Spark设计与实现解析:从逻辑到物理执行的深度探讨
"Apache Spark 设计与实现 PDF 中文版"
Apache Spark 是一个开源的大数据处理框架,它专注于提供快速、通用且可扩展的数据处理能力。本文档深入探讨了Spark的设计理念、工作原理、架构实现以及性能优化策略,并对比了Spark与Hadoop MapReduce在设计和实现上的差异。
1. **总体介绍**
Spark的核心设计理念是内存计算,通过将数据存储在内存中,减少磁盘I/O,从而实现高效的迭代计算和交互式数据分析。它的设计目标是提供低延迟和高吞吐量的计算能力。
2. **Job逻辑执行图**
Job的逻辑执行图(Logical Plan)展示了任务的计算逻辑,它是一个有向无环图(DAG),反映了数据的依赖关系。在这个阶段,Spark将用户编写的DataFrame或Dataset操作转换为一系列的transformations和actions。
3. **Job物理执行图**
在逻辑执行图的基础上,Spark生成物理执行图(Physical Plan),这是实际执行的任务结构。这个过程涉及到对DAG的优化,例如通过Stage划分和Task生成,最小化数据传输和重用计算结果。
4. **Shuffle过程**
Shuffle是Spark中关键的数据重新分布过程,它发生在数据需要跨分区重新排列时。Shuffle会导致数据在网络间传输,并可能导致磁盘临时文件的生成,因此理解和优化shuffle对于提升性能至关重要。
5. **系统架构**
Spark的架构包括Driver程序、Executor和Cluster Manager。Driver负责构建和调度作业,Executors在工作节点上运行任务并管理内存,而Cluster Manager(如YARN或Mesos)负责资源分配。
6. **Cache和Checkpoint功能**
Spark提供了两种数据持久化机制:cache(内存缓存)和checkpoint(持久化到磁盘)。它们用于加速计算,特别是对于需要重复使用的数据集,通过缓存可以避免重复计算。
7. **Broadcast功能**
广播变量(Broadcast Variables)是Spark为了节省网络带宽而设计的特性,它可以将大对象一次性发送到每个executor,而不是每次任务执行时都发送,这对于广播小但大的常量数据非常有用。
8. **Job调度**
Spark的调度系统负责决定何时以及如何执行任务。它可以根据资源需求、优先级和公平性策略进行调度,例如FIFO(先进先出)和FAIR(公平调度)调度器。
