"Attention模型方法综述-多篇经典论文解读"
需积分: 0 15 浏览量
更新于2024-01-01
收藏 1.85MB PDF 举报
Attention模型是一种在多篇经典论文中被广泛讨论和解读的方法。在这些论文中,研究者对Attention模型的不同结构进行了详细的分析和拆解。首先要简单谈一谈Attention模型的引入。以基于seq2seq模型的机器翻译为例,如果decoder只用encoder最后一个时刻输出的hidden state,可能会有两个问题。1. encoder最后一个hidden state与句子末端词汇的关联较大,难以保留句子起始部分的信息。2. encoder按顺序依次接受输入,可以认为encoder产出的hidden state 包含有词序信息。所以一定程度上decoder的翻译也基本上沿着原始句子的顺序依次进行,但实际中翻译却未必如此。
在关于Attention模型的研究中,一篇14年的文章提出了一种解决以上问题的方法。该方法是在decoder端引入attention机制。简而言之,就是在decoder生成翻译词汇时,通过对encoder所有时刻的hidden state进行加权求和,来获得一个与decoder输入词汇更相关的context向量。这种方法的好处是能够更加充分地利用encoder的信息,并且解决了之前提到的两个问题,所以在接下来的研究中逐渐被广泛应用。
在随后的几年里,在多篇论文中对Attention模型的结构进行了深入研究和拆解。比如,其中一篇论文重点讨论了encoder最后一个hidden state与整个句子的关联,以及如何保留句子起始部分的信息。该论文提出了一种改进的方法,即不仅考虑encoder最后一个hidden state,还可以考虑其他时刻的hidden state,通过一定的权重分配来获取更加全局的信息。这种方法能够更好地保留句子起始部分的信息,并且获得了较好的实验结果。
另外一篇论文的重点研究了encoder按顺序依次接受输入这一问题。该论文指出,虽然encoder产出的hidden state包含有词序信息,但并不意味着decoder的翻译必须像原始句子一样顺序依次进行。为了解决这个问题,该论文提出了一种新的注意力机制,通过引入不同的attention权重,使得decoder在翻译时可以更加灵活地利用encoder的信息,从而获得更加合理的翻译结果。
