Cassandra详解:从入门到精通
需积分: 9 155 浏览量
更新于2024-07-20
收藏 1.5MB PDF 举报
"Cassandra 学习"
Cassandra是一款分布式、高度可扩展的NoSQL数据库系统,最初由Facebook开发,用于处理大规模的在线日志数据。它由Avinash Lakshman和Prashant Malik设计,并在2008年开源,后来加入了Apache软件基金会,并在2010年成为顶级项目。
### 1. Cassandra简介
Cassandra的设计灵感来源于亚马逊的Dynamo,它采用了分布式数据存储的方式,能够在多台服务器之间进行数据复制,提供高可用性和容错性。Cassandra的主要特点包括线性可扩展性、高并发写入能力以及对最终一致性的支持。
### 2. CAP理论与Cassandra
Cassandra遵循CAP理论,即在一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)中,选择了可用性和分区容忍性,牺牲了一致性。这意味着在分布式环境中,Cassandra可以保证数据的可用性,即使部分节点出现故障,系统仍能继续工作。
### 3. 数据模型与CQL
Cassandra的数据模型基于列族(Column Family),现在称为表(Table)。它使用Cassandra Query Language (CQL)进行查询,类似于SQL,但针对分布式环境进行了优化。CQL提供了易于理解和使用的接口来操作数据。
### 4. 数据复制
Cassandra使用不同的分区策略(Partitioner)进行数据分布,例如 Murmur3Partitioner 或 RandomPartitioner。数据复制是通过复制因子(Replication Factor)来配置的,它定义了每个数据块的副本数量。复制策略可以在集群间动态调整,以适应网络拓扑或可用性的变化。
### 5. 发展与维护
Cassandra社区活跃,不断进行版本迭代和功能增强。例如,从0.6版本开始,它添加了集成缓存和支持Apache Hadoop MapReduce的功能。
### 6. 缓存策略
Cassandra支持内置缓存,包括Key Cache和Row Cache,以提高读取性能。用户可以根据应用需求调整缓存大小和策略。
### 7. 客户端请求
- **连接**:客户端可以连接到任何节点,Cassandra的Gossip协议会自动处理节点发现和路由。
