测序,RNA测序和靶标捕获测序)
- 行业文档-设计装置-一种制备弯曲钢绞线的装置.zip
- config-server-data
- 蓝桥杯嵌入式 mcp4017 iic
- com.tencent.mtt.apkplugin.ipai9875.zip
- kokoa-talk:带有克隆编码(HTML,CSS)
- TaTeTi:TaTeTi多人游戏(进行中)
- 下午
- the-button-clicker:自动按下 reddit 上的“按钮”的 chrome 扩展
- 行业文档-设计装置-一种切纸机的斜刀连动机构.zip
