视频语义共分割:对象发现与理解
需积分: 10 146 浏览量
更新于2024-07-20
收藏 15.38MB PDF 举报
"Semantic Co-segmentation in Videos" 是一篇发表在ECCV2016上的计算机视觉领域的研究论文,主要关注的是视频中的语义协同分割技术。这项工作旨在在没有预先知识的情况下,通过分析一系列相关视频来识别并分割出物体,并理解其视觉语义。
在视频对象分割这个复杂任务中,由于物体外观的变化、形状的变形以及混乱的背景,使得自动发现和分割物体极具挑战性。为此,论文提出了一种新的方法——语义协同分割。该方法首先从视频中提取语义对象,并利用基于追踪的技术生成跨视频的多个类似物体的轨迹(tracklets)。每个轨迹包含了时间上连续的片段,并与预测的类别相关联。
为了利用其他视频中的丰富信息,研究者收集了所有视频中被分配到相同类别的轨迹,并通过解决次模函数来共同选择真正属于目标物体的轨迹。这个次模函数考虑了如外观、形状和运动等物体属性,有助于协同分割过程的优化。这种方法能够更好地处理视频中的变化和不确定性,提高分割的准确性和鲁棒性。
实验部分展示了该算法在三个视频对象分割数据集上的表现优于其他现有的先进方法,证明了其有效性和实用性。作者 Yi-Hsuan Tsai、Guangyu Zhong 和 Ming-Hsuan Yang 分别来自加州大学默塞德分校和大连理工大学,他们的研究工作为视频分析和理解领域提供了新的视角和工具,对于后续的视频处理和智能监控应用具有重要价值。
4 Y.-H. Tsai, G. Zhong, M.-H. Yang
...
...
...
...
Input Videos
Semantic Tracklets
Generation
Semantic Tracklets
Co-selection
Semantic
Segmentation
...
...
...
...
...
...
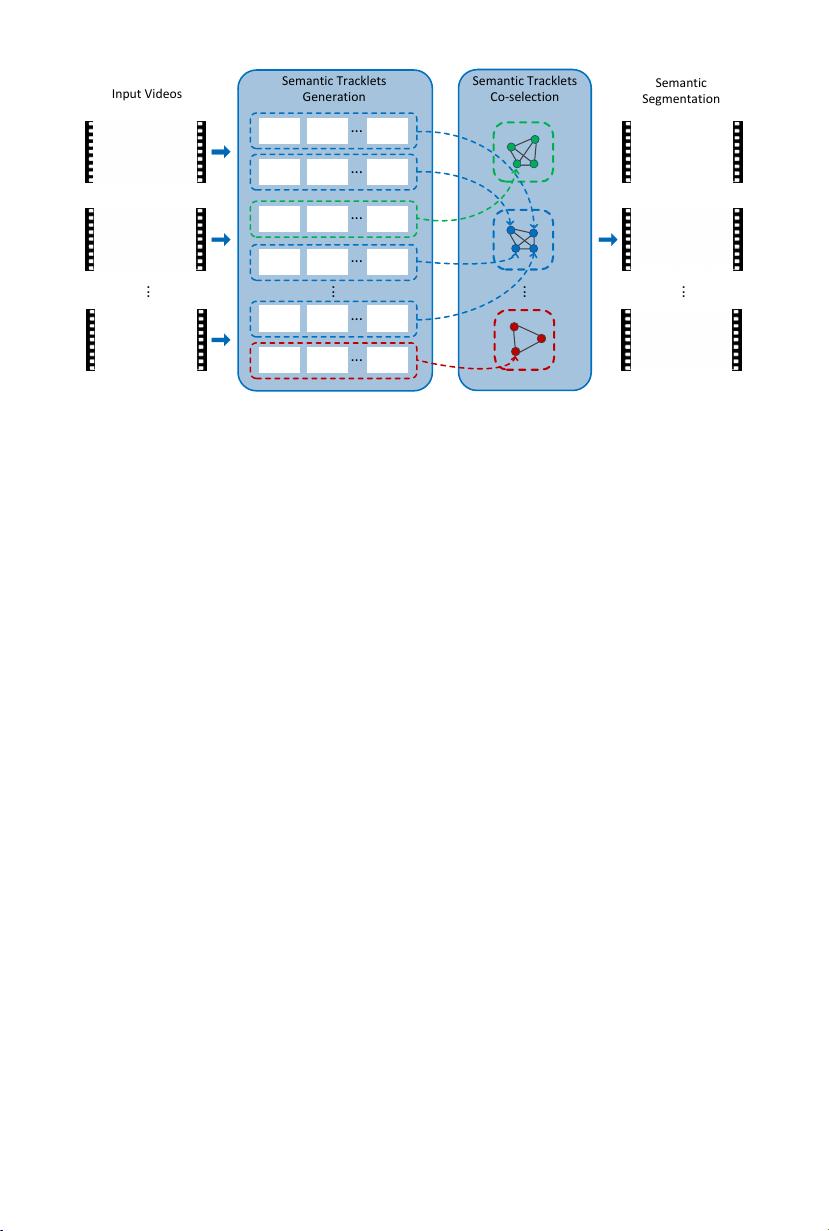
Fig. 1. Overview of the proposed algorithm. Given a collection of videos without pro-
viding category labels, we aim to segment semantic objects. First, a set of tracklets
is generated for each video, and each tracklet is associated with a predicted category
illustrated in different colors (e.g., blue represents the dog and red represents the cow).
Then a graph that connects tracklets as nodes from all videos is constructed for each
object category. We formulate it as the submodular optimization problem to co-select
tracklets that belong to true objects (depicted as glowing nodes), and produce final
semantic segmentation results.
cluster segments and eliminate clusters containing noisy segments through the
video. Among the selected clusters with object segments, we randomly choose a
few of them as initializations and apply a spatial-temporal graph-based tracking
algorithm to generate tracklets. Each tracklet maintains coherent appearances
of an object region (segment) in the spatial and temporal domains.
However, tracklets may still contain only object parts or noisy background
clutters, and the available visual information is limited within each video. We
construct a graph that connects tracklets within the same category from all
videos as nodes, and utilize a submodular function to define the corresponding
relations based on their appearances, shapes and motions. After maximizing this
submodular function, tracklets are ranked according to their mutual similarities,
and hence prominent objects can be discovered in each video. Fig. 1 shows the
overview of the proposed algorithm.
3.2 Semantic Tracklet Generation
Video object segmentation methods usually utilize object proposals in each frame
to detect where instances may appear [6,14,15,34]. One challenge is to associate
thousands of proposals from different objects while maintaining temporal con-
nections for each of them across all sequences. Here, we propose to utilize a
semantic segmentation algorithm (e.g., FCN) to generate object segments as
initializations, and then construct a spatial-temporal graphical model to track
剩余15页未读,继续阅读

1LOVESJohnny
- 粉丝: 244
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