- **写请求**:写操作通常先写入内存,然后异步写入磁盘,以实现高性能。
- **读请求**:读操作可以从最近的副本获取数据,也可以根据一致性级别设置从主副本读取。
Cassandra是一种适合大数据场景的数据库解决方案,尤其在需要处理海量数据、高并发写入、以及对数据可用性和容错性有较高要求的应用中表现优异。其设计原理和操作机制对于理解分布式系统的运作至关重要。
Cassandta构说节 Cassandra动环说库节
间进发发员员过发为节对
户
Cassandrareplication节说
节发节还Replication设间进
设间间
1
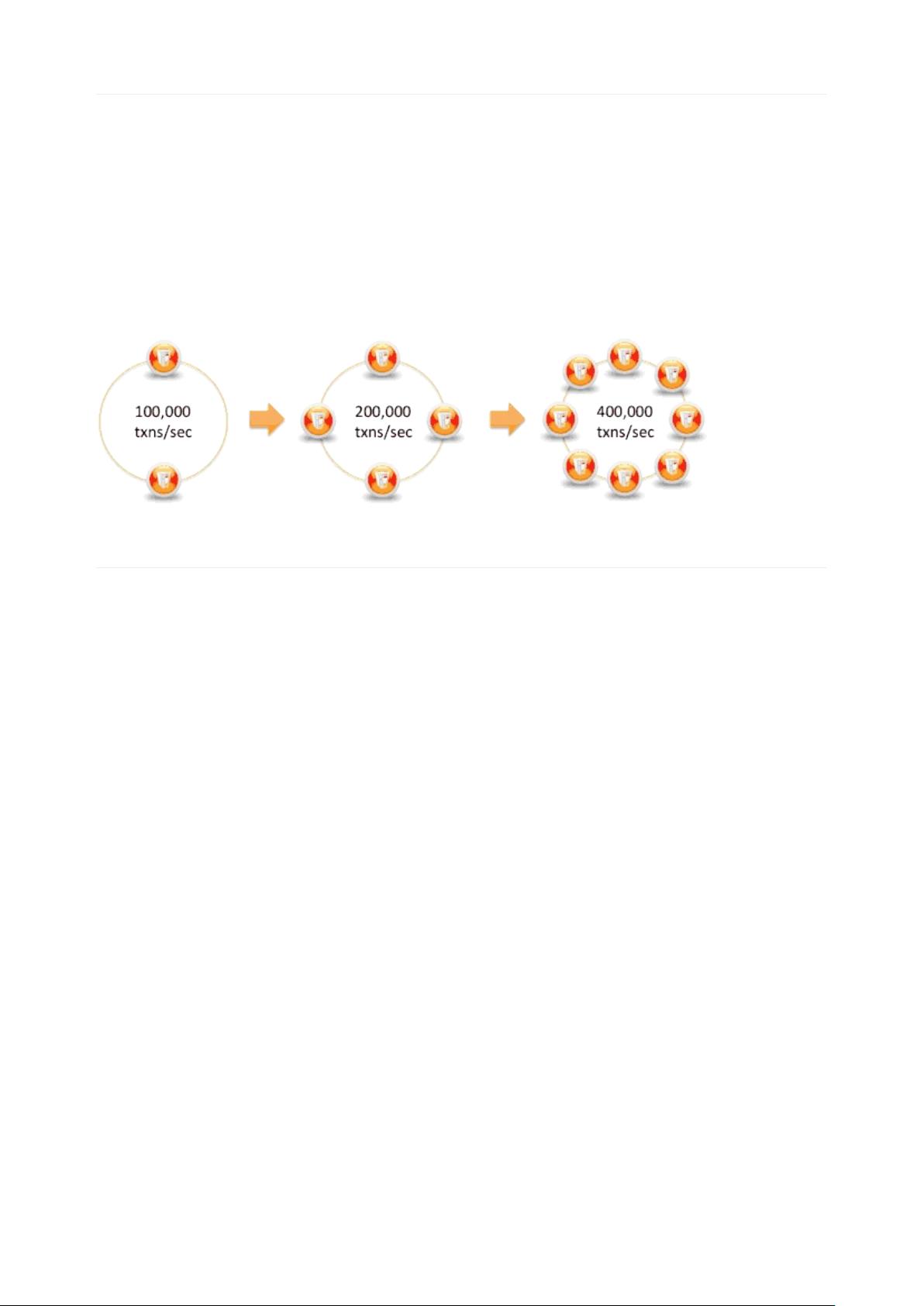
Cassandra线扩说简单线节处2节
处100,000务4节处200,000务8节处400,000务
1. http://www.datastax.com/documentation/cassandra/2.0/cassandra/gettingStartedCassandraIntro.html
Cassandra
剩余33页未读,继续阅读
133 浏览量
176 浏览量
点击了解资源详情
144 浏览量
272 浏览量
2016-05-25 上传
2021-03-18 上传
191 浏览量
238 浏览量

sycyjl7146
- 粉丝: 1
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- E.rar_clamped inverter_e inverter_three level inverter_三电平电路_二极管
- images:图片
- apkUpdate:基于jfinal框架实现的一个APK更新系统
- .doom.d
- html5小鸟快飞游戏源码下载
- OlegMolchnovTutorial:追随
- 运行智能
- 非常实用的html5实现问答系统源码下载
- FennecBot
- 算法,算法工程师,matlab
- HibernateJPA_HerenciaSingleTable:简单表映射
- 通道打包:将纹理打包到图像RGBA通道中的软件
- eclipse中的hibernate插件
- find-home-ui
- AlphaTcl-开源
- 行业文档-设计装置-一种带通气孔的包装纸箱.zip
