Hadoop与Spark大数据处理实战:算法与工具解析
"数据算法--Hadoop-Spark大数据处理技巧,由Mahmoud Parsian撰写,由O'Reilly Media, Inc.出版,发布于2015年2月15日,ISBN号9781491906187。这本书详细介绍了如何使用Hadoop和Spark构建MapReduce应用程序,以处理大规模数据集,如吉字节、太字节或拍字节的数据在商品硬件集群上。书中涵盖了机器学习算法,如朴素贝叶斯和马尔科夫链,并通过MapReduce设计模式展示了如何将这些算法应用于临床和生物学数据。"
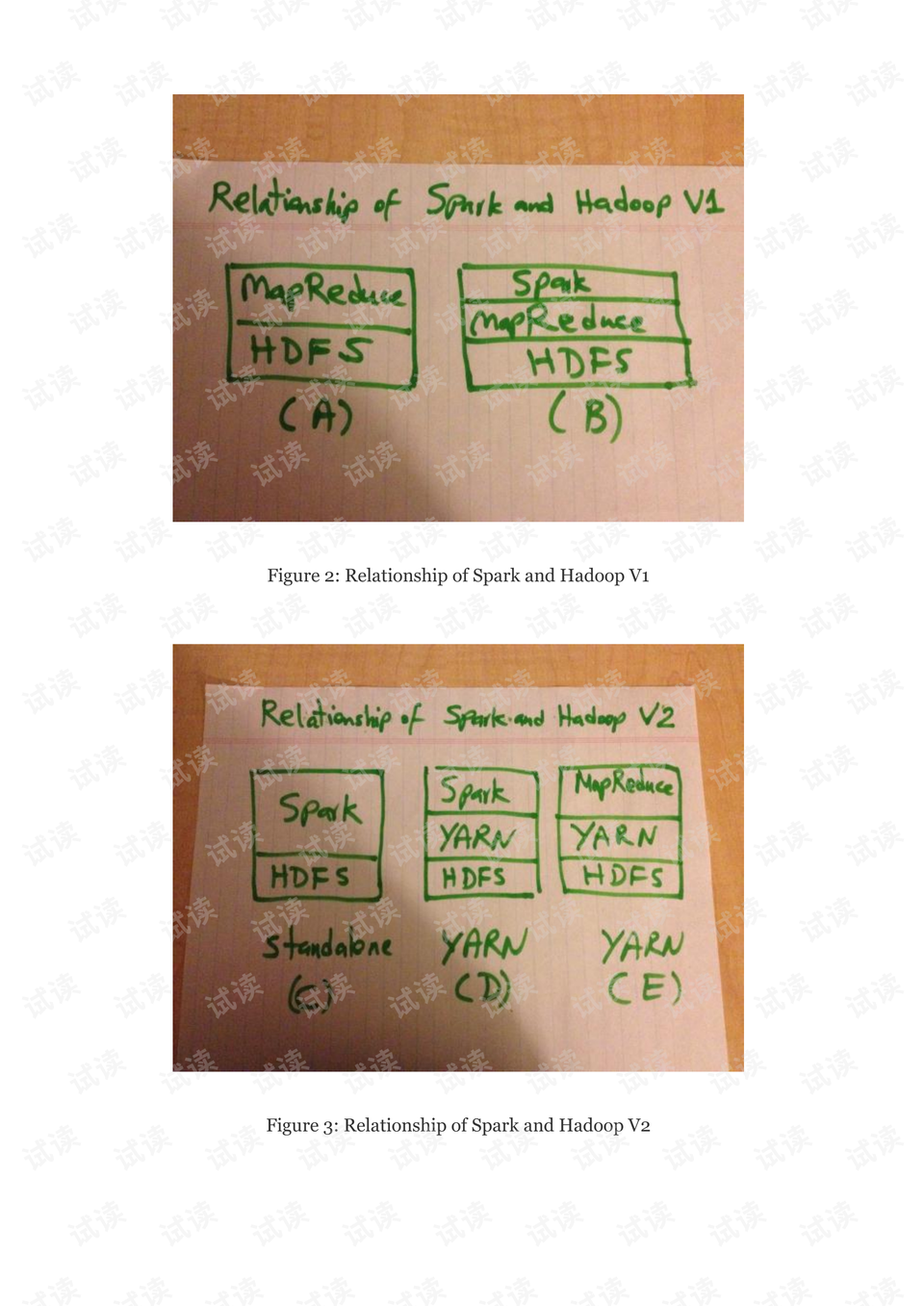
在"数据算法--Hadoop-Spark大数据处理技巧"这本书中,作者Mahmoud Parsian深入浅出地介绍了大数据处理的关键技术。首先,书中的"0.2 Relationship of Spark and Hadoop"章节探讨了Spark与Hadoop的关系,这两个工具都是大数据处理领域的重要组件。Hadoop以其分布式文件系统(HDFS)和MapReduce计算模型为基础,而Spark则以其内存计算和DAG执行模型提高了数据处理速度。
"0.3 What is MapReduce?"章节详细解释了MapReduce的概念,这是一种用于大规模数据处理的编程模型,由Google提出。Map阶段将数据分割并并行处理,Reduce阶段则聚合结果,使得大规模数据的处理变得更加高效。
"0.4 Why use MapReduce?"这一部分讨论了MapReduce在大数据处理中的优势,例如其可扩展性、容错性和适用于批处理的特点。MapReduce使得在普通硬件集群上处理海量数据成为可能。
在"0.6 What Is in This Book?"和"0.7 What Is the Focus of This Book?"章节中,作者明确指出本书的重点是设计和实现机器学习算法,特别是针对Hadoop和Spark平台。这些算法包括但不限于朴素贝叶斯分类器和马尔科夫链,它们在预测分析和模式识别等领域有着广泛的应用。
"0.10 Who Is This Book For?"章节明确了读者群体,主要是对大数据处理有兴趣,尤其是希望使用Hadoop和Spark进行数据分析和挖掘的开发人员和数据科学家。