文档作者采用问题驱动的方式,从实际问题出发,逐步揭示Spark的工作流程,这种方式有助于读者更好地理解Spark的内在机制。由于Spark社区的快速发展,文档会随着Spark的新版本进行更新,确保内容的时效性。尽管目前主要讨论的是Spark Core Standalone模式下的核心功能,但作者鼓励社区成员共同参与,丰富和完善文档内容。
通过本文档,读者可以深入了解Spark如何处理大数据任务,以及如何进行性能调优,这对于想要深入研究Spark或者在实际项目中应用Spark的开发者来说,是一份非常有价值的参考资料。

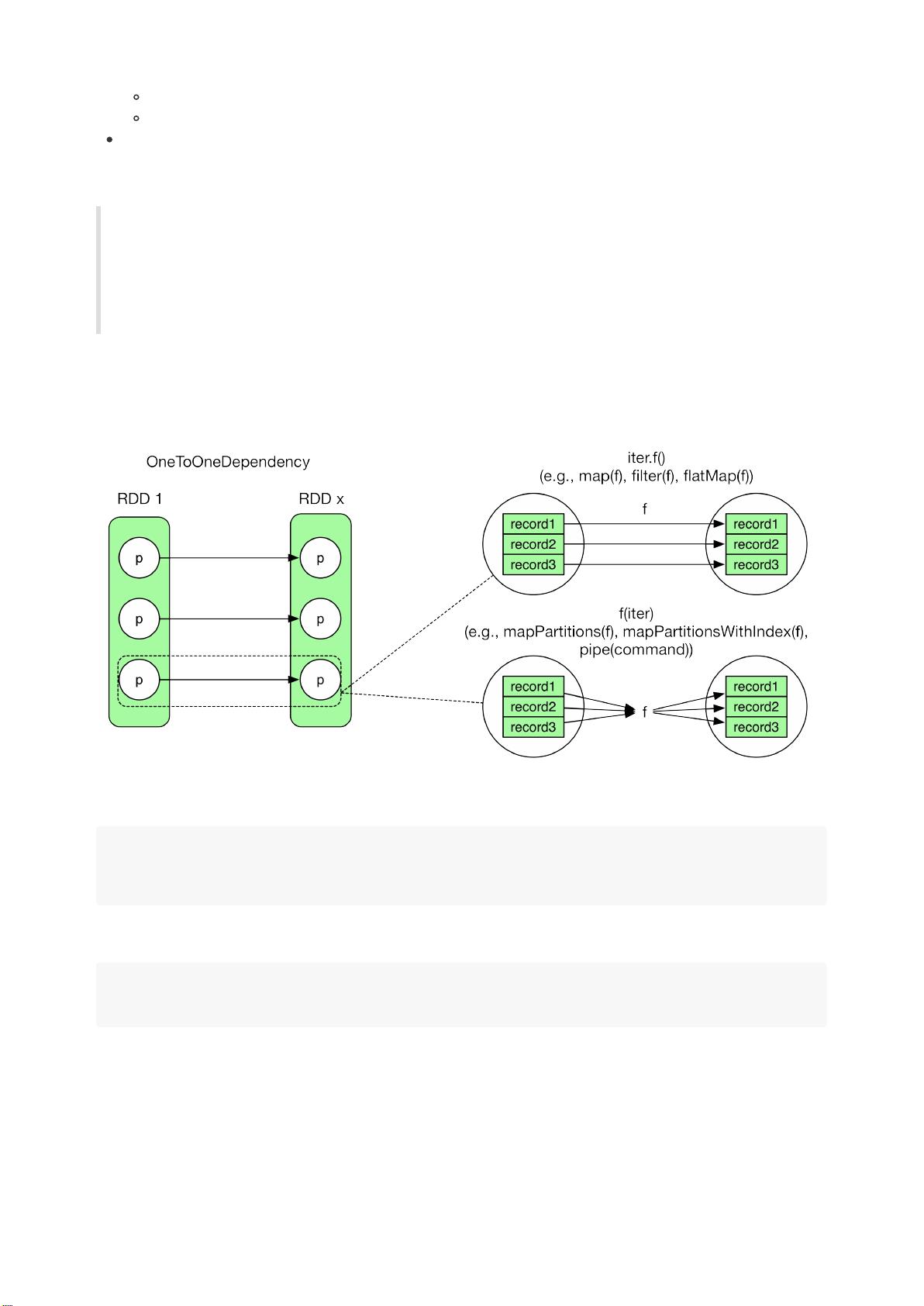
perform?每个RDD里有compute()方法,负责接收来自上一个RDD或者数据源的inputrecords,perform
transformation()的计算逻辑,然后输出records。
产生哪些RDD与transformation()的计算逻辑有关,下面讨论一些典型的transformation()及其创建的RDD。官网上已经解
释了每个transformation的含义。iterator(split)的意思是foreachrecordinthepartition。这里空了很多,是因为那些
transformation()较为复杂,会产生多个RDD,具体会在下一节图示出来。
Transformation GeneratedRDDs Compute()
map(func) MappedRDD iterator(split).map(f)
filter(func) FilteredRDD iterator(split).filter(f)
flatMap(func) FlatMappedRDD iterator(split).flatMap(f)
mapPartitions(func) MapPartitionsRDD f(iterator(split))
mapPartitionsWithIndex(func) MapPartitionsRDD f(split.index,iterator(split))
sample(withReplacement,
fraction,seed)
PartitionwiseSampledRDD
PoissonSampler.sample(iterator(split))
BernoulliSampler.sample(iterator(split))
pipe(command,[envVars]) PipedRDD
