Hadoop安装全攻略:从下载到配置环境变量
需积分: 49 22 浏览量
更新于2024-09-09
收藏 222KB DOCX 举报
"这篇教程详细介绍了在Linux环境下安装Hadoop的步骤,包括下载、创建目录、配置环境变量以及设置hosts文件。"
在大数据处理领域,Apache Hadoop是一个关键的开源框架,它允许分布式存储和处理大规模数据集。本教程将引导你完成Hadoop的安装过程,确保你的系统能够正确配置并运行Hadoop服务。
**第一步:Hadoop下载**
Hadoop的安装包下载方式类似于Java Development Kit (JDK) 的下载,可以通过官方Apache网站或第三方博客提供的链接获取。下载完成后,你需要将文件解压到合适的目录,例如 `/root/usr/hadoop`。
**第二步:创建目录**
在Hadoop的安装目录下,你需要创建四个重要的目录:
1. `input` - 存放输入数据的目录。
2. `tmp` - 临时文件存放地,用于Hadoop运行时的中间结果。
3. `dfs/data` - HDFS数据节点的数据存储位置。
4. `dfs/name` - HDFS名称节点的数据存储位置。
确保这些目录已创建,并通过`ls`命令检查。
**第三步:配置环境变量**
在Linux系统中,你需要编辑`/etc/profile`文件来设置Hadoop相关的环境变量。这使得系统知道Hadoop安装的位置以及如何访问其命令。在文件末尾添加以下内容:
```bash
export HADOOP_DEV_HOME=/root/usr/hadoop/hadoop
export PATH=$PATH:$HADOOP_DEV_HOME/bin
export PATH=$PATH:$HADOOP_DEV_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_DEV_HOME}
export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}
export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}
export YARN_HOME=${HADOOP_DEV_HOME}
export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
```
编辑完成后,使用`:wq`保存并退出。执行`source /etc/profile`使改动生效,然后运行`hadoop`命令验证环境变量是否配置成功。
**第四步:查看和配置IP**
使用`ifconfig`命令找出你的主机IP地址,例如192.168.112.1。接下来,你需要编辑`/etc/hosts`文件,将IP地址与主机名对应起来。对于多节点集群,还需要添加其他节点的IP和主机名。例如:
```
192.168.112.1 master
192.168.112.2 slave1
```
完成以上步骤后,你的系统已基本准备好运行Hadoop。然而,为了启动和管理Hadoop服务,还需要配置Hadoop的配置文件(如`core-site.xml`, `hdfs-site.xml`, `yarn-site.xml`等),并根据集群规模设置Master和Slave节点。同时,确保你的系统满足Hadoop的硬件和软件需求,例如Java环境、内存大小等。
Hadoop的安装和配置可能涉及许多细节,但遵循上述步骤,你将能够建立一个基本的单节点Hadoop环境。对于生产环境或更大规模的集群,建议查阅更详细的文档和最佳实践,以确保稳定性和性能。
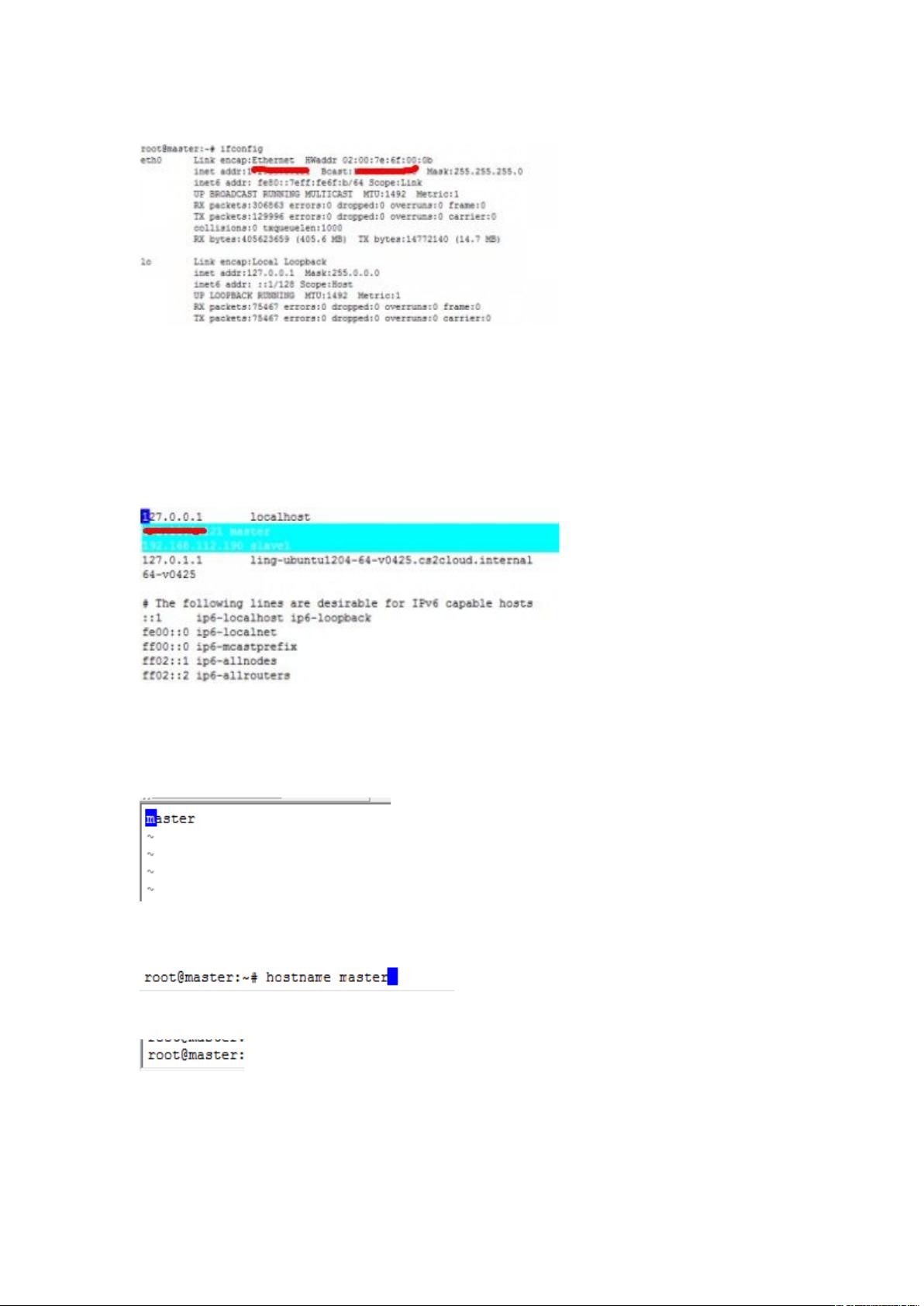
然后输入 5 命令 查看本机的
第一条红线就是本机的 比如是 67896:;966896
下面我们进入 文件添加进去
输入
按键 (表示输入 ,然后添加(下面只添加了 一台阶机器,可以在添加一个
6,形式例如 67896:;966898)如下图
67896:;966896
67896:;966898
下面我们来修改主机名
输入命令*
按键 (表示输入 ,然后输入 按 键 输入 ( :4) 按回车
退出后 在输入命令
回车执行后 需要在输入命令 +重启电脑后,主机名就改过来了,如下图所示
第五步
下面我们进入 下配置一些文档
我们进入解压后的 文件夹
剩余10页未读,继续阅读
2020-03-02 上传
2016-12-25 上传
2017-11-30 上传
2019-08-27 上传
2024-07-16 上传
2014-06-07 上传

小伙闯天下
- 粉丝: 46
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
