Greenplum集群内数据同步方法及性能详解
需积分: 0 140 浏览量
更新于2024-01-30
收藏 1.92MB PDF 举报
Greenplum是一种高性能的分布式数据库解决方案,在使用Greenplum集群的过程中,有时需要在不同的集群之间同步数据。本文将介绍Greenplum不同集群之间同步数据的方法及性能,并给出详细步骤和注意事项。全文将以以下内容展开:
1. 概述:
Greenplum是一种基于PostgreSQL的分布式数据库,它具有高并发性、水平扩展性和强大的数据处理能力。但在实际应用中,有时需要将数据从一个Greenplum集群同步到另一个集群,以满足不同环境或业务需求。
2. 相同集群相同数据库不同SCHEMA之间同步数据:
2.1 查看原始表的大小行数与结构:
在进行数据同步之前,首先需要了解原始表的大小、行数以及表结构。可以使用Greenplum提供的工具或查询系统表来获取这些信息。
2.2 同步语句:
同步数据的方法有多种,可以通过使用INSERT、UPDATE或MERGE语句将数据从源表复制到目标表。根据具体需求和数据规模的大小,选择合适的同步方法。
3. 查看CPU与内存的使用情况:
Greenplum是一个分布式数据库,由多个节点组成。在进行数据同步时,需要关注Master节点的CPU和内存使用情况,确保同步操作不会对整个集群的性能造成过大的影响。
3.1 查看Master CPU与内存使用情况:
使用Greenplum提供的系统视图或命令可以查看Master节点的CPU和内存使用情况。根据实际情况,可以采取相应的优化措施,如调整同步操作的并发度,合理设置资源管理策略等。
4. 数据同步性能优化:
在进行数据同步时,可以通过以下方法来提高同步性能:
- 使用并行加载数据:通过将数据并行加载到目标表中,可以加快数据同步的速度。
- 使用压缩技术:在数据传输过程中使用压缩技术可以减少网络带宽的需求,提高数据同步的效率。
- 合理设置资源管理策略:根据同步操作的特点,合理设置Greenplum的资源管理策略,以充分利用集群资源,提高同步性能。
5. 总结:
Greenplum是一种高性能的分布式数据库解决方案,在进行数据同步时,需要注意合理选择同步方法,关注Master节点的CPU和内存使用情况,并进行性能优化。通过合理的规划和优化,可以实现高效的数据同步,满足不同集群之间数据一致性的需求。
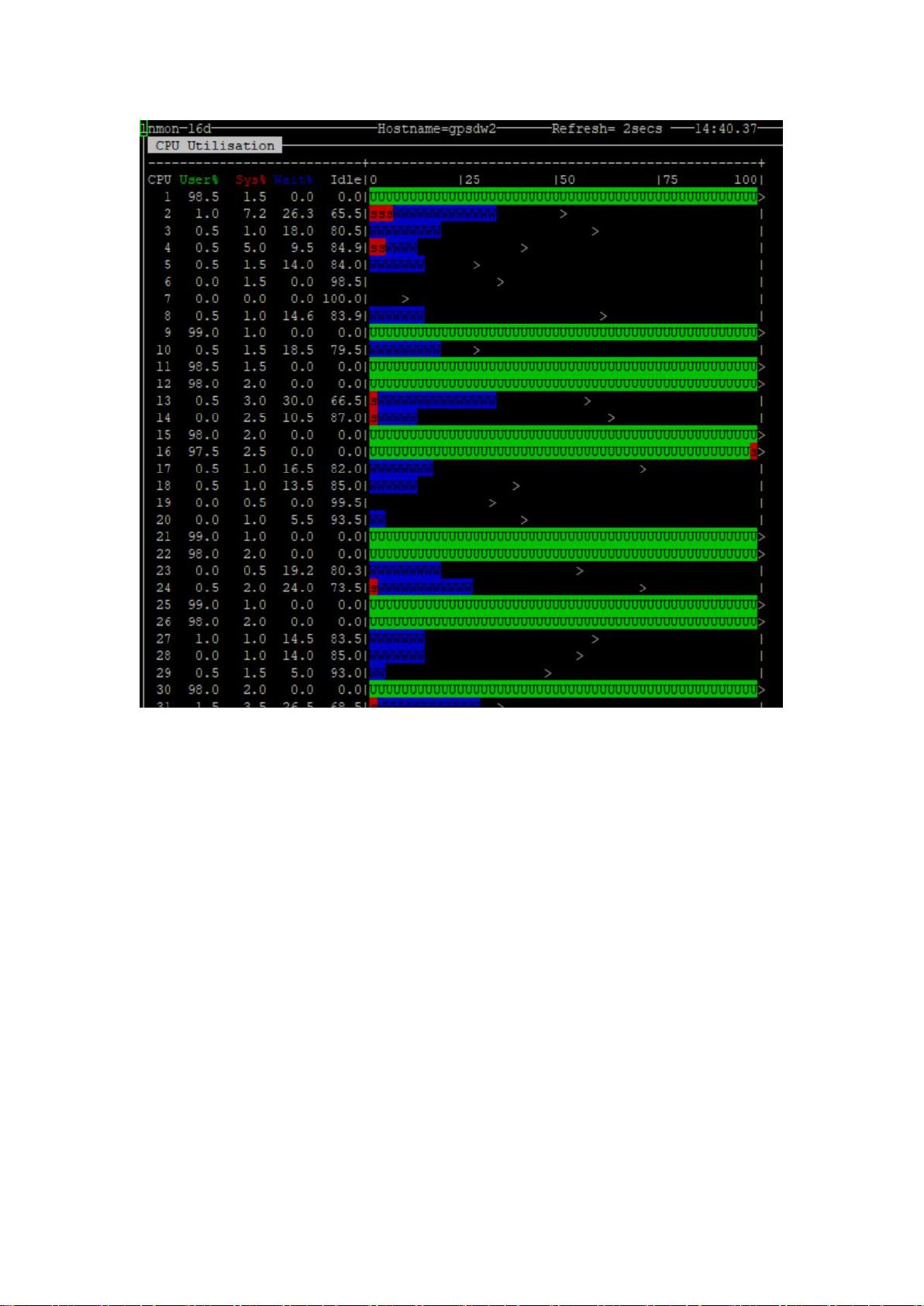
数据节点三使用情况
剩余23页未读,继续阅读
1010 浏览量
点击了解资源详情
2021-10-03 上传
187 浏览量
2021-09-28 上传
118 浏览量
点击了解资源详情
点击了解资源详情

普通网友
- 粉丝: 21
- 资源: 314
 我的内容管理
展开
我的内容管理
展开







最新资源
- bash脚本编写教程
- WSC/ADL:Web Services组合系统体系结构描述语言
- 常用开源软件说明手册
- 高质量c++编程指南
- map reduce by google inc
- bigtable by google inc
- U-BOOT 在S3C2410的移植
- 《计算机组成原理》第一章课件
- Practical Apache Struts 2 Web 2.0 Projects.pdf
- ACM+算法集--常用ACM算法
- 华为电路设计规范,得到很多人的认可
- sq安装步骤,安装问题
- linux下建立DNS
- Arcgis开发宝典
- 是个IC资料 PDF型的
- 办公自动化EXECL(提高操作EXECL的能力)
