Elasticsearch入门与API实践:高效全文检索技术详解
需积分: 0 130 浏览量
更新于2024-07-15
收藏 1.6MB PDF 举报
Elasticsearch 是一款开源的分布式全文搜索引擎,专为大规模非结构化数据提供高效、实时的搜索和分析功能。本文档全面介绍了 Elasticsearch 的概念、应用场景以及如何在实际开发中使用它。
首先,全文检索是针对非结构化数据的搜索技术,这些数据包括办公文档、文本、图片等多种格式,它们不遵循固定的结构,搜索时通常依赖于内容而非预定义的字段。传统的搜索方式如 Windows 搜索文件内容或 Linux 下的 grep 命令,采用顺序扫描的方式,随着数据量的增加,效率会明显降低。
Elasticsearch 利用了索引这一关键概念,通过将非结构化数据转换为结构化的形式。索引是对原始数据进行预处理和分析的结果,其中包含重要的元数据和关键词信息。通过构建索引,Elasticsearch 可以实现快速的搜索性能,无论是全文搜索还是基于关键词的查询,都能迅速返回结果。这得益于其倒排索引(Inverted Index)的设计,使得对文档中特定词汇的查询变得高效。
文档中提到,Elasticsearch 支持多种调用方式,包括 HTTP 调用和 Java API。HTTP 调用允许开发者通过 RESTful 接口与 Elasticsearch 交互,而 Java API 提供了更深入的控制和定制选项,适合进行复杂的数据操作和集成到 Java 应用程序中。
例如,对于 Java 开发者来说,可能会涉及到以下步骤:
1. 安装和配置 Elasticsearch:确保服务器环境已正确安装,并设置集群和节点,以支持高可用性和扩展性。
2. 文档管理:使用 Java API 将数据(如 JSON 对象)索引到 Elasticsearch 中,包括定义索引模板和映射(Mapping)以指定数据结构。
3. 查询和搜索:通过执行搜索请求,如 GET、POST 或 DELETE,向 Elasticsearch 发送查询字符串或 JSON 请求,获取与指定条件匹配的文档列表。
4. 示例代码演示:文档中可能包含了使用 Java API 进行基本查询(如 `GET /my_index/_search`)、分页(`from` 和 `size` 参数)、过滤(`filter_path`)以及聚合(aggregation)的示例。
在使用过程中,Elasticsearch 还提供了丰富的查询语法,如布尔查询、范围查询、模糊查询,以及高级功能如地理位置搜索、自定义分析器和分析器链等。此外,为了优化性能,Elasticsearch 还支持分片(Sharding)和复制(Replication)策略,以及索引级别的缓存机制。
总结来说,Elasticsearch 是一个强大的全文检索工具,适用于大规模非结构化数据处理,它的高效索引技术和灵活的 API 接口使得它在现代数据管理和分析场景中占据了重要地位。通过理解和掌握其工作原理和使用方法,开发者可以轻松地将 Elasticsearch 集入到自己的应用中,提升数据搜索和分析的效率。
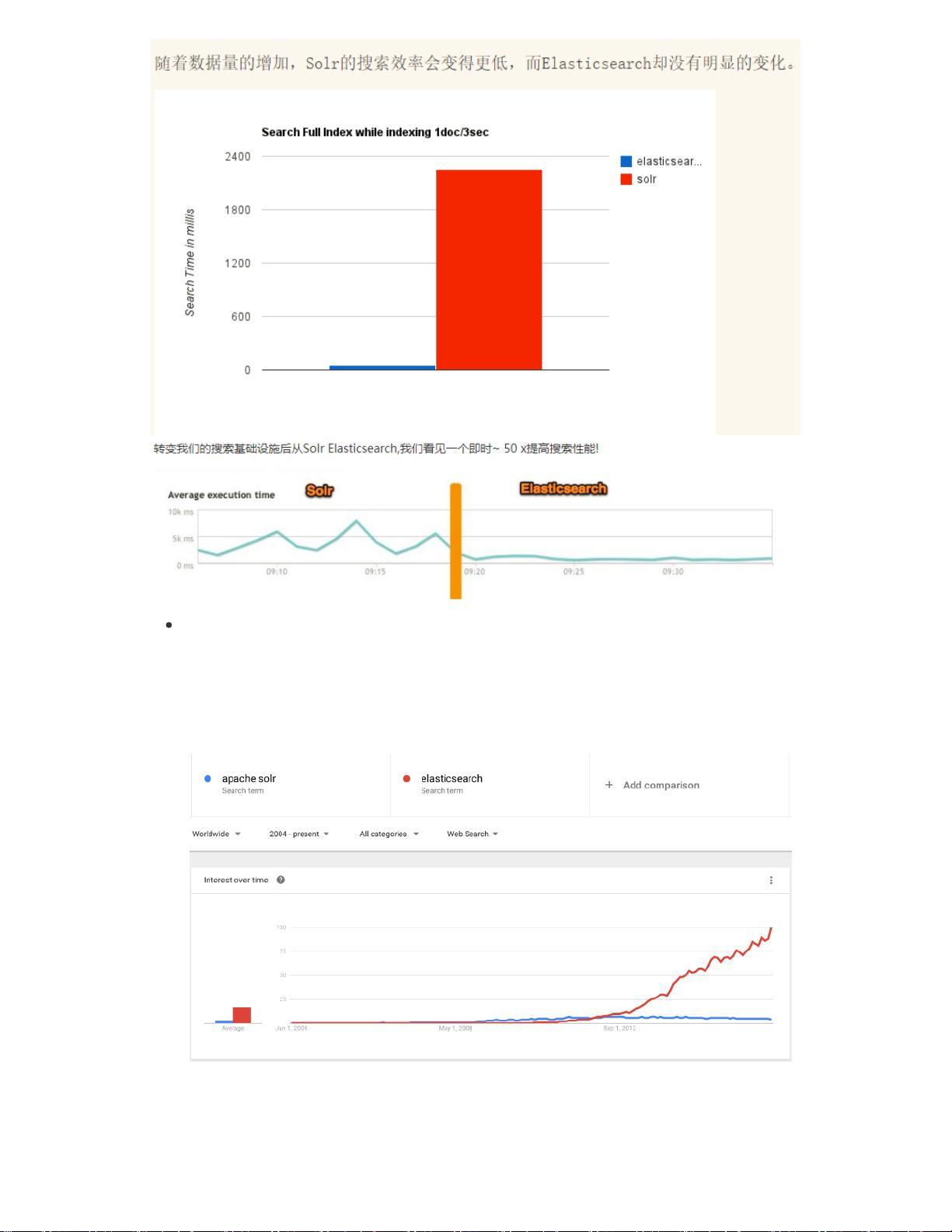
(1)es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢,可关注
(2)Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理
功能。
近几年的流行趋势
我们查看一下这两种产品的Google搜索趋势。谷歌趋势表明,与 Solr 相比,
Elasticsearch具有很大的吸引力,但这并不意味着Apache Solr已经死亡。虽然有些
人可能不这么认为,但Solr仍然是最受欢迎的搜索引擎之一,拥有强大的社区和开源
支持。
总结:

剩余45页未读,继续阅读
2019-11-18 上传
2019-12-31 上传
2019-06-05 上传
2024-06-21 上传
2024-03-12 上传
2021-09-01 上传

拖拉机s
- 粉丝: 57
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
