深度学习中的注意力机制解析
版权申诉
60 浏览量
更新于2024-08-08
收藏 5.17MB PDF 举报
"此资源详细介绍了深度学习中的注意力机制在不同场景的应用,包括Seq2Seq模型、图像描述生成和序列分类任务中的应用,以及Transformer和多模态Transformer中的注意力机制。此外,还探讨了注意力机制的一般形式、多头注意力、自注意力与交叉注意力的区别,以及注意力机制的多样性和在当前最先进模型中的重要性。"
在深度学习领域,注意力机制已经成为理解和解决复杂问题的关键工具,尤其是在处理序列数据时。这篇文档首先提到了Seq2Seq模型中的第一个注意力机制,这是在2015年Bahdanau等人提出的机器翻译任务中的创新。在Seq2Seq模型中,解码器的每个步骤都会通过加权求和的方式利用编码器的隐藏状态来创建一个上下文向量,这种方法能帮助模型在生成目标序列时关注源序列的重要部分。
接着,文档介绍了注意力机制在图像描述生成任务中的应用。在这种情况下,编码器是视觉编码器,它将图像信息转化为隐藏状态,然后注意力机制同样会根据这些隐藏状态生成权重,以决定在生成描述时对图像的不同区域给予的关注度。
对于序列分类任务,文档指出注意力机制可以利用序列的最后一个隐藏状态作为查询向量,计算对所有编码器隐藏状态的注意力权重。这样,模型能够聚焦于序列中的关键信息,而不是仅仅依赖全局或局部的固定表示。
文档还详细讨论了一般化的注意力机制公式A(Q, K, V)到输出O的过程,其中Q代表查询向量,K是键向量,V是值向量。这个公式是注意力机制的核心,用于计算不同位置的注意力权重。
多头注意力是Transformer模型中的一个重要概念,它允许模型同时从多个不同的“视角”来捕捉信息,提高了模型的表达能力。自注意力和交叉注意力则分别用于在同一序列内部和不同序列之间建立联系,自注意力在Transformer中用于理解序列内部的相互关系,而交叉注意力则在编码器和解码器间传递信息。
最后,文档强调了注意力机制的多样性和灵活性,它们不仅推动了机器翻译、图像描述和序列分类等任务的性能提升,还在当前最先进的模型中扮演着核心角色,如BERT、GPT等。这份资料深入浅出地阐述了注意力机制在深度学习中的各种应用和原理,对于理解这一重要概念及其在实际问题中的应用具有很高的价值。
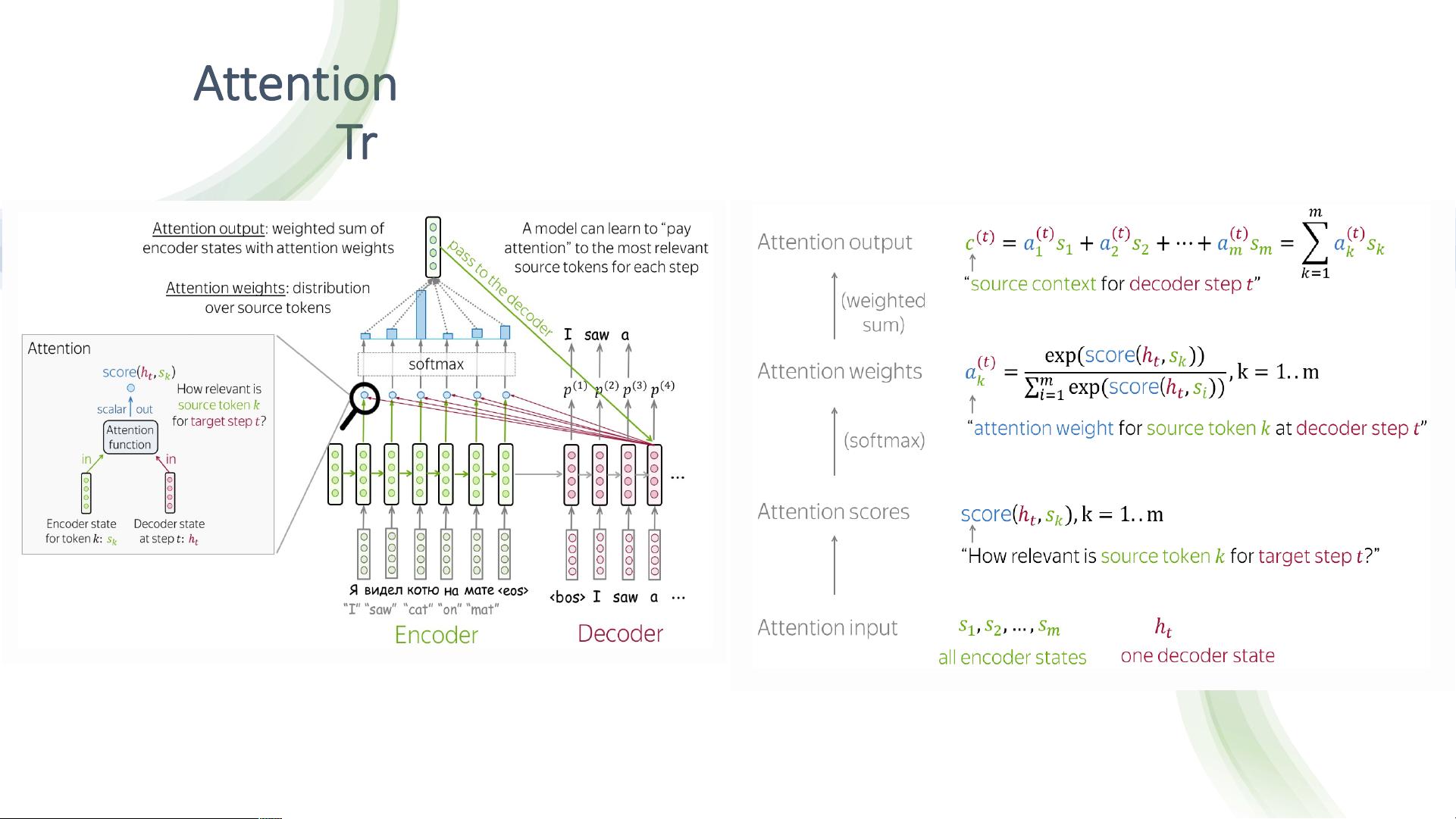
Attention Mechanism first proposed for Machine
Translation in Bahdanau et al., 2015
At each decoder step, Attention mechanism will create a context vector as a weighted sum on encoder hidden states
剩余12页未读,继续阅读
2022-03-30 上传
2019-09-09 上传
2021-09-23 上传
2023-08-23 上传
2023-05-25 上传
2023-04-07 上传
2024-09-23 上传
2023-05-11 上传
2023-11-10 上传

努力+努力=幸运
- 粉丝: 2
- 资源: 136
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