综上所述,通过对多篇经典论文的解读和分析,我们对Attention模型的不同结构有了更加深入的了解。这些研究不仅帮助我们更好地理解Attention模型的原理,也为其在实际应用中提供了更多的启发和改进思路。在未来的研究中,可以基于这些工作,进一步探索和发展Attention模型,使其在各种自然语言处理任务中发挥更加重要的作用。
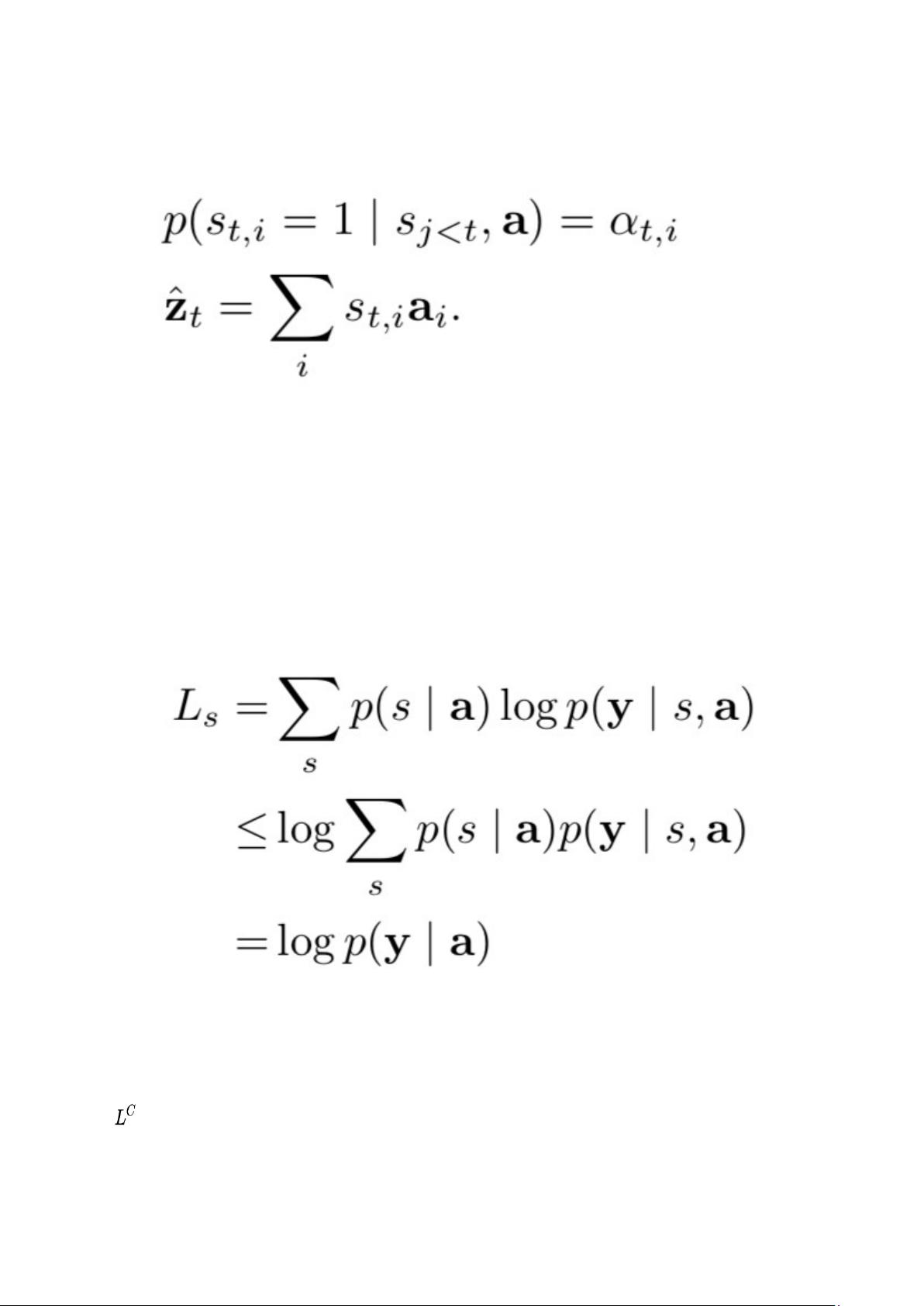
attention 每次只 focus 一个位置的做法,就是“hard”称谓的来源。 Zt 也就被视为一个变
量,计算如下:
问题是 αti 怎么算呢?把 αti 视为隐变量,研究模型的目标函数,进而研究目标函数对参数的
梯度。直观理解,模型要根据 a=(a1,...,aL) 来生成序列 y=(y1,...,yC) ,所以目标可以是最大化
log p(y|a) ,但这里没有显式的包含 s ,所以作者利用著名的 Jensen 不等式(Jensen's
inequality)对目标函数做了转化,得到了目标函数的一个 lower bound,如下:
这里的 s ={ s1,...,sC },是时间轴上的重点 focus 的序列,理论上这种序列共有
个。 然后就用 log p(y|a) 代替原始的目标函数,对模型的参数 W 算 gradient。
剩余20页未读,继续阅读
2022-08-04 上传
2021-04-02 上传
107 浏览量
Single-Photon-Guided-HDR:各种用于图像分割的Unet模型的实现-Unet,RCNN-Unet,Attention Unet,RCNN-Attention Unet,嵌套Unet
2021-04-03 上传
2022-01-28 上传
2021-09-30 上传
2018-03-22 上传
2022-08-04 上传
2021-05-04 上传

方2郭
- 粉丝: 32
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