"0.11 What Software Is Used in This Book?"章节列出了本书涉及的软件工具,包括Hadoop和Spark,以及可能用到的相关生态系统组件。
此外,"0.12 Using Code Examples"章节强调了书中通过实例代码来教授概念的方式,帮助读者更好地理解和应用所学知识。
最后,"0.14 Chapters in This"可能是章节列表的开头,但提供的信息不完整。完整的书目会涵盖更多关于如何使用MapReduce设计模式和Spark优化技巧的内容,以及可能的案例研究和最佳实践。
这本书为大数据处理提供了丰富的理论和实践指导,对于希望提升大数据处理能力的IT专业人士来说是一份宝贵的资源。通过学习书中的算法和工具,读者可以掌握在Hadoop和Spark平台上解决复杂数据问题的能力。




相关推荐







pei_yachao
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 免费教程:Samba 4 1级课程入门指南
- 免费的HomeFtpServer软件:Windows服务器端FTP解决方案
- 实时演示概率分布的闪亮Web应用
- 探索RxJava:使用RxBus实现高效Android事件处理
- Microchip USB转UART转换方案的完整设计教程
- Python编程基础及应用实践教程
- Kendo UI 2013.2.716商业版ASP.NET MVC集成
- 增强版echarts地图:中国七大区至省详细数据解析
- Tooloop-OS:定制化的Ubuntu Server最小多媒体系统
- JavaBridge下载:获取Java.inc与JavaBridge.jar
- Java编写的开源小战争游戏Wargame解析
- C++实现简易SSCOM3.2功能的串口调试工具源码
- Android屏幕旋转问题解决工具:DialogAlchemy
- Linux下的文件共享新工具:Fileshare Applet及其特性介绍
- 高等应用数学问题的matlab求解:318个源程序打包分享
- 2015南大机试:罗马数字转十进制数代码解析
