Windows10+GPU1060环境下YOLOv2车位图像训练与XML标注详解
在进行YOLOv2(You Only Look Once Version 2)模型的训练过程中,首先确保你的开发环境配置得当,如Windows 10操作系统配以NVIDIA GeForce GTX 1060显卡,以及CUDA 7.5和cuDNN 7.5的支持。这种设置对于深度学习框架(如TensorFlow或PyTorch)的高效运行至关重要。
训练样本准备是关键步骤,这里提到的是600张车位图像。为了便于YOLOv2模型识别,你需要使用重命名软件将图片统一命名,如"00000.jpg"、"00001.jpg"等,并创建一个对应的train.txt文件,记录每个图片的标识号,以便模型能够找到对应的标注信息。
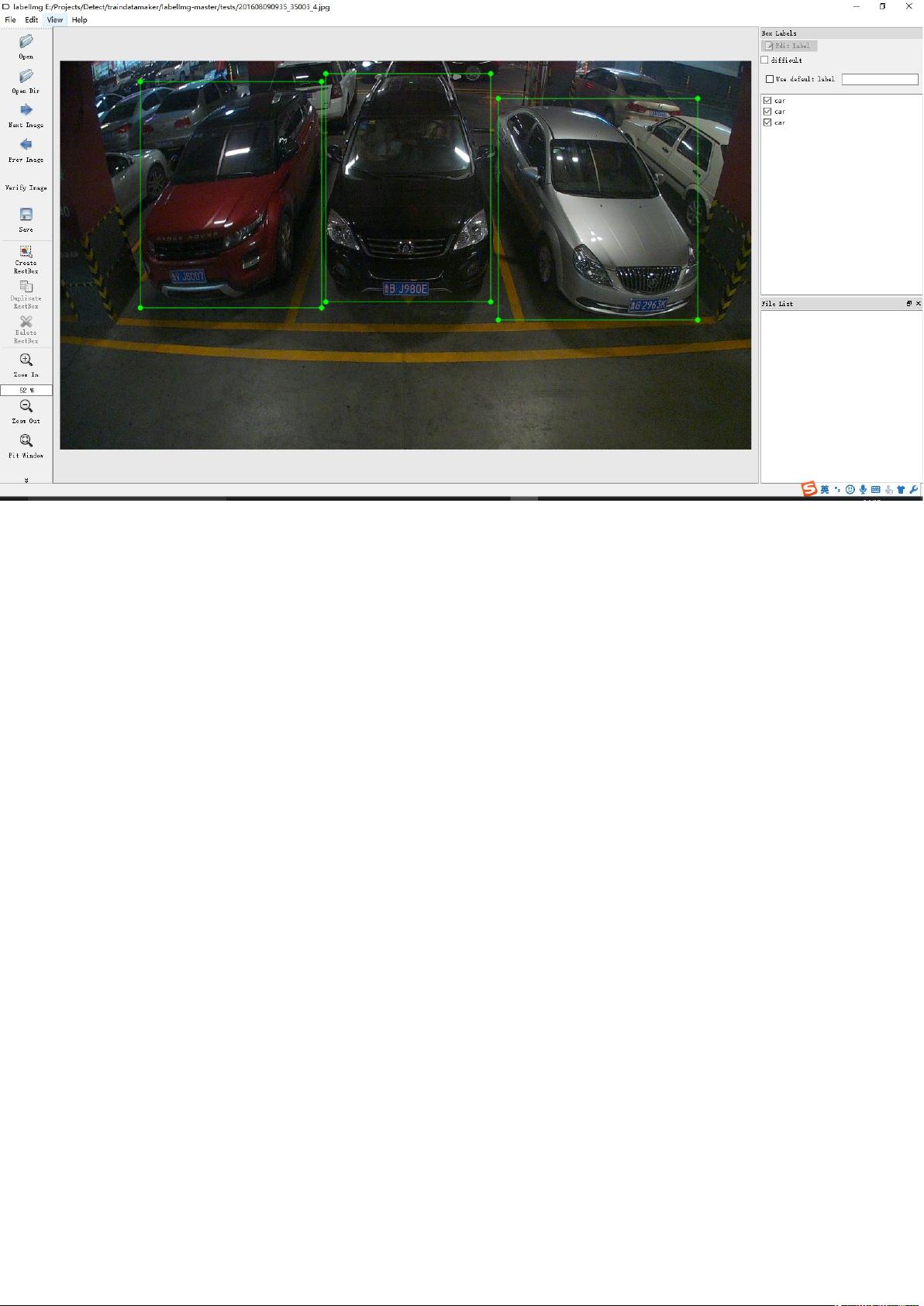
接下来,利用labelImg工具进行图像标注,该工具专用于创建XML文件,它是YOLOv2模型训练中所需的目标检测数据格式。例如,一个XML文件可能包含以下部分:
- `<annotation>`标签定义了注释信息,`verified="no"`表示未验证。
- `<folder>`标签指示图像所在的文件夹路径。
- `<filename>`标签记录图片的实际名称,如"00000.jpg"。
- `<path>`标签提供了图片的完整路径。
- `<source>`标签包含数据来源信息。
- `<size>`标签描述了图像的尺寸,包括宽度(2304像素)、高度(1296像素)和颜色深度(3通道)。
- `<segmented>`标签通常为0,表示图像没有被分割。
- `<object>`标签用于描述图像中的目标物体:
- `<name>`字段指定对象类别,这里是"car"。
- `<pose>`表示物体的姿态,这里默认为"Unspecified"。
- `<truncated>`标记物体是否被裁剪,0表示完整。
- `<difficult>`表示物体是否难以检测,0表示容易。
- `<bndbox>`包含了物体的边界框信息,包括x和y轴上的最小和最大坐标(例如,第一个车的边界框是(xmin=267, ymin=69, xmax=871, ymax=823))。
这些XML文件将作为训练数据的一部分,供YOLOv2模型学习车辆类别的位置和特征。在完成标注后,你需要将这些带有XML标签的图像和相应的train.txt文件一起输入到YOLOv2的训练流程中,通过调整超参数、设置学习率等,执行反向传播优化,最终训练出一个能够准确识别车辆的模型。注意,为了获得良好的性能,可能需要对数据进行预处理,如归一化、数据增强等,并进行多次迭代训练。
环境:
训练样本: 张车位图像,
、先用重命名软件,将图像命名为 , 形式,这
是会生成 文件
内容为图像标号,不带,这个留着放到后面
、然后用 ! 工具截车辆和人,只有两类
上图截了三辆车,完成后生成 ! 文件如下有三个
"#$%&''(
")("*)(
"%!("*%!(
"+(,-*.**!/* !0!**
"*+(
"(
"(/"*(
"*(
"1(
"+(23"*+(
"++(4"*++(
"+(2"*+(
下载后可阅读完整内容,剩余6页未读,立即下载
2018-03-21 上传
2021-02-09 上传
2021-06-30 上传
2024-08-24 上传
2021-10-05 上传
2021-05-05 上传
2021-05-11 上传

浅浅_mo
- 粉丝: 14
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