union(otherDataset)
intersection(otherDataset)
distinct([numTasks]))
groupByKey([numTasks])
reduceByKey(func,
[numTasks])
sortByKey([ascending],
[numTasks])
join(otherDataset,[numTasks])
cogroup(otherDataset,
[numTasks])
cartesian(otherDataset)
coalesce(numPartitions)
repartition(numPartitions)
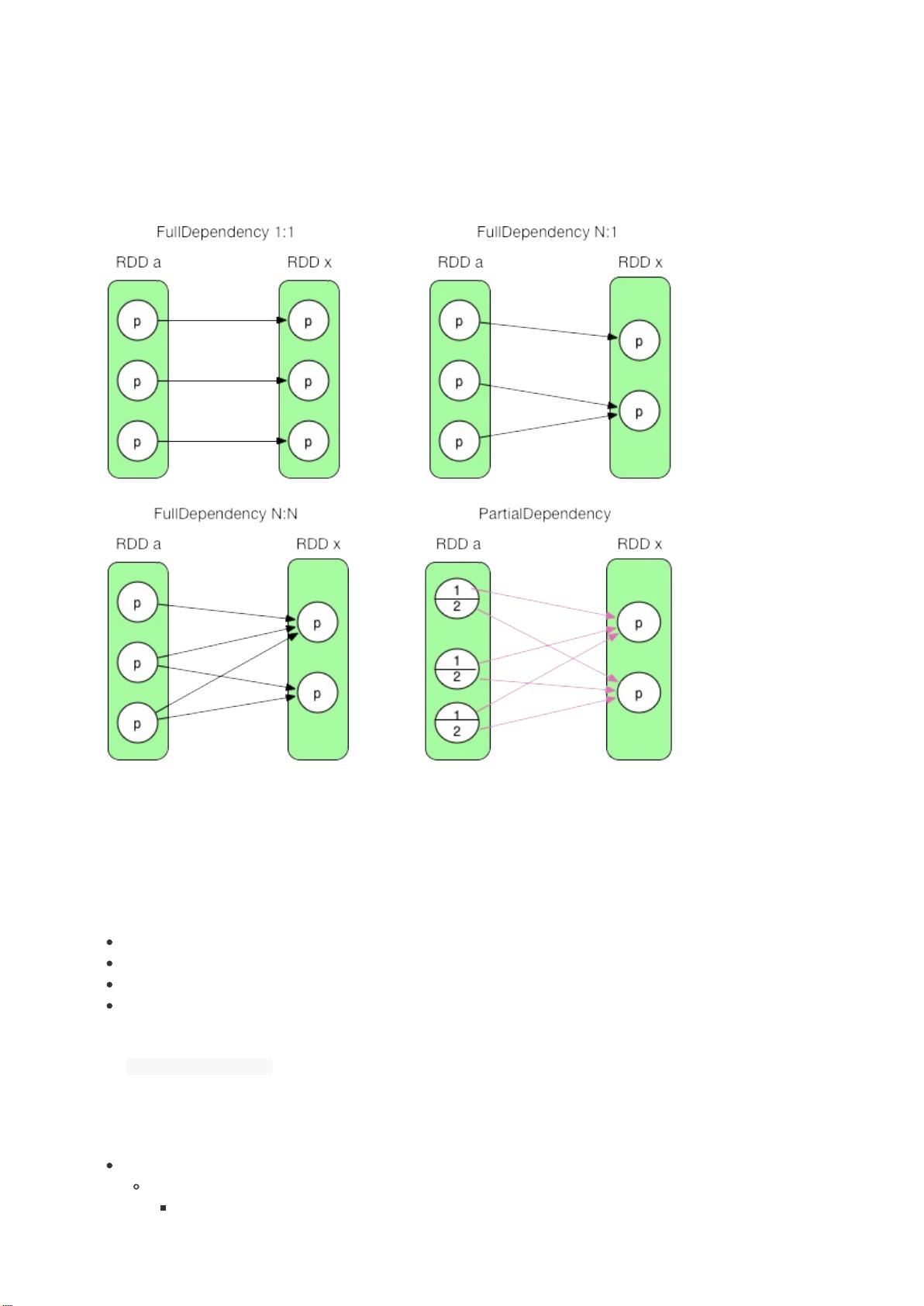
RDD之间的数据依赖问题实际包括三部分:
RDD本身的依赖关系。要生成的RDD(以后用RDDx表示)是依赖一个parentRDD,还是多个parentRDDs?
RDDx中会有多少个partition?
RDDx与其parentRDDs中partition之间是什么依赖关系?是依赖parentRDD中一个还是多个partition?
第一个问题可以很自然的解决,比如
x=rdda.transformation(rddb)(e.g.,x=a.join(b))就表示RDDx同时依赖于RDDa和
RDDb。
第二个问题中的partition个数一般由用户指定,不指定的话一般取
max(numPartitions[parentRDD1],..,
numPartitions[parentRDDn])。
第三个问题比较复杂。需要考虑这个transformation()的语义,不同的transformation()的依赖关系不同。比如map()是
1:1,而groupByKey()逻辑执行图中的ShuffledRDD中的每个partition依赖于parentRDD中所有的partition,还有更复杂
2.如何建立RDD之间的联系?
ApacheSpark的设计与实现
11Job逻辑执行图
本文档由Linux公社 www.linuxidc.com 整理
剩余74页未读,继续阅读
2017-11-22 上传
2019-07-19 上传
2016-02-03 上传
2018-09-06 上传
2019-09-27 上传
2018-12-25 上传
2018-01-22 上传

phphhhp
- 粉丝: 63
- 资源: 65
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
