Hadoop入门详解:WordCount实例剖析与架构解析
Hadoop 是一个开源的分布式计算框架,由 Apache Software Foundation 发布,旨在解决大规模数据处理问题。它主要针对的是数据密集型应用,尤其是那些无法在单台机器上处理的数据集。Hadoop 通过将大数据分解成更小的部分,然后在多台计算机上并行处理,提高了计算效率和容错性。
在 Hadoop 的架构中,关键组件包括:
1. **Master 节点 (Master)**: 主要指 NameNode 和 JobTracker,它们是 Hadoop 集群的核心管理器。
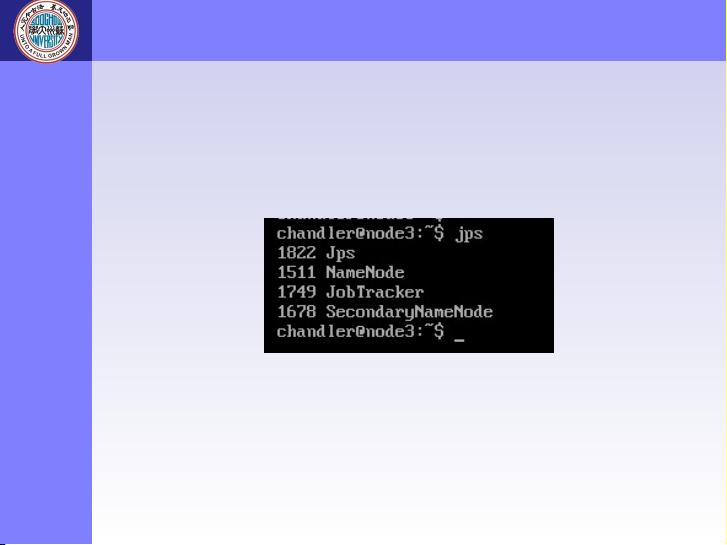
- **NameNode**: 是 Hadoop 分布式文件系统 (HDFS) 的名称节点,负责存储元数据,如文件系统的目录树和块位置信息。它保证了文件的一致性和完整性。
- **JobTracker**: 在 MapReduce 模型中,负责作业调度和监控,协调任务在集群中的执行。
2. **Slave 节点 (Slaves)**: 包括 TaskTracker,这些是执行实际计算任务的节点。在 Hadoop 早期版本中,它们也包含 DataNode,负责存储数据块。
3. **Secondary NameNode**: 辅助 NameNode,定期与主名称节点同步元数据,以减少主节点的负载。
4. **MapReduce**: Hadoop 的核心计算模型,分为两个阶段:Map 和 Reduce。Map 阶段将输入数据分割成小块,并在各个 TaskTracker 上并行处理,而 Reduce 阶段则收集 Map 结果进行汇总。
5. **HDFS (Hadoop Distributed File System)**: 是 Hadoop 的分布式文件系统,设计用于高效地存储和访问大量数据。它具有高容错性,即使部分节点故障,仍能继续服务。
6. **JVM (Java Virtual Machine)**: Hadoop 使用 Java 编程,运行在 JVM 上,使得其具有高度可移植性。
7. **实用工具**: Hadoop 提供了一套实用工具,如 Hadoop fs、Hadoop shell 等,用于方便用户管理和操作 HDFS,以及运行 MapReduce 作业。
8. **部署环境**: Hadoop 通常部署在 Linux 操作系统环境中,因为其对硬件资源的需求较低,而且与开源软件生态兼容。
在您提到的具体实例中,WordCount 是 Hadoop 中的一个经典示例,它展示了如何利用 MapReduce 将文本文件拆分成单词,计算每个单词出现的频率。这个过程涉及创建 Mapper 和 Reducer,以及 JobTracker 分配任务。实验结果的总结和详细的步骤包括数据划分、Mapper 对数据的处理、Shuffle 过程(数据在节点间传输),以及Reducer 对中间结果的合并和输出。
通过 WordCount 示例,用户可以了解 Hadoop 的工作原理,以及如何在实际场景中实现大规模数据处理。同时,这个例子也体现了 Hadoop 的并行计算优势和容错特性。
剩余15页未读,继续阅读
2013-10-18 上传
157 浏览量
175 浏览量
125 浏览量
183 浏览量
111 浏览量
2023-06-12 上传
2024-02-03 上传
111 浏览量

chwzhguo
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 叉车变矩器故障诊断及处理.rar
- BULLDOG-开源
- 草图设备:一些草图格式的设备
- libdaisy-rust:菊花板的硬件抽象层实现
- clangular:lan角
- 行业文档-设计装置-一种拒油抗静电纸质包装材料.zip
- ICLR-Workshop-Challenge-1-CGIAR-Computer-Vision-for-Crop-Disease:Zindi竞赛的入门代码-ICLR Workshop Challenge#1
- aklabeth:Akalabeth aka'Ultima 0'的翻拍-开源
- snglpg:Занимаясь“在浏览器中设计”
- OpenCore-0.6.2-09-09.zip
- 摩尔斯电码,实现将字符转为摩尔斯电码的主体功能,能将摩尔斯电码通过串口上位机进行显示
- matlab布朗运动代码-Zombie:用于团队项目的MATLAB僵尸启示仿真(2016)
- 纯css3圆形发光按钮动画特效
- mvntest
- 版本:效用调查,专家和UX使用者,请指责一个集体经济团体,请参阅一份通俗的经济通函,一份从业者的各种困难和疑难解答,请参见网站实际内容
- OpenCore-0.6.1-09-08正式版.zip
